b'\xe6\x9c\xac\xe6\x9c\x9f\xe5\x85\xb1\xe6\x9c\x89 43 \xe4\xb8\xaa\xe9\xa1\xb9\xe7\x9b\xae\xef\xbc\x8c\xe5\x8c\x85\xe5\x90\xab C \xe9\xa1\xb9\xe7\x9b\xae (2)\xef\xbc\x8cC# \xe9\xa1\xb9\xe7\x9b\xae (3)\xef\xbc\x8cC++ \xe9\xa1\xb9\xe7\x9b\xae (2)\xef\xbc\x8cGo \xe9\xa1\xb9\xe7\x9b\xae (4)\xef\xbc\x8cJava \xe9\xa1\xb9\xe7\x9b\xae (2)\xef\xbc\x8cJavaScript \xe9\xa1\xb9\xe7\x9b\xae (5)\xef\xbc\x8cKotlin \xe9\xa1\xb9\xe7\x9b\xae (1)\xef\xbc\x8cPHP \xe9\xa1\xb9\xe7\x9b\xae (1)\xef\xbc\x8cPython \xe9\xa1\xb9\xe7\x9b\xae (5)\xef\xbc\x8cRust \xe9\xa1\xb9\xe7\x9b\xae (3)\xef\xbc\x8cSwift \xe9\xa1\xb9\xe7\x9b\xae (2)\xef\xbc\x8c\xe4\xba\xba\xe5\xb7\xa5\xe6\x99\xba\xe8\x83\xbd (5)\xef\xbc\x8c\xe5\x85\xb6\xe5\xae\x83 (5)\xef\xbc\x8c\xe5\xbc\x80\xe6\xba\x90\xe4\xb9\xa6\xe7\xb1\x8d (3)'
January 31, 2025
hackernews
juejin frontend
Expo 框架开发移动应用
React Native 是一个基于 JavaScript 的开源框架,支持使用一套代码构建 iOS 、Android 和 Web 应用。Expo 则是围绕 React Native 构建的一套工具和服务,提供了一种更简便的开发体验。
核心对比
| 特性 | React Native CLI | Expo |
|---|---|---|
| 学习曲线 | 较陡,需要配置 Xcode 或 Android Studio | 平缓,使用 Expo Go 即可快速启动 |
| 项目启动速度 | 慢,需要较多依赖安装 | 快,仅需 Node.js 和手机或模拟器 |
| 社区支持和扩展性 | 强,自由配置 | 强,但受限于 Expo 生态 |
| 构建和打包 | 手动配置 | 提供托管的打包服务 |
| 原生模块支持 | 灵活,但需要手动集成 | 有限,但支持 EAS (Expo Application Services) 解决方案 |
适用场景
- React Native CLI:适合有移动开发经验或对原生模块有较高定制化需求的开发者。
- Expo:更适合快速构建 MVP(Minimum Viable Product)或移动开发新手。
搭建 Expo 项目
创建项目
使用以下命令快速创建一个 Expo 项目:
create-expo-app expo-app --template blank
创建项目后,进入项目目录并安装web依赖:
cd expo-app
npx expo install react-dom react-native-web @expo/metro-runtime
启动开发服务器:
npx expo start
学习文档
- 英文文档 docs.expo.dev/
- 中文文档 expo.nodejs.cn/
NestJs👈 | 前端spring🤔| 项目创建与项目结构解析
NestJs 是一个用于构建高效、可扩展的服务器端应用程序的渐进式 Node.js 框架,
有道是前端的 spring 框架 🤡 ~ (类比 java spring 全家桶👈) , 说是如此说 , 官网已经声明 , 它是仿Angular , AOP 思想很明显 👈
以下从其特点、核心概念、应用场景等方面进行介绍:
官网 : nest.nodejs.cn/
了解 NestJs
特点
- 强大的类型支持:基于 TypeScript 构建,利用 TypeScript 的静态类型检查功能,能在开发阶段提前发现许多潜在错误,提高代码的稳定性和可维护性,同时为开发者提供了更好的代码智能提示和自动完成功能,提升开发效率。
- 依赖注入机制:采用依赖注入模式,使得代码的各个模块之间的依赖关系更加清晰,易于管理和维护。各个模块可以通过依赖注入的方式获取所需的其他模块或服务,降低了模块之间的耦合度,提高了代码的可测试性和可扩展性。
- 丰富的插件生态:拥有大量的第三方插件和库,涵盖了数据库操作、身份验证、文件上传、消息队列等几乎所有常见的后端开发需求。可以方便地与各种数据库(如 MySQL、MongoDB 等)、消息队列系统(如 RabbitMQ、Kafka 等)进行集成。
- 支持多种平台:可以在多种环境中运行,包括服务器端、浏览器端以及移动应用开发中的后端服务等。可以轻松地部署到传统的服务器环境,也可以适应云原生架构,在容器化环境(如 Docker、Kubernetes)中运行。
核心概念
- 模块(Modules) :是 NestJs 应用的基本构建块,用于组织和分组相关的代码。每个模块都有一个明确的职责,可以包含控制器、服务、中间件、守卫等。
- 控制器(Controllers) :主要负责处理 HTTP 请求和响应。它定义了应用的路由路径和对应的处理函数,接收客户端发送的请求,调用相应的服务方法来处理业务逻辑,并将结果返回给客户端。
- 服务(Services) :用于封装具体的业务逻辑。它通常与数据库交互、进行数据处理、调用其他外部服务等。服务可以被控制器或其他服务注入和调用,以实现业务功能的复用。
- 中间件(Middleware) :在请求到达控制器之前或响应返回给客户端之前执行的函数,用于对请求和响应进行预处理或后处理。
- 守卫(Guards) :用于实现身份验证和授权功能。可以在路由级别或控制器级别使用守卫来保护应用的资源,只有通过身份验证和具有相应权限的用户才能访问受保护的路由。
应用场景
- 企业级 Web 应用:适用于构建大型的企业级 Web 应用,能够很好地处理复杂的业务逻辑、大量的用户请求以及与各种后端系统的集成。
- 微服务架构:非常适合用于构建微服务架构的应用,每个微服务可以作为一个独立的 NestJs 应用,通过 HTTP、gRPC 等通信方式进行交互。
- 实时应用:可以与 WebSocket 等技术结合,用于构建实时应用,如在线聊天、实时数据监控、游戏服务器等。
- 移动应用后端:为移动应用提供稳定、高效的后端支持,处理用户注册登录、数据存储和查询、推送通知等业务逻辑。
对比
优势
- 与JavaScript生态深度融合:NestJs基于JavaScript/TypeScript,能和前端技术栈无缝衔接,全栈开发时可共享代码逻辑与数据模型,减少开发和沟通成本,这方面Java集成相对复杂;和Python相比,NestJs构建前后端一体化应用更便捷,能更好利用前端JavaScript优势。
- 轻量级与快速开发:NestJs轻量级、启动快、开发效率高,适合快速迭代的中小型项目,比Java相对更轻便、配置启动更简单;在Web开发中,其架构清晰、代码组织规范,相比Python的Flask等框架,构建大型项目时更易维护和扩展。
- 基于依赖注入的可测试性:NestJs依赖注入机制和JavaScript模块化系统结合紧密,代码可测试性更高,测试代码编写更简洁直观,Java测试代码相对冗长;相比Python,NestJs的依赖注入框架更利于单元和集成测试,能提升代码质量和稳定性。
劣势
- 性能方面:处理高并发、大规模数据和复杂业务逻辑时,Java性能优势明显,其JVM优化成熟,内存管理和垃圾回收高效,NestJs可能存在性能瓶颈;在数据科学和数值计算领域,Python有高性能库,NestJs不适合这类复杂计算任务。
- 技术生态和成熟度:Java技术生态成熟,有Java EE体系和大量开源框架,解决方案完备,NestJs技术生态较新,复杂场景解决方案不够成熟;Python在数据科学、人工智能等领域优势显著,有丰富库和框架,NestJs在这方面不及Python。
- 人才储备和社区支持:Java社区庞大活跃,开发者众多,企业招聘容易,NestJs社区活跃度和人才数量较少;Python社区活跃,开源项目和库丰富,人才市场上Python开发者数量增长迅速,NestJs在这方面处于劣势。
初始化
1. 安装 Nest CLI
Nest CLI 是一个强大的命令行工具,可以帮助你快速创建和管理 Nest.js 项目。你可以通过 npm 全局安装 Nest CLI:
npm install -g @nestjs/cli
3. 创建新项目
使用 Nest CLI 创建一个新的 Nest.js 项目非常简单。你只需要运行以下命令:
nest new project-name
在这里,将 project-name 替换为你的项目名称。运行该命令后,CLI 会提示你选择包管理器(npm 或 yarn),选择你喜欢的包管理器,然后 CLI 会自动为你安装项目依赖。
4. 运行项目
进入项目目录并启动开发服务器:
cd project-name
npm run start
默认情况下,Nest.js 应用会在 http://localhost:3000上运行
项目结构
项目成功初始化后 , 项目结构如下 :
以下是对该NestJS项目结构中各文件及文件夹作用的详细解析:
文件夹
dist:存放编译后的文件。NestJS项目常使用TypeScript编写,该目录是TypeScript代码经编译转化为JavaScript后的输出位置。在项目运行时,实际执行的是此目录下的代码。node_modules:用于存储项目所依赖的第三方包。开发过程中用到的各类NestJS相关模块、工具库等,比如处理HTTP请求的库、数据库连接库、各种辅助功能的插件等,都会被安装到这个目录中。src:项目的核心源代码目录,包含了应用的主要业务逻辑、模块定义、控制器、服务等关键代码。开发者主要在此目录下进行功能开发工作,例如创建新的模块来处理特定业务场景、编写控制器以处理客户端请求、编写服务来实现具体的业务逻辑等。test:专门用于存放测试代码的目录。在这里可以编写单元测试、集成测试等各种类型的测试用例,目的是确保项目代码的质量和稳定性,验证各个功能模块是否能够按照预期正常工作。
src目录下的文件
app.controller.spec.ts:这是app.controller.ts对应的测试文件。通常用于编写针对AppController的单元测试或集成测试用例,以验证AppController中各个方法的功能是否正确,比如检查控制器对不同请求的响应是否符合预期等。app.controller.ts:定义了应用的控制器(Controller)。控制器负责处理传入的HTTP请求,并返回相应的响应。它通常包含多个处理不同路由的方法,这些方法会调用对应的服务来获取数据或执行特定的业务逻辑,然后将处理结果返回给客户端。app.module.ts:应用的根模块(Module)文件。在NestJS中,模块是组织代码的基本单元,它可以将相关的控制器、服务、组件等组合在一起,管理它们的生命周期和依赖关系。AppModule通常会导入应用所需的其他模块,并声明本模块中使用的控制器、服务等。app.service.ts:定义了应用的服务(Service)。服务用于封装具体的业务逻辑,控制器会调用服务中的方法来完成特定的业务操作,例如数据的获取、处理和存储等。服务可以被多个控制器共享,有助于提高代码的复用性和可维护性。main.ts:应用的入口文件。它负责引导NestJS应用的启动,通常会创建Nest应用实例,导入根模块(如AppModule),并启动HTTP服务器来监听指定的端口,使应用能够接收和处理客户端的请求。
其他配置及说明文件
.eslintrc.js:ESLint的配置文件。ESLint是一个代码检查工具,此文件用于定义项目的代码规范和风格,例如缩进规则、变量命名规范、代码语法检查等。通过配置ESLint,可以帮助开发者保持代码风格的一致性,及时发现和修复代码中的潜在问题。.gitignore:Git版本控制系统的忽略文件。用于指定哪些文件或目录不需要被Git跟踪,例如node_modules目录(因为其体积较大且可以通过package - json重新生成)、编译后的dist目录等。这样可以避免将不必要的文件提交到代码仓库中。.prettierrc:Prettier的配置文件。Prettier是一个代码格式化工具,该文件用于配置代码格式化的规则,比如代码的缩进方式、换行规则、引号类型等。配置好后,代码在保存时会自动按照设定的格式进行调整,使代码更加美观和易读。nest - cli.json:NestJS命令行工具的配置文件。用于配置NestJS CLI(Command - Line Interface)的相关参数,例如生成代码时的默认路径、模板等。借助这个配置文件,开发者可以更方便地使用命令行快速生成模块、控制器、服务等代码结构。package - lock.json:记录了node_modules中每个包的确切版本信息。它的作用是确保团队成员在安装依赖包时,能够安装到与项目开发者完全相同版本的包,避免因依赖包版本差异而导致的问题。package.json:项目的核心配置文件。其中包含了项目的元数据信息,如项目名称、版本、作者等;还记录了项目的依赖关系,dependencies字段记录生产环境下所需的依赖包,devDependencies字段记录开发环境下所需的依赖包;此外,还可以定义各种脚本命令,例如启动项目、运行测试等。README.md:项目的说明文档。通常会包含项目的介绍、安装步骤、使用方法、示例代码等信息,目的是帮助其他开发者快速了解和使用该项目。tsconfig.build.json:可能是用于项目构建时的TypeScript配置文件。它与项目的编译过程相关,可以指定一些编译选项,比如目标JavaScript版本、模块解析策略、路径映射等,以满足特定的构建需求。tsconfig.json:项目整体的TypeScript配置文件。定义了TypeScript编译的各种选项,例如include字段指定哪些文件或目录需要被包含在编译范围内,exclude字段指定哪些需要被排除,compilerOptions中则定义了类型检查、模块系统、严格模式等众多编译相关的设置。
强迫症: 暂时关掉语法检查
开始可能会因为语法检查爆红 , 可以在.eslintrc.js 中暂时注释掉一下代码 :
玩耍
在浏览器中访问http://localhost:3000
我们一起找一下问什么返回 Hello world
找到 Controller 层
顺着他找到在 Service 层的 getHello
这里就是返回的结果 , 其实 NestJs 有着前端 spring 之称呼 , 看到这里 , 让人不禁想起 javaweb 中的经典三层架构用于分层解耦
总结
临时起意 , 看到 NestJs , 初始化一个 nest-start-demo 玩玩 , 之后会深入学习 ~ , 从基础到实战 !
juejin career
游大唐秦王陵——一个新晋研发管理者的随想
前言
本来上传了很多图片,但是文章一直无法保存,无奈只能删减到仅存两张。
此时正值隆冬时节,零下几度的寒风裹挟着细碎的尘土,在古老的秦王陵间来回穿梭。
站在大唐秦王陵地宫的阙楼前,日光将古老的青砖染上一层柔和的金色,在地面投下规则的菱形阴影。
这座沉睡千年的五代十国遗迹,此刻正以某种奇特的频率,与我这个恰逢而立之年的新晋技术管理者似乎产生着共振。
地宫甬道
随着步入地宫深处,手机信号逐渐消失的那一刻,青砖甬道将人推入异样的静谧,反而让我感受到了一种莫名的释然。
青砖墙壁上斑驳的壁画在幽暗中若隐若现。
这座全长117米的斜坡墓道,竟暗合现代系统的分层设计理念:
- 地表阙楼是用户界面
- 墓室是核心数据库
- 七层青砖穹顶恰如安全防护层
五代工匠用实体空间构建的这套“系统”,竟与现代软件架构有着惊人的相似。
那些千年未移位的砖块边缘,还残留着墨斗弹线的淡痕。
没有CAD的年代,匠人们用鱼鳔胶与鲁班尺完成的误差控制,比我们写在飞书上的开发规范更接近本质。
或许真正的代码优雅,本就不需要各种工单、各种DDL的催逼,而是源于对事物本源的参悟。
榫卯
李夫人墓的唐代端楼令我震撼的不仅是它的完整度。
2871个木构件不用一根铁钉的组合方式,像极了我们追求的模块化开发理念。
每个斗拱单元都是独立的功能模块,通过标准接口(榫卯)实现无限组合。
这不正是我们推崇的“高内聚、低耦合”设计理念在古代建筑中的完美呈现吗?
当导游讲解“一材三契”的古代模数体系时,我突然意识到当下团队里缺失的,正是这种穿越千年的标准化基因——就像端楼工匠用“材分制”将误差消化在构件榫卯之间,我们的开发规范也该让不同人员的代码像这些木构件般自成韵律。
这或许比在晨会上反复强调更有效。
权力更迭
墓志铭记载李茂贞“三让帝位”的政治智慧,意外解开了我近期管理OKR时的困惑。
五代十国的节度使既要保持军事实力,又要在藩镇间维持微妙平衡。
管理者不也可以想象成混迹在团队里的节度使?
既要保证交付速度,又要维护技术债的平衡。
穹顶壁画《伎乐图》里,箜篌与羯鼓的声部在千年后依然清晰可辨。
研发团队何尝不是需要精准的节奏把控?
前端如琵琶需颗粒分明,后端似编钟贵在沉稳,DevOps则是那支掌控节拍的指挥棒。
感悟
暮色浸透墓室时,一线天光正从盗洞斜射而入。
指尖抚过冰凉的青砖接缝,突然觉得技术管理的真谛或许早就藏在历史褶皱里。
那些关于尺度与平衡、模块与整体、约束与创造的智慧,始终在等待与今人的灵光共振。
也许未来某一天,当另一个工程师站在这里,亲手触碰这些承载千年记忆的砖石,也会读出与我同样的感悟。
跨越千年的智慧,总是相通的。
古人的匠心,在今天依然闪耀。
juejin backend
基于最小堆的定时器主备切换
定时器
总体结构:为一个最小堆,也就是STL中的优先队列,存储定时任务,线程池去定时获取任务并执行
最小堆
任务分为三种:固定时间执行,cron表达式执行,间隔执行,这些定时任务统一加入到最小堆,通过计算下一次执行时间做为key。
typedef std::priority_queue<CSharedPtr<ITaskWrap>, std::vector< CSharedPtr<ITaskWrap> >, Compare> CCronTaskQueue;
struct Compare {
bool operator()(const CSharedPtr<ITaskWrap>& a, const CSharedPtr<ITaskWrap>& b)
{
return a->GetNextTime() > b->GetNextTime();
}
};
下一次执行最近的任务将处于堆顶
任务添加
往最小堆加入定时任务包括三个来源:
- 程序启动加载时,从数据库加载定时任务:定时任务通过脚本维护
- 程序启动中,动态
添加/删除/清空定时任务- 从web端添加定时任务时,只是放入action队列,由定时任务触发器(单线程运行)将这些动作封装成定时任务置入最小堆,并负责最小堆的出堆
- 其他插件动态
添加/删除/清空定时任务,如后面要讲的初始化/主备切换定时任务
long CTimeTrigger::Run()
{
// 1. 将ActionQueue的任务入堆
while (true)
{
CSharedPtr<CCronTaskAction> lpAction = m_ActionQueue.Pop(TIME_TIGGER_CHECK_INTERVAL);
while(lpAction.IsNotNull())
{
if(lpAction->GetAction() == CCronTaskAction::ACTION_ADD)
{
// 创建定时任务,入堆...
}
else if(lpAction->GetAction() == CCronTaskAction::ACTION_REMOVE)
{
// 根据任务id删除定时任务节点...
}
else if(lpAction->GetAction() == CCronTaskAction::ACTION_CLEAR)
{
// 清空定时器...
}
lpAction = m_ActionQueue.PopNoWait();
}
// 2. 将最小堆的定时任务出堆,加入到定时任务线程池的消息队列
time_t iNow = time(NULL);
if(m_CronTaskQueue.size() > 0)
{
CSharedPtr<ITaskWrap> lpTaskWrap = m_CronTaskQueue.top();
while(lpTaskWrap.IsNotNull())
{
// 检测下一次执行时间,触发定时任务...
lpTaskWrap->OnTimer(iNow);
}
}
}
- 定时任务执行后,触发回调下一次继续执行
定时任务线程池
线程池初始化,多个线程从定时任务消息队列取任务
CWorkThreadPool::CWorkThreadPool(ISchedule* lpOwner,const std::string& szThreadPoolName,int iThreadCount)
:m_lpOwner(lpOwner),m_iThreadCount(iThreadCount),m_szThreadPoolName(szThreadPoolName)
{
m_lpQueue = new CBlockingQueue< CSharedPtr<IWorkThreadTask> >(); // 消息队列
for(int i=0; i<m_iThreadCount; i++)
{
std::string szThreadName = szThreadPoolName + "-" + std::to_string((long long) i);
m_Threads.push_back(new CScheduleWorkThread(m_lpOwner,m_lpQueue,i,szThreadName));
}
}
线程池运行:取消息队列任务执行
void CWorkThreadPool::Start()
{
for(int i=0; i<m_iThreadCount; i++)
{
m_Threads[i]->Start();
}
}
// 线程执行体
long CScheduleWorkThread::Run()
{
while(true)
{
CSharedPtr<IWorkThreadTask> lpTask = m_lpQueue->Pop(); // 取消息队列消息
if(lpTask.IsNotNull())
{
try
{
lpTask->Execute(lpTask); // 执行定时任务api
}
catch(IError& e)
{
LogError("运行错误 error_no: " << e.GetErrorNo() << " error_info: " << e.GetErrorMsg());
}
}
}
return 0;
}
执行api,返回错误信息,并计算下一次执行时间将任务再次入堆:
void CLocalScheduleTask::OnProcess(const CSharedPtr<IWorkThreadTask>& lpTask)
{
if(m_iTaskStatus == TASK_STATUS_DISABLE)
{
// 任务状态异常,直接退出...
return;
}
if(m_iStep == STEP_EXEC) // 任务执行
{
// 执行任务,返回错误信息,并计算下一次执行时间将任务再次入堆
ExecTask(lpTask,lpTaskInfo);
Next(STEP_CALLBACK);
}
}
主备切换
主机和备机连接的同一个实体数据库,内存数据库UFTDB通过NFS挂载和redo文件进行实时同步,所以二者的数据是一样的,不一样的是内存中的数据
当主机宕机后,备机成为主机,继续执行定时任务,而主机未执行完成的任务丢弃
框架启动插件加载流程:
- 主线程启动,按照配置文件顺序加载各个插件库文件(so或dll)
- 调用各个插件库文件的OnInit接口进行初始化,一般来说此时各个插件都只有一个主线程运行
- 调用各个插件库文件的OnStart接口进行启动,一般来说此时各个插件的内部线程在此时启动
至此,程序启动时,会调用到定时器的入口函数:
void CScheduleAgentImpl::OnStart(PFOnSetTimeOut pfOnSetTimeOut)
{
if (pfOnSetTimeOut)
pfOnSetTimeOut(5000);
// 向路由插件注册
mf_RegSvr();
m_lpTimeTrigger->Start();
m_lpThreadPool->Start();
// 执行初始化任务
CSharedPtr<CInitTask> lpInitTask = new CInitTask(this);
CSharedPtr<ICronTask> lpCronTask = new CCronTask(this,0,"*/2 * * * * ?",-1,lpInitTask);
AddCronTask(lpCronTask);
// CSharedPtr<CInitTask> lpInitTask = new CInitTask(this);
// m_lpThreadPool->CommitTask(lpInitTask);
printf("schedule_agent started\n");
}
在进行初始化时,会添加一些系统级任务,如初始化、心跳、主备切换定时任务
void CInitTask::OnProcess(const CSharedPtr<IWorkThreadTask>& lpTask)
{
if(m_iStep == STEP_CONNECT_MANAGER)
{
// 定时器插件连接所在节点
}
else if(m_iStep == STEP_REFRESH_CRON_TASK)
{
// 刷新定时任务
RefreshCronTask(lpTask);
}
}
void CInitTask::RefreshCronTask(const CSharedPtr<IWorkThreadTask>& lpTask)
{
CAutoPtr<IESBMessage> lpRsp = GetRspMessage();
if(lpRsp.IsNotNull())
{
int iErrorNo = lpRsp->GetItem(TAG_ERROR_NO)->GetInt();
if(iErrorNo == 0)
{
m_lpOwner->RemoveCronTask(-1);
if (m_lpOwner->IsMaster()) // Master启动心跳任务
{
// 添加心跳任务
CSharedPtr<CHeartBeatTask> lpTask = new CHeartBeatTask(m_lpOwner);
CSharedPtr<ICronTask> lpCronTask = new CCronTask(m_lpOwner, 0, "*/3 * * * * ?", 0, lpTask);
m_lpOwner->AddCronTask(lpCronTask);
}
else
{
// Slave节点开启ChangeMasterTask检查主备切换 3s检查一次状态
LogInfo("定时任务管理器 备机开启主备切换检查");
CSharedPtr<CChangeMasterTask> lpTask = new CChangeMasterTask(m_lpOwner);
CSharedPtr<ICronTask> lpCronTask = new CCronTask(m_lpOwner, 0, "*/3 * * * * ?", -2, lpTask);
m_lpOwner->AddCronTask(lpCronTask);
}
}
}
}
主机执行心跳定时任务,而备机执行主备切换定时任务
void CChangeMasterTask::OnProcess(const CSharedPtr<IWorkThreadTask>& lpTask)
{
if(m_lpOwner->IsMaster()) // 检查当前节点是否是主节点
{
LogInfo("定时任务管理器 主备切换");
// 备机在切换成主机时,需要重新添加主备切换定时任务
m_lpOwner->RemoveCronTask(-2);
CSharedPtr<IWorkThreadTask> lpTask = new CInitTask(m_lpOwner);
CSharedPtr<ICronTask> lpCronTask = new CCronTask(m_lpOwner,0,"*/2 * * * * ?",-1,lpTask);
m_lpOwner->AddCronTask(lpCronTask);
}
Complete();
}
主备切换检测定时任务通过CInitTask::OnProcess第一次触发后,后续的触发逻辑:
在主备正常时:
- 主机会执行心跳的定时任务,保持插件和主机的连接
- 备机会检测是否发生主备切换
在主备切换时:
- 主机宕机,UFTDB将备机设置为主机
- 备机检测自身成为主机,删除主备切换定时任务,通过初始化定时任务添加心跳定时任务,这使得它后续不会再执行主备切换的定时任务了
- 原来的主机重启成为备机后,将执行主备切换定时任务
juejin frontend
Vue3 Openlayers 教程(一)Openlayers 简介与如何使用 Openlayers 地图 加载一副基本的 OSM地图
1. Openlayers 简介
这是一段来自 Openlayers 官网的概述:
💡 OpenLayers 可以轻松地将动态地图放置在任何网页中。它可以显示从任何来源加载的地图瓦片、矢量数据和标记。OpenLayers 的开发是为了进一步使用各种地理信息。它是完全免费的开源 JavaScript,在 2-clause BSD License(也称为 FreeBSD)下发布。简单说明:
Openlayers 是一个用于在网页上显示互动地图的开源 jsvaScript库,可以使用任何来源加载的地图瓦片数据(关于瓦片在文章后面会介绍)。
官网:
Openlayers 官网与文档:
- Openlayers 官网:OpenLayers - Welcome
- Openlayers api 文档: OpenLayers v10.2.1 API - Index
- Openlayers 示例 : OpenLayers Examples
2. Openlayers 安装
使用 npm 命令安装 ol 包
npm install ol // 本文用到的 ol 版本为10.3.1\
3. 创建一个基础的地图与概念说明
简单的地图实例
先看效果图
这是一个非常简单的地图实例,使用了 ol 自带的数据源 OSM 与 EPSG:4326 坐标系。一个地图由地图容器、地图视图、多个地图图层、地图控件、地图标记与交互构成。
这是代码,直接复制到 vue 文件中运行即可看到地图
<template>
<div class="base-map">
<div id="map" style="width: 800px; height: 600px;"></div>
</div>
</template>
<script setup>
import { Map, View } from 'ol';
import TileLayer from 'ol/layer/Tile';
import { OSM, XYZ } from 'ol/source';
import { onMounted } from 'vue';
var map = null;
onMounted(() => {
initMap();
});
function initMap() {
map = new Map({
target: 'map', // 地图容器div的id
layers: [ // 图层
new TileLayer({
source: new OSM() // 图层数据源 OSM为openlayer自带默认全球瓦片地图
})
],
view: new View({ // 地图视图
center: [0, 0], // 地图中心点坐标
projection: "EPSG:4326", // 坐标系,有EPSG:4326和EPSG:3857
zoom: 2 // 地图默认缩放级别
})
});
}
</script>
概念说明
Map 地图
map 是 Openlayers 的核心组件,表示地图容器。newMap 也就是创建一个地图容器,在 target 参数中绑定 dom 组件的 id 实现将地图挂载在该 dom 中,以此在界面中展示 map
在示例中 new Map 用到的属性:
target: 映射的容器,用于与dom进行绑定。可以是元素本身或元素的ID。如果在构造时未指定,则必须调用setTarget才能渲染地图。layers: 图层。如果未定义,则将渲染没有图层的地图。请注意,图层是按提供的顺序渲染的, 顺序为 [最底部图层, … , 最顶部图层]view: 地图的视图。用于配制地图相关信息,如: 中心点、缩放等级、透明度、坐标系规则、旋转角度等
其他 map 属性:
controls:地图控件。常用的地图控件有:缩放、定位、比例尺、旋转、图层切换、全屏等。pixelRatio:设备上物理像素与设备无关像素 (dip) 之间的比率。Openlayer 会自动调整,确保地图在高像素密度设备上不会模糊interactions:与 Map 的交互。一般不用写,Openlayers 会使用一套默认的交互。maxTilesLoading:要同时加载的最大瓦片数。默认为16moveTolerance:光标必须移动的最小距离(以像素为单位),才能被检测为地图移动事件而不是单击。增加此值可以更轻松地在地图上单击。keyboardEventTarget:要侦听键盘事件的元素
layers 图层
在 Map 中的图层,一个 Map 中可以有多个图层,所以这是个集合。在 ol 中,主要定义了四种图层类型,矢量瓦片图层 Vector Tile Layer、图片图层Image Layer、切片图层Tile Layer、 矢量图层Vector Layer,它们都是继承 Layer 这个基类。
map 可以通过
addLayer()将一个新的 layer 添加到集合末尾,也可以通过removeLayer()移除指定 layer
layer 的主要属性:
source:图层的数据源,可以使用 ol 自带的OSM、天地图、百度、高徳等。extent:图层渲染的边界范围。图层将不会在此范围之外进行渲染。opacity:图层透明度visible:图层是否可见minZoom:图层最小缩放程度,如果地图缩放级别小于minZoom该图层将不显示maxZoom:图层最大缩放程度,与上面同理zIndex:图层层级,类型为 number 层级越大越靠上。默认为0
当前展示地图使用 Tile Layer 图层就可以,其他图层我会在之后的篇章说明
const layer = new TileLayer({
source: new XYZ({
url: `http://wprd0{1-4}.is.autonavi.com/appmaptile?lang=zh_cn&size=1&style=7&x={x}&y={y}&z={z}`,
}),
// 设置图层展示范围 四个参数分别为左下角经度、左下角纬度、右上角经度、右上角纬度。
// 注意:对于 EPSG:3857(Web Mercator 投影),extent 中的坐标值通常是以米为单位的平面坐标。
extent: [14, -10, 36, 20],
projection: "EPSG:4326", // 图层坐标系,有EPSG:4326和EPSG:3857
opacity: 0.9, // 图层透明度
visible: true, // 图层可见性 可以通过 setVisible() 方法更改
minZoom: 1, // 图层最小缩放级别
maxZoom: 18, // 图层最大缩放级别
zIndex: 0, // 图层层级
});
map.addLayer(layer);
View 视图
View 是地图视图的核心对象,用于控制地图的可视化状态和行为。它管理地图的 中心点、缩放级别、旋转角度、倾斜角度 等信息。
view 的主要属性:
center:地图中心位置,通常以经纬度表示。类型:[number, number]zoom:地图的缩放级别,通常是一个整数,0为最小,28为最大。rotation:地图的旋转角度,类型为number,0表示无旋转,Math.PI /2表示旋转90度。maxZoom:地图的最大缩放级别,限制用户可以缩放的最大级别。默认为28。minZoom地图的最小缩放级别,限制用户可以缩放的最小级别。默认为0。resolution:地图的分辨率。extent:地图的显示范围(区域),是地图视图所能显示的最小和最大经纬度范围。state:state是一个对象,包含content、zoom、rotation、projection属性。可以通过view.getState()获取
const view = new View({
center: [0, 0], // 地图中心点坐标
zoom: 2, // 地图默认缩放级别
rotation: Math.PI / 6, // 旋转角度
maxZoom: 18, // 最大缩放级别
minZoom: 1, // 最小缩放级别
resolution: 10000, // 分辨率 resolution 值较小,地图显示的区域更小,精度更高。
extent: [-180, -90, 180, 90], // 显示范围 四个参数分别为左下角经度、左下角纬度、右上角经度、右上角纬度。
projection: "EPSG:4326", // 地图的坐标系,有EPSG:4326和EPSG:3857
});
const state = view.getState();
console.log(state);
map.setView(view);
可以看到,由于设置了 rotation 的原因,整个地图就进行了旋转
state 的打印:
Source 数据源
Source 负责加载和提供图层所需的数据。它是一个抽象类,ol 使用其子类。这些子类可用于加载xyz、OpenStreetMap或高德、Bing、Goole街景、天地图、超图等免费和商业地图切片服务,“WMS”或“WMTS”等OGC源,以及“GeoJSON”或KML等格式的矢量数据。
projection 地图投影
地图投影是一个数学过程,它将地球表面的三维坐标(如经度、纬度)转换为平面上的二维坐标。因为地球是一个球形的对象,而屏幕显示的是二维图像,所以不同的投影方法用来平衡地理精度和显示需求。
OpenLayers 支持的投影包括经典的地理坐标系(如 EPSG:4326)和广泛用于网络地图的投影坐标系(如 EPSG:3857)。
OpenLayers 默认使用 EPSG:3857(Web Mercator)作为地图的投影,
投影坐标系选择:
- 数据源的要求:如果你使用的是全球性的地图数据(如 OSM、Google Maps),通常推荐使用
EPSG:3857。 - 地理数据的精度需求:如果你需要展示精确的地理位置(如 GPS 数据),并且不需要太多的缩放,
EPSG:4326可能是更合适的选择。 - 其他:每种投影都有其特定的属性,因此在某些特定区域,选择合适的投影可以提高地图的精度和表现效果。
使用多个投问题
在一个 Map 中只会使用一个投影,当 view 和 layer 使用不同的投影坐标系时,OpenLayers 会自动将图层的坐标转换为视图使用的投影坐标系。这使得在不同投影之间切换时,图层仍然能够正确渲染。
注意:这也可能带来一些性能问题和精度问题,特别是在高纬度地区或精确度要求较高的情况下。因此,最好在设计地图时确保视图和图层使用相同或兼容的投影坐标系。
关于作者
如果文章中有错误或不够详细的地方,欢迎在评论区指出 😺。在下一篇文章中,我将介绍如何在 OpenLayers 中使用来自不同平台的数据源来创建瓦片图层 😎。
juejin backend
为什么Go语言中的反射 性能消耗更大呢?
Go 语言中的反射性能消耗更大,主要是由以下几个方面的原因导致的:
运行时类型检查
- 静态类型检查与动态类型检查:在普通的 Go 代码中,类型检查是在编译阶段完成的,编译器可以提前确定变量的类型,从而进行优化。例如,当调用一个函数时,编译器知道函数参数和返回值的类型,能够直接生成高效的机器码。而反射是在运行时进行类型检查,程序需要在运行时动态地确定对象的类型和结构。这意味着反射操作不能利用编译时的优化,每次执行反射操作都需要进行额外的类型检查,增加了运行时的开销。
package main
import (
"fmt"
"reflect"
)
func main() {
var num int = 42
// 普通调用,编译时已知类型
fmt.Println(num)
// 反射调用,运行时检查类型
value := reflect.ValueOf(num)
fmt.Println(value.Int())
}
- 类型信息的获取:反射需要通过
reflect.TypeOf和reflect.ValueOf等函数获取对象的类型和值信息。这些信息在运行时存储在内存中,获取这些信息需要进行额外的内存访问和处理。而且,对于复杂的类型,如嵌套结构体、接口等,获取类型信息的过程会更加复杂,进一步增加了性能开销。
方法调用和字段访问
- 方法调用的间接性:使用反射调用方法时,需要先通过反射获取方法的描述信息,然后再调用该方法。这个过程涉及到多个步骤,包括查找方法、参数类型检查、方法调用的调度等,比直接调用方法要复杂得多。例如,直接调用一个结构体的方法可以直接通过函数指针进行跳转,而反射调用则需要在运行时进行一系列的查找和调度操作。
package main
import (
"fmt"
"reflect"
)
type Calculator struct{}
func (c Calculator) Add(a, b int) int {
return a + b
}
func main() {
calc := Calculator{}
// 直接调用方法
result1 := calc.Add(1, 2)
fmt.Println(result1)
// 反射调用方法
value := reflect.ValueOf(calc)
method := value.MethodByName("Add")
if method.IsValid() {
params := []reflect.Value{reflect.ValueOf(1), reflect.ValueOf(2)}
results := method.Call(params)
if len(results) > 0 {
fmt.Println(results[0].Int())
}
}
}
- 字段访问的复杂性:通过反射访问结构体的字段也需要进行额外的处理。反射需要在运行时查找字段的偏移量和类型信息,然后才能进行字段的读取或写入操作。这比直接访问结构体字段要慢得多,因为直接访问可以通过结构体的内存布局直接计算出字段的地址。
内存分配和垃圾回收
- 额外的内存分配:反射操作通常会创建额外的对象,如
reflect.Type和reflect.Value等,这些对象需要在堆上分配内存。频繁的反射操作会导致大量的内存分配和释放,增加了内存管理的负担。而且,这些额外的对象在不再使用时需要被垃圾回收器回收,进一步增加了垃圾回收的压力。 - 垃圾回收的影响:由于反射操作会产生大量的临时对象,垃圾回收器需要更频繁地运行来回收这些对象占用的内存。垃圾回收过程会暂停程序的执行,对程序的性能产生影响。特别是在高并发场景下,频繁的垃圾回收会导致程序的响应时间变长,吞吐量下降。
缺乏编译时优化
- 静态代码优化的缺失:编译器在编译普通的 Go 代码时,可以进行各种优化,如内联函数调用、常量折叠、循环展开等,以提高代码的执行效率。而反射代码在运行时动态执行,编译器无法对其进行这些优化。反射操作的逻辑和数据都是在运行时确定的,编译器无法提前预测和优化,导致反射代码的执行效率相对较低。
综上所述,Go 语言中的反射由于运行时类型检查、方法调用和字段访问的复杂性、内存分配和垃圾回收的影响以及缺乏编译时优化等原因,导致其性能消耗比普通代码更大。因此,在性能敏感的场景中,应尽量避免使用反射,或者仅在必要时使用。
Go 语言的类型断言和反射
在 Go 语言中,类型断言和反射都是用于处理接口值的重要机制,但它们在功能、使用方式、性能等方面存在显著区别,以下是详细介绍:
基本概念
- 类型断言:类型断言是一种检查接口值底层具体类型的方式。它用于从接口值中提取出底层具体类型的值,或者判断接口值是否为某个特定类型。类型断言的语法形式为
x.(T),其中x是一个接口类型的变量,T是一个具体类型。 - 反射:反射是指在运行时检查和操作对象的类型和值的能力。Go 语言提供了
reflect包来支持反射操作,通过反射可以获取对象的类型信息、调用对象的方法、修改对象的字段值等。
使用方式
类型断言
类型断言通常用于在已知可能的具体类型的情况下,对接口值进行类型检查和转换。它有两种形式:
- 简单形式:
value := x.(T),如果x的底层类型不是T,则会触发运行时 panic。
package main
import "fmt"
func main() {
var x interface{} = "hello"
// 简单形式,若类型不匹配会触发 panic
value := x.(string)
fmt.Println(value)
}
- 安全形式:
value, ok := x.(T),ok是一个布尔值,表示类型断言是否成功。如果成功,value为转换后的值;如果失败,value为T类型的零值,ok为false。
package main
import "fmt"
func main() {
var x interface{} = 123
value, ok := x.(string)
if ok {
fmt.Println(value)
} else {
fmt.Println("类型断言失败")
}
}
反射
反射通过 reflect 包中的函数和类型来实现,主要涉及 reflect.Type 和 reflect.Value 两个核心类型:
reflect.Type表示对象的类型信息,可以通过reflect.TypeOf函数获取。reflect.Value表示对象的值,可以通过reflect.ValueOf函数获取。
package main
import (
"fmt"
"reflect"
)
func main() {
var num int = 42
// 获取类型信息
numType := reflect.TypeOf(num)
// 获取值信息
numValue := reflect.ValueOf(num)
fmt.Println("Type:", numType)
fmt.Println("Value:", numValue)
}
功能范围
类型断言
类型断言的功能相对单一,主要用于判断接口值是否为某个特定类型,并进行类型转换。它只能处理已知的具体类型,对于未知类型或需要动态处理的场景,类型断言的能力有限。
反射
反射的功能更强大和灵活,可以在运行时动态地获取对象的类型信息、调用对象的方法、修改对象的字段值等。它可以处理任意类型的对象,不需要提前知道对象的具体类型。
package main
import (
"fmt"
"reflect"
)
type Person struct {
Name string
Age int
}
func main() {
p := Person{Name: "Alice", Age: 30}
// 获取反射值
value := reflect.ValueOf(&p).Elem()
// 修改字段值
nameField := value.FieldByName("Name")
if nameField.IsValid() && nameField.CanSet() {
nameField.SetString("Bob")
}
fmt.Println(p) // 输出: {Bob 30}
}
性能差异
类型断言
类型断言的性能较高,因为它是在编译时或运行时进行简单的类型检查和转换,开销相对较小。在已知可能的具体类型的情况下,使用类型断言是首选的方式。
反射
反射的性能相对较低,因为它涉及到运行时的类型检查、方法调用和内存分配等操作,会带来一定的性能开销。反射操作通常比直接调用函数或访问字段慢很多,因此在性能要求较高的场景下,应谨慎使用反射。
代码复杂度
类型断言
类型断言的代码相对简洁易懂,语法简单,容易掌握。它适用于简单的类型检查和转换场景。
反射
反射的代码相对复杂,需要熟悉 reflect 包中的各种函数和类型,并且要处理各种可能的异常情况。反射通常用于处理复杂的动态场景,但会增加代码的复杂度和维护成本。
综上所述,类型断言和反射各有优缺点,应根据具体的应用场景选择合适的方式。在已知可能的具体类型且对性能要求较高的情况下,优先使用类型断言;在需要动态处理对象的类型和值的复杂场景下,可以考虑使用反射。
类型断言和反射
在 Go 语言中,当函数的输入参数类型为 any(在 Go 1.18 及以后版本可用,之前版本为 interface{})时,若要判断这个 any 类型的值是否为切片或者数组,可以使用类型断言和反射两种方法,下面分别进行详细介绍:
方法一:使用类型断言
类型断言是一种检查接口值底层具体类型的方式,通过类型断言可以尝试将 any 类型的值转换为切片或数组类型,若转换成功则说明该值为对应的类型。
package main
import (
"fmt"
)
func checkIfSliceOrArray(input any) {
// 尝试将 input 断言为切片类型
if _, ok := input.([]any); ok {
fmt.Println("输入是切片")
return
}
// 尝试将 input 断言为数组类型(这里以长度为 3 的 int 数组为例)
if _, ok := input.([3]int); ok {
fmt.Println("输入是数组")
return
}
fmt.Println("输入既不是切片也不是数组")
}
func main() {
slice := []int{1, 2, 3}
array := [3]int{4, 5, 6}
num := 10
checkIfSliceOrArray(slice)
checkIfSliceOrArray(array)
checkIfSliceOrArray(num)
}
代码解释:
- 在
checkIfSliceOrArray函数中,首先使用类型断言input.([]any)尝试将input转换为切片类型,如果转换成功(ok为true),则说明输入是切片。 - 接着使用类型断言
input.([3]int)尝试将input转换为长度为 3 的int数组类型,如果转换成功,则说明输入是数组。 - 如果以上两种类型断言都失败,则说明输入既不是切片也不是数组。
方法二:使用反射
反射是 Go 语言提供的一种在运行时检查和操作对象的机制,通过反射可以获取对象的类型信息,从而判断其是否为切片或数组。
package main
import (
"fmt"
"reflect"
)
func checkIfSliceOrArrayWithReflect(input any) {
// 获取 input 的反射类型
inputType := reflect.TypeOf(input)
if inputType != nil {
switch inputType.Kind() {
case reflect.Slice:
fmt.Println("输入是切片")
case reflect.Array:
fmt.Println("输入是数组")
default:
fmt.Println("输入既不是切片也不是数组")
}
} else {
fmt.Println("输入是 nil")
}
}
func main() {
slice := []int{1, 2, 3}
array := [3]int{4, 5, 6}
num := 10
checkIfSliceOrArrayWithReflect(slice)
checkIfSliceOrArrayWithReflect(array)
checkIfSliceOrArrayWithReflect(num)
}
代码解释:
- 在
checkIfSliceOrArrayWithReflect函数中,使用reflect.TypeOf(input)获取input的反射类型。 - 通过
inputType.Kind()获取该类型的具体种类,然后使用switch语句判断其是否为reflect.Slice或reflect.Array,如果是则分别输出相应信息,否则说明输入既不是切片也不是数组。 - 如果
inputType为nil,则说明输入是nil。
两种方法的比较
- 类型断言:代码简洁,性能较高,但只能针对特定的类型进行判断,如果需要判断多种不同类型的切片或数组,需要编写多个类型断言语句。
- 反射:更加灵活,可以在运行时动态判断任意类型的切片或数组,但反射操作会带来一定的性能开销,因为它涉及到运行时的类型检查和操作。在性能要求较高的场景下,应谨慎使用反射。
juejin frontend
💡JS-函数中的this是什么?不同环境可不一样
函数中的 this 值是什么?不同环境,不同模式,不同函数内,它的值是不一样的。
我们一个一个看看:
浏览器环境
非严格模式
function Test() {
console.log("test", this);
}
const Test2 = () => {
console.log("test2", this);
};
Test();
Test2();
代码的目的是看看,两个不同的函数,如果都是用直接调用的方法执行,其中的 this 是什么值?
那上面的代码,在浏览器中运行结果是什么?
显示,两次输出都是 window 对象
为什么?
在浏览器中,如果是直接调用普通的 function 函数,那么 function 函数中的 this 指向 window 对象。对于箭头函数来说,其中的 this 并不是由调用方式决定的,而是由其声明的环境决定的。其中的 this 的值继承自父级作用域。而全局作用域中,this 的值也是 window 对象
严格模式
那同样是浏览器环境,如果是严格模式的话,上面代码的执行结果是什么呢?
在代码的眼前,加上
'use strict',就可以开启严格模式了
严格模式下,箭头函数的打印结果还是一样的,但对于 function 函数的打印结果不同。
ECMA 组织规定,这时候 function 函数,如果是直接调用,那么其中的 this 不再指向 window 这个全局对象了,而是 undefined
node 环境
非严格模式
好,浏览器环境讲完了,下面看看 node 环境。先在非严格模式下执行:
上面是 node 环境下的执行结果。其中 function 函数和箭头函数的输出是不一样的。function 函数中的 this 指向全局对象 global。而箭头函数中 this 是一个空对象!
下面改改代码,让 this 的指向更清楚:
function Test() {
console.log("test", this.name);
}
const Test2 = () => {
console.log("test2", this.name);
};
global.name = "test zenos";
exports.name = "test2 zenos";
Test();
Test2();
在执行两个函数之前,分别给 global 对象和 exports 对象添加了 name 属性。函数内容的 this 打印也改成了只打印 this 中的 name。
执行结果:
从结果可以看出,function 函数中的 this 指向全局对象 global。而箭头函数中 this 指向 exports 对象!
严格模式
那么,同样是 node 环境,严格模式下会有什么变化吗?
"use strict";
function Test() {
// 这里是this
console.log("test", this);
}
const Test2 = () => {
console.log("test2", this.name);
};
global.name = "test zenos";
console.log(global.name);
Test();
exports.name = "test2 zenos";
Test2();
上面修改一些代码,下面是打印结果:
可以看到在严格模式下,直接调用的 function 中的 this 是 undefined。不过全局对象 global 还是有的。全局环境中的 this 还是和 exports 一致。
四种环境
总结
本篇文章比较短,主要讲了不同环境中的 this 的值是什么?
- 浏览器环境,
- 非严格模式
- function:window
- 箭头 function:window
- 非严格模式
- function:undefined
- 箭头 function:window
- 非严格模式
- node 环境
- 非严格模式
- function:global
- 箭头 function:exports
- 非严格模式
- function:undefined
- 箭头 function:exports
- 非严格模式
最后一个问题,为什么在 node 环境中,this 的值是 exports?理解需要一点模块化的知识,这个我们后面再讲
juejin backend
Go 方法 值类型和指针类型
在 Go 语言里,为类型实现接口时,接收者可以是值类型((a A))或者指针类型((a *A)),这两种方式存在显著区别,下面从内存操作、方法内部修改、调用方式以及接口实现的兼容性这几个方面进行详细分析:
1. 内存操作
- 值接收者
(a A):当使用值接收者实现接口方法时,调用该方法会对原始对象进行一次复制,方法内部操作的是对象的副本,而不是原始对象。这意味着在方法内部对接收者的修改不会影响到原始对象。 - 指针接收者
(a *A):使用指针接收者实现接口方法时,传递给方法的是原始对象的内存地址,方法内部直接操作的是原始对象,不会产生对象的副本。因此,在方法内部对接收者的修改会直接影响到原始对象。
2. 方法内部修改
- 值接收者
(a A):由于操作的是对象副本,在方法内部修改接收者的属性或元素不会影响原始对象。package main import "fmt" type A struct { Value int } // 定义接口 type InterfaceA interface { Modify() } // 使用值接收者实现接口方法 func (a A) Modify() { a.Value = 100 } func main() { a := A{Value: 1} var i InterfaceA = a i.Modify() fmt.Println(a.Value) // 输出: 1,原始对象未被修改 } - 指针接收者
(a *A):因为操作的是原始对象,在方法内部修改接收者的属性或元素会影响原始对象。package main import "fmt" type A struct { Value int } // 定义接口 type InterfaceA interface { Modify() } // 使用指针接收者实现接口方法 func (a *A) Modify() { a.Value = 100 } func main() { a := A{Value: 1} var i InterfaceA = &a i.Modify() fmt.Println(a.Value) // 输出: 100,原始对象被修改 }
3. 调用方式
- 值接收者
(a A):既可以使用值类型的变量调用方法,也可以使用指针类型的变量调用方法。Go 语言会自动进行转换。package main import "fmt" type A struct{} // 定义接口 type InterfaceA interface { Print() } // 使用值接收者实现接口方法 func (a A) Print() { fmt.Println("Printing from value receiver") } func main() { a := A{} var i InterfaceA = a i.Print() // 可以使用值类型调用 ptrA := &a i = ptrA i.Print() // 也可以使用指针类型调用 } - 指针接收者
(a *A):通常只能使用指针类型的变量调用方法。如果使用值类型的变量调用,需要先获取其地址。package main import "fmt" type A struct{} // 定义接口 type InterfaceA interface { Print() } // 使用指针接收者实现接口方法 func (a *A) Print() { fmt.Println("Printing from pointer receiver") } func main() { a := A{} var i InterfaceA = &a i.Print() // 必须使用指针类型调用 // 以下代码会编译错误 // i = a // i.Print() }
4. 接口实现的兼容性
- 值接收者
(a A):实现了接口的类型的值和指针都可以赋值给该接口类型的变量。 - 指针接收者
(a *A):只有实现了接口的类型的指针才能赋值给该接口类型的变量,值类型不能直接赋值。
总结
- 如果方法不需要修改接收者的状态,或者需要进行值传递(如需要副本),可以使用值接收者。
- 如果方法需要修改接收者的状态,或者为了避免复制大对象带来的性能开销,应该使用指针接收者。
Go语言 依赖注入
在Go语言中,依赖注入(Dependency Injection,简称DI)是一种设计模式,用于实现松耦合和可测试性的代码。通过依赖注入,对象的依赖关系由外部提供,而不是在对象内部创建,这使得代码更加灵活和可维护。以下是几种常见的Go语言依赖注入方案:
1. 手动依赖注入
手动依赖注入是最基本的方式,通过构造函数或方法参数将依赖项传递给对象。
示例代码:
package main
import "fmt"
// Logger 定义一个日志接口
type Logger interface {
Log(message string)
}
// ConsoleLogger 实现 Logger 接口
type ConsoleLogger struct{}
func (c *ConsoleLogger) Log(message string) {
fmt.Println("Logging:", message)
}
// UserService 依赖于 Logger 接口
type UserService struct {
logger Logger
}
// NewUserService 构造函数,用于注入 Logger 依赖
func NewUserService(logger Logger) *UserService {
return &UserService{
logger: logger,
}
}
// CreateUser 方法使用注入的 Logger 记录日志
func (u *UserService) CreateUser(name string) {
u.logger.Log("Creating user: " + name)
// 实际创建用户的逻辑
}
func main() {
logger := &ConsoleLogger{}
userService := NewUserService(logger)
userService.CreateUser("John Doe")
}
解释:
- 定义了一个
Logger接口和其实现ConsoleLogger。 UserService结构体依赖于Logger接口,通过NewUserService构造函数注入Logger实例。- 在
main函数中,创建ConsoleLogger实例并注入到UserService中。
2. 使用Go-kit的依赖注入
Go-kit是一个用于构建微服务的工具包,它提供了一些辅助函数和接口来实现依赖注入。
示例代码:
package main
import (
"context"
"fmt"
"github.com/go-kit/kit/log"
)
// UserService 依赖于 Logger
type UserService struct {
logger log.Logger
}
// NewUserService 构造函数,用于注入 Logger 依赖
func NewUserService(logger log.Logger) *UserService {
return &UserService{
logger: logger,
}
}
// CreateUser 方法使用注入的 Logger 记录日志
func (u *UserService) CreateUser(ctx context.Context, name string) {
u.logger.Log("msg", "Creating user", "name", name)
// 实际创建用户的逻辑
}
func main() {
logger := log.NewLogfmtLogger(log.NewSyncWriter(fmt.Stdout))
userService := NewUserService(logger)
userService.CreateUser(context.Background(), "Jane Smith")
}
解释:
- 使用Go-kit的
log.Logger接口和log.NewLogfmtLogger创建日志记录器。 UserService依赖于log.Logger,通过构造函数注入。
3. 使用Google的Wire
Google的Wire是一个用于Go语言的依赖注入代码生成工具,它可以自动生成依赖注入的代码,减少手动编写的工作量。
示例代码:
package main
import (
"fmt"
)
// Logger 定义一个日志接口
type Logger interface {
Log(message string)
}
// ConsoleLogger 实现 Logger 接口
type ConsoleLogger struct{}
func (c *ConsoleLogger) Log(message string) {
fmt.Println("Logging:", message)
}
// UserService 依赖于 Logger 接口
type UserService struct {
logger Logger
}
// NewUserService 构造函数,用于注入 Logger 依赖
func NewUserService(logger Logger) *UserService {
return &UserService{
logger: logger,
}
}
// CreateUser 方法使用注入的 Logger 记录日志
func (u *UserService) CreateUser(name string) {
u.logger.Log("Creating user: " + name)
// 实际创建用户的逻辑
}
// wire.go
//go:build wireinject
// +build wireinject
import "github.com/google/wire"
func InitializeUserService() *UserService {
wire.Build(NewUserService, new(ConsoleLogger))
return nil
}
使用步骤:
- 安装Wire:
go install github.com/google/wire/cmd/wire@latest - 在项目根目录下运行
wire命令,Wire会自动生成wire_gen.go文件。 - 在代码中使用生成的
InitializeUserService函数创建UserService实例。
4. 使用Dig
Dig是一个用于Go语言的依赖注入容器,它允许你通过注解和反射来管理依赖关系。
示例代码:
package main
import (
"fmt"
"go.uber.org/dig"
)
// Logger 定义一个日志接口
type Logger interface {
Log(message string)
}
// ConsoleLogger 实现 Logger 接口
type ConsoleLogger struct{}
func (c *ConsoleLogger) Log(message string) {
fmt.Println("Logging:", message)
}
// UserService 依赖于 Logger 接口
type UserService struct {
logger Logger
}
// NewUserService 构造函数,用于注入 Logger 依赖
func NewUserService(logger Logger) *UserService {
return &UserService{
logger: logger,
}
}
// CreateUser 方法使用注入的 Logger 记录日志
func (u *UserService) CreateUser(name string) {
u.logger.Log("Creating user: " + name)
// 实际创建用户的逻辑
}
func main() {
container := dig.New()
// 提供依赖项
container.Provide(func() Logger {
return &ConsoleLogger{}
})
container.Provide(NewUserService)
// 执行函数,注入依赖项
err := container.Invoke(func(userService *UserService) {
userService.CreateUser("Bob Johnson")
})
if err != nil {
fmt.Println("Error:", err)
}
}
解释:
- 使用Dig创建一个容器
container。 - 通过
container.Provide方法注册依赖项。 - 使用
container.Invoke方法执行函数并注入依赖项。
Pandas高级数据处理:分布式计算
一、引言
随着数据量的不断增加,传统的Pandas单机处理方式已经难以满足大规模数据处理的需求。分布式计算为解决这一问题提供了有效的方案。本文将由浅入深地介绍Pandas在分布式计算中的常见问题、常见报错及如何避免或解决,并通过代码案例进行解释。
二、Dask简介
Dask是Pandas的一个很好的补充,它允许我们使用类似于Pandas的API来处理分布式数据。Dask可以自动将任务分配到多个核心或节点上执行,从而提高数据处理的速度。与Pandas相比,Dask的主要优势在于它可以处理比内存更大的数据集,并且可以在多台机器上并行运行。
三、常见问题
1. 数据加载
在分布式环境中,数据加载是一个重要的步骤。我们需要确保数据能够被正确地分割并加载到各个节点中。
- 问题:当数据量非常大时,可能会遇到内存不足的问题。
- 解决方案:使用
dask.dataframe.read_csv()等函数代替Pandas的read_csv()。Dask会根据文件大小和可用资源自动调整块大小,从而避免一次性加载过多数据到内存中。
import dask.dataframe as dd
df = dd.read_csv('large_file.csv')
2. 数据类型推断
Dask需要对数据类型进行推断以便更好地优化计算过程。
- 问题:如果数据类型推断错误,可能会导致性能下降甚至程序崩溃。
- 解决方案:可以通过指定
dtype参数来显式定义数据类型,减少不必要的转换开销。
df = dd.read_csv('data.csv', dtype={'column1': 'float64', 'column2': 'int32'})
3. 分区管理
合理的分区对于分布式计算至关重要。过少或过多的分区都会影响性能。
- 问题:默认情况下,Dask可能不会为我们选择最优的分区数。
- 解决方案:根据实际需求调整分区数量。例如,可以通过
repartition()方法重新设置分区数目。
df = df.repartition(npartitions=10)
四、常见报错及解决方法
1. 内存溢出
-
报错信息:MemoryError
-
原因分析:尝试一次性处理的数据量超出了系统内存限制。
-
解决措施:
- 使用Dask替代Pandas进行大数据处理;
- 对于Dask本身,检查是否有未释放的中间结果占用过多内存,及时清理不再使用的变量;
- 调整Dask的工作线程数或进程数以适应硬件条件。
2. 类型不匹配
- 报错信息:TypeError
- 原因分析:操作过程中涉及到了不同类型的对象之间的非法运算。
- 解决措施:仔细检查参与运算的各列的数据类型是否一致;必要时使用
astype()转换数据类型。
3. 网络通信失败
- 报错信息:ConnectionError
- 原因分析:集群内部网络连接不稳定或者配置不当。
- 解决措施:确保所有节点之间网络畅通无阻;正确配置防火墙规则允许必要的端口通信;检查集群管理软件(如YARN)的状态。
五、总结
通过引入Dask库,我们可以轻松实现Pandas的分布式计算,极大地提高了数据处理效率。然而,在实际应用过程中也会遇到各种各样的挑战。了解这些常见问题及其对应的解决办法有助于我们更加顺利地开展工作。希望本文能够帮助大家更好地掌握Pandas分布式计算的相关知识。
juejin frontend
✨深入解析前端插件机制:以埋点SDK与Webpack为例
最近在做前端监控的全链路项目, 刚好埋点SDK这边的架构设计需要用到插件机制, 就想着和之前学过的webpack插件机制进行一个类比, 看看有哪些共通和差异之处
在现代软件开发中,插件机制是实现系统扩展性和灵活性的核心设计模式之一。无论是前端监控工具还是构建工具,插件机制都在背后发挥着重要作用。本文将以 ByteTop 监控 SDK(暂未开源) 和 Webpack 构建工具 为例,深入探讨两者的插件机制设计异同,并揭示其背后的设计哲学。
一、插件机制的核心价值
1. 模块化与解耦
插件机制通过将核心功能与扩展功能分离,使得系统能够在不修改核心代码的情况下扩展能力。例如:
- ByteTop:通过插件实现行为监控、性能采集等独立功能模块。
- Webpack:通过插件处理代码压缩、资源优化等构建阶段任务。
2. 灵活性与可扩展性
开发者可以根据需求动态加载或替换插件,例如:
- ByteTop 按需加载广告监控插件。
- Webpack 通过
html-webpack-plugin动态生成 HTML 文件。
3. 生态共建
开放的插件机制吸引社区贡献,形成丰富的工具生态。例如:
- Webpack 社区有超过 1000 个插件。
- ByteTop 未来计划构建插件市场支持第三方扩展。
二、插件机制的本质:通过解耦和扩展赋予系统生命力
插件机制的核心目标是通过模块化和解耦赋予系统扩展性,但不同场景下的设计选择可能截然不同。例如:
- 监控类工具(ByteTop):要求高稳定性,插件崩溃不能影响核心功能。
- 构建工具(Webpack):追求灵活性和流程控制,插件需深度介入构建链路。
通过对比两者的设计差异,我们可以更清晰地理解如何根据业务场景选择插件模型。
先来看下ByteTop 与 Webpack 插件机制的异同
1. 相同点
| 维度 | ByteTop | Webpack |
|---|---|---|
| 扩展性 | 通过插件扩展监控能力 | 通过插件扩展构建流程 |
| 生命周期 | 插件需实现 init/start/stop | 插件通过钩子介入不同阶段 |
| 事件驱动 | 基于事件总线通信 | 基于 Tapable 钩子通信 |
2. 核心差异
| 维度 | ByteTop | Webpack |
|---|---|---|
| 运行环境 | 插件运行在沙箱中(隔离环境) | 插件运行在主进程(共享环境) |
| 错误处理 | 熔断机制 + 异常隔离,崩溃不影响核心 | 插件错误可能导致整个构建失败 |
| 性能优化 | 动态采样 + 资源配额控制 | 依赖插件自身优化(如缓存、并行处理) |
| 通信方式 | 事件总线 + 异步队列 | 同步/异步钩子 + 共享上下文对象 |
| 核心目标 | 高可用性(监控场景不可中断) | 高效率(快速完成构建任务) |
三、这两个插件机制的详解
先来看ByteTop监控SDK的👇
1. 架构设计
ByteTop 采用 内核(Core)+ 插件(Plugin) 的沙箱化架构:
- 内核:负责插件管理、事件总线、上报队列等基础服务。
- 插件:独立运行在沙箱环境(如 Web Worker),通过事件总线与内核通信。
核心特性:
- 异常隔离:单个插件崩溃不影响整体 SDK。
- 动态采样:根据系统负载调整数据采集频率。
- 熔断机制:插件连续失败后自动降级。
代码示例:
// 插件定义
class ClickTrackerPlugin implements IPlugin {
name = 'click-tracker';
init(config) {
this.sampleRate = config.get('clickSampleRate');
}
start() {
document.addEventListener('click', (e) => {
if (Math.random() < this.sampleRate) {
this.core.report({ type: 'CLICK', data: { target: e.target } });
}
});
}
}
2. 通信机制
- 事件总线(Event Bus):插件通过订阅/发布模式与内核交互。
- 数据上报队列:异步批量处理数据,减少网络请求开销。
接下来是 Webpack 的👇
1. 架构设计
Webpack 的插件机制基于 Tapable 事件流,通过钩子(Hooks)介入构建流程的不同阶段:
- Compiler:核心编译器实例,暴露构建生命周期钩子。
- Compilation:单次编译过程的上下文,管理模块依赖和资源生成。
核心特性:
- 声明式钩子:如
emit(生成资源前)、done(构建完成)等。 - 同步/异步执行:支持串行、并行、瀑布流等执行模式。
- 上下文共享:插件通过
compiler和compilation对象访问构建状态。
代码示例:
// 一个简单的 Webpack 插件
class LogOnDonePlugin {
apply(compiler) {
compiler.hooks.done.tap('LogOnDonePlugin', (stats) => {
console.log('构建已完成!');
});
}
}
2. 通信机制
- 钩子注入:插件通过
tap方法注册回调逻辑。 - 事件驱动:构建过程中的每个阶段触发对应的钩子事件。
四、直击核心:5 个关键问题揭示设计差异
问题 1:插件崩溃是否会导致系统崩溃?
-
ByteTop:
- 沙箱隔离:每个插件运行在独立 Web Worker 中。
- 熔断机制:插件连续失败后自动降级,内核通过
window.onerror兜底。 - 数据佐证:在 Chrome 中测试,模拟插件内存泄漏,SDK 主线程崩溃率降低 99%。
-
Webpack:
- 共享进程:插件运行在主进程,未捕获异常会导致构建失败。
- 典型案例:若
UglifyJsPlugin配置错误,整个构建流程终止。
问题 2:插件如何与核心系统通信?
ByteTop 的 事件总线 + 异步队列:
// 插件通过事件总线订阅页面加载事件
core.eventBus.subscribe('PAGE_LOADED', (data) => {
this.reportPerformance(data);
});
// 数据上报进入异步队列,由内核批量处理
core.reportQueue.add({ type: 'PERF', data });
优势:解耦插件与上报逻辑,网络波动时自动重试。
Webpack 的 Tapable 钩子 + 共享上下文:
// 插件通过钩子介入资源生成阶段
compiler.hooks.emit.tapAsync('MyPlugin', (compilation, callback) => {
compilation.assets['manifest.json'] = generateManifest();
callback();
});
优势:直接操作编译上下文,实现深度定制。
问题 3:如何控制插件对性能的影响?
| 维度 | ByteTop | Webpack |
|---|---|---|
| CPU | 动态采样(负载高时降低采集频率) | 并行处理(如 HappyPack 多线程编译) |
| 内存 | 插件内存限制(超过 10MB 告警) | 依赖插件自身优化(如缓存) |
| 网络 | 数据压缩 + 令牌桶限流 | 不涉及网络传输 |
问题 4:插件生态如何发展?
-
ByteTop:
- 面向垂直场景:监控、埋点、性能分析。
- 生态现状:内置官方插件,第三方插件需严格审核。
-
Webpack:
- 面向通用构建:代码压缩、资源优化、部署生成。
- 生态现状:社区插件超 1000 个,但质量参差不齐。
关键结论:开放性与稳定性需权衡,垂直领域适合“审核制”,通用领域适合“社区驱动”。
问题 5:如何实现插件热更新?
-
ByteTop:
// 通过 WebSocket 接收新插件代码 socket.on('plugin-update', (code) => { core.pluginManager.update('click-tracker', code); });挑战:沙箱环境需支持代码动态替换。
-
Webpack:
- 原生不支持插件热更新,需重启构建进程。
- 变通方案:通过
webpack-dev-server重启整个构建流程。
五、实战对比:从代码看设计哲学
案例 1:实现一个“资源加载监控”插件
ByteTop 版本:
class ResourceMonitorPlugin implements IPlugin {
name = 'resource-monitor';
private observer: PerformanceObserver;
init() {
// 使用 Performance API 监听资源加载
this.observer = new PerformanceObserver((list) => {
const entries = list.getEntries();
entries.forEach(entry => {
core.report({ type: 'RESOURCE', data: entry });
});
});
this.observer.observe({ entryTypes: ['resource'] });
}
stop() {
this.observer.disconnect(); // 释放资源
}
}
设计重点:资源释放、性能 API 标准化。
Webpack 版本:
class ResourceMonitorPlugin {
apply(compiler) {
compiler.hooks.compilation.tap('ResourceMonitorPlugin', (compilation) => {
compilation.hooks.buildModule.tap('ResourceMonitorPlugin', (module) => {
const start = Date.now();
module.addListener('finish', () => {
const duration = Date.now() - start;
console.log(`模块 ${module.identifier()} 编译耗时: ${duration}ms`);
});
});
});
}
}
设计重点:编译生命周期钩子、模块级监控。
案例 2:错误处理机制对比
ByteTop 的熔断流程:
- 插件崩溃 → 2. 内核捕获错误 → 3. 标记插件为 unhealthy → 4. 降级至兜底逻辑。
Webpack 的错误处理:
- 插件抛出错误 → 2. Webpack 捕获并标记构建失败 → 3. 终止流程。
关键差异:ByteTop 的监控场景要求“永不中断”,Webpack 的构建场景允许“快速失败”。
六、架构图解析:可视化呈现核心差异
ByteTop 架构图
特点:插件与内核物理隔离,通过事件和队列通信。
Webpack 架构图
特点:插件与核心共享内存,通过钩子深度耦合。
七、如何选择?决策树与场景指南
决策树:
- 是否需要高稳定性(如监控、支付)?
- 是 → 选择 ByteTop 模型(沙箱隔离 + 熔断)。
- 否 → 进入下一问题。
- 是否需要深度定制核心流程(如构建、部署)?
- 是 → 选择 Webpack 模型(钩子 + 共享上下文)。
- 否 → 考虑轻量级事件总线方案。
场景指南:
| 场景 | 推荐模型 | 代表工具 |
|---|---|---|
| 前端监控、错误追踪 | ByteTop 模型 | Sentry、ByteTop |
| 工程构建、代码优化 | Webpack 模型 | Webpack、Rollup |
| 微前端、模块热更新 | 混合模型 | qiankun、Vite |
八、插件机制的设计启示&未来演进
1. ByteTop 的设计启示
- 安全第一:通过沙箱隔离和熔断机制,确保核心监控链路稳定。
- 轻量优先:动态采样和懒加载机制,减少对宿主应用的性能影响。
- 适用场景:实时监控、错误追踪、用户行为分析等对稳定性要求高的领域。
2. Webpack 的设计启示
- 流程控制:通过钩子精细控制构建流程的每个环节。
- 生态整合:开放的插件机制催生丰富工具链(如 Loader、Plugin)。
- 适用场景:前端工程化、静态资源打包、代码优化等构建密集型任务。
3. 未来演进
-
边缘计算插件:在 CDN 边缘节点运行插件,实现监控数据预处理。
-
AI 驱动插件:自动识别异常模式并调整采样率(如 ByteTop 的智能降级)。
-
WASM 沙箱:用 WebAssembly 实现更安全的插件隔离(替代 Web Worker)。
九、总结
插件机制的本质是 通过解耦和扩展赋予系统生命力。ByteTop 和 Webpack 虽在实现细节上截然不同,但都体现了这一核心思想:
- ByteTop 以安全性和稳定性为核心,通过沙箱隔离和熔断机制保障监控链路高可用。
- Webpack 以灵活性和效率为核心,通过钩子机制实现构建流程的深度定制。
理解两者的异同,不仅能帮助我们更好地使用现有工具,还能为设计自己的插件系统提供宝贵启示——根据场景需求,权衡隔离与效率,才能打造出真正优秀的扩展架构。
juejin article
让生活简单点——读《极简生活》小记
何为极简
极简的意义
生命本身没有意义,它的意义由我们自己决定,每个人都可以决定自己生活的意义。曾经听过一个说法:"幻想一个没有你的世界,努力让这个世界和现实世界差距尽可能的大,这就是生命的意义"。对我来说,我期待的理想生活是有平静的内心、健康的身体、充足的财富、家人朋友健康幸福,成为一个永远在前进并影响他人的人。
极简是一种工具。通过这种工具,你能够剔除生活中不必要的人、事、物,从而发现对自己真正重要的东西,并把时间、精力、金钱投入对你真正重要的东西上。极简还能够带来专注力的提升,能够帮助屏蔽大部分无效信息,少看或不看电视剧,很少打游戏,转而去读书和思考。
路遥在《平凡的世界》里面写道:“人们宁愿去关心一个蹩脚电影演员的吃喝拉撒和鸡毛蒜皮,而不愿了解一个普通人波涛汹涌的内心世界。”我愿把更多的注意力用来了解自己这个普通人内心的波涛汹涌,了解我身边重要的人的喜怒哀乐,认真听他们讲话,在他们需要的时候给予力所能及的帮助。
极简的作用
1.省时间
你会重新拥有真正属于自己的时间,而不是你“服侍”物品的时间。因为开始极简生活后,我们会发现自己需要的越来越少,我们会简化自己的物品,而物品简化本身就是一件节省时间的事情。
内心开始渴望一件物品的那一刻起,它就开始消耗我们的时间。选购、比价、看测评、下单、使用、维护、保养、维修,哪一项不需要时间?我们拥有的越多,要“服侍”的物品就越多,我们占有物品,物品也同样占有了我们。当我们舍弃一件物品,少买了一件物品时,我们不仅是“断舍离”了一件物品,更是放下了“选购、比价、下单、使用、维护、保养、维修”的一系列精力成本。
2.省空间
你拥有10000件物品,跟你拥有1000件物品需要的空间是不一样的。当你极简掉自己的物品后,你需要的空间就会少很多。
节省空间,其实也是在节省你的生存成本。空间就是金钱,一线城市的房子每平方米动辄上万元甚至更高。
3.省钱
省钱一定是极简生活最直观、最实在的好处。因为极简,你需要的物品变少,这样本身就省钱。你只留下令你怦然心动的物品在身边,减少更换的次数,也不会再购入不真正需要的东西。
4.发现对你真正重要的东西
极简生活不仅能够节省你的时间、精力和金钱,更能够让你从烦琐复杂的生活中看出对你而言真正重要的人和物品。
每周日是我的周复盘日,在那一天,我会按照“周检视清单”一一复盘我一周的生活。
1.周计划完成情况,工作进度、健身、学习、冥想等
2.周时间使用情况,工作、学习、健身、娱乐时间
3.照片清理
4.联系家人和朋友
5.每周新鲜事物
你可以不用活得稀里糊涂,你可以有另外一种活法,即活得清醒且自知,活得极简且真实。知道自己拥有什么,知道自己需要什么,知道哪些人对自己而言是重要的,知道自己的时间精力要花在哪些地方,知道自己不必为没有发生的事情而担忧,知道自己余生有限,每一天都要认认真真地活。
不管是物质的极简,还是精神的极简,最终都是让我们把关注点放回到自己身上,放回到对我们而言真正重要的事情上。
物质上的极简
理清你有多少物品
一个人一生大概拥有10000件东西,但是人们经常使用的物品只是其中的20%,80%的物品都没有被好好利用起来。如果要统计10000件东西,可想而知是一件多么庞大的工程?
作者举了一个例子:
例如,在你的电脑上建一个excel表格,叫作“我所拥有的每一件东西”。
当我开始整理物品后,我在电脑上建了一个excel表格,叫作“我所拥有的每一件东西”。我把自己所拥有的东西进行分类整理,在这个表格中建立对应的工作表。
所有的物品被我分类为:电子产品、衣服鞋子饰品、学习用品(书籍、本子、笔)、生活用品、彩妆护肤品、厨房用品(因为不做饭,目前厨房用品几乎等于0)六大类。
对我不太适用,我本身东西也没有很多,并且我也已经有了定期清理不需要的物品的习惯,重新梳理一遍我有哪些物品性价比太低。
丢掉不需要的物品
清理物品时,没有实用价值也没有情感寄托的物品可以直接丢掉,比如过期的牛奶、磨损的包包、穿不上的牛仔裤、坏掉的手机、不出油的圆珠笔、已经坏掉的移动硬盘等等。
有实用价值但没有情感寄托的物品,这些是满足我们基本生活需要、实实在在地为我们的生活带来方便的物品。对这些物品我们需要好好利用,并且尽量保持每个物品的数量都是“1”。1是最少的物品数量,你只需要1管牙膏、1瓶洗发水、1个化妆镜、1支钢笔和1根数据线……
处理闲置的方式
送走物品的方式有三种,一种是卖掉,一种是送人,另一种是直接丢掉。我首推卖掉,毕竟可以换点钱,苍蝇腿再少也是肉。发布在闲鱼上的二手物品尽量都写“不议价”,啰啰唆唆的人不卖。
3个常用二手App及使用指南
闲鱼: 闲鱼约等于交易二手物品的淘宝,可以卖的东西特别广泛,小到一支钢笔,大到一所房子。另外,使用闲鱼的用户多,二手商品被看见的机会多,卖出去的可能性也就大。
多抓鱼: 多抓鱼是买卖二手书的平台
只二: 只二是专业的买卖各种轻奢、名牌包包、珠宝首饰、衣服鞋子(以女性为主)的平台。快递同样是顺丰到付。
做一个爱惜物品的人
我们买回来了一件东西,需要使用、保管、保养,思考如何最大限度地延长物品的使用时间,最大限度地使用物品,最大化地利用资源。
不爱惜物品的人的表现是使用物品时不用心,使得物品的折损度高于常人,保管时间短,不是找不到就是遗失,保养更别提了,所以物品的使用寿命在不爱惜物品的人那里就异常短暂。
我们一直在强调人要爱自己,到底什么是爱自己?爱自己是一个抽象的词,总结下来,爱自己是爱自己相关的一切:爱自己的空间,爱自己的身体,爱自己的物品,爱自己所处的关系,爱自己的精神世界,爱自己的时间。我相信,当你开始去爱自己的物品时,你就是在练习爱自己。
爱惜物品的8个小贴士
1.你的物品都是钱买来的,你的钱是你的劳动换来的,你的劳动价值不是取之不尽的,而是非常值得被尊重的。
2.学会不同材质的衣服、鞋子的使用、洗涤和保养指南。
3.物品都应有自己的位置,避免出现忘记物品放在哪里,而又重新买一个一模一样的物品的情况。
4.食品要及时封口并在保质期前吃完。
5.外出就餐时,吃多少点多少,吃不完的食物打包带走。
6.东西一旦坏掉,先考虑修理,再考虑买新的。
7.不需要的物品送人、捐赠或者转卖。
8.用心使用、爱惜生活中的每一件物品,用心使用物品是“术”。
改变,从打扫房间开始
我们想要改变自己的状态,有两种方式:一种是先调整心情,再来调整自己身边的物品和人际关系;另一种是先调整自己的物品和生活,再来调整自己的心情。
一天有24个小时,我们一大半的时间都是在办公室和房间里度过的,办公室是我们认真工作、创造价值感的地方,房间是我们“养”自己、和家人生活的地方。
打扫房间的时候有两个原则:一是最终的效果以房间干净、明亮、无杂物为标准;二是我们的打扫是为了享受,不是为了打扫而打扫。
1.打扫房间是体力劳动,基本无须动脑,可以缓解大脑疲劳。当你感觉用脑过度的时候,就离开电脑去打扫卫生吧!专注于体力劳动,让你的大脑停止思考,休息一会儿吧!已经有研究表明,在经历了长时间的脑力劳动之后,打扫卫生这类的体力劳动是一种非常高效的休息。
2.干净、明亮、无杂物的状态会让你的心情愉悦。面对摆了一床的衣服,塞满东西的房间,连下脚都困难的地方,你的心情不仅不会好起来,还会更加心塞
3.打扫和整理房间跟散步、洗澡一样,是一个放松大脑的活动。
你为什么控制不住买买买
先来普及一个名词,叫作“计划报废”。
“计划报废”就是人为地缩短产品的使用寿命,故意设计容易损坏的产品。所以,你总觉得现在的东西质量越来越差,过去的东西质量好,是有原因的。“计划报废”最早是被应用于灯泡,比如,一个灯泡本来可以使用2500个小时,“计划报废”实施后,寿命只有1000个小时,这样商家就可以卖出更多的灯泡了。
“计划报废”恐怕是行业已经公开的秘密,很多商家心照不宣地实行着“计划报废”,除了灯泡,还有洗衣机中极易损坏的加热元件、装有密封面板无法更换电池的电动牙刷、打印机墨盒等,很多商品都有报废属性。
大部分人认为自己是精明而节俭的消费者,但其实你怎么可能比商人还精明?
优惠券、“双十一”抢购时夸张的规则、买一送一等,让我们以为自己赚到了,其实我们哪里算得过商家?商家的背后有顶尖的心理学家、社会学家、人类学家、营销专家,我们背后有谁?
营销专家也有一套万能公式:给消费者制造焦虑→讲述一些消费者不了解的、可怕的事→介绍一种神奇的解决方法(产品)→说明如果不使用这款产品,你就会陷入危险。例如除菌产品就是一个典型的例子,卫生问题处理不好会让人生病,生病会带来危险。为了牟利,商家利用人的本能,生产和销售大量除菌产品,其营销思路为:大肆宣传细菌的危害,让人们觉得细菌会蔓延和感染并危及生命,而作为一个个体,不使用可以洗掉99%细菌的除菌皂,你就很有可能会感染细菌,进而危及生命。
精神上的极简
朋友也要区别对待
极简是一种生活方式,也是一种生活态度。只要不是在原始森林独居,你活着就要跟人打交道。生活中大部分的幸福和不幸都是来自人与人之间的化学反应,人真的是一个很神奇的物种。
理想的情况是,对重要的人投入重要的精力,远离消耗你的人。然而现实和理想往往是相反的。现实生活中,很多人花了太多的力气在糟糕的人际关系上,努力去讨好不喜欢自己的人,拼命想要给看不起自己的人证明自己能行,想要让离开自己、背叛自己的人后悔,却忽略和漠视了那些真正在意自己、重视自己的人。
我们可以按照重要程度把我们的好友分为三大类。
第一类:重要他人,包括无条件支持我们的家人,无话不谈的朋友,困难的时候给予我们帮助的贵人。
第二类:普通友人,包括曾经愉快相处过如今来往较少的朋友,一起工作的老板和同事,来往较少的亲戚。
第三类:“忽视”友人,平常几乎0接触,最多朋友圈偶尔点个赞的点赞之交。
第四类:“需要远离”的人,那些一直给我们带来负面影响但是没舍得删除的朋友,情绪黑洞,这辈子都不会往来的人,等等。
专注于自己,而不是聚会
我们需要人脉、需要伯乐、需要机遇,但是如果我们没有真本事,就像创业者没有好的产品,再厉害的人脉也帮不了我们,即使帮得了我们一时,也帮不了我们一世。
什么叫作人脉?人脉不是你都认识谁,而是当你遇到困难的时候,谁愿意帮你,你也愿意给予对方帮助,这才叫人脉。
让自己变好,是解决一切问题的关键。当你变得足够好,自然会吸引优秀的人,会遇到贵人,会进入更优质的圈子,会有属于你自己圈层的人脉。
无意义的聚会既浪费我们的时间,又消耗我们的精力,还没有任何回报,就像只在饭桌上称兄道弟的酒肉朋友,没有什么益处。
首先,我们要学会鉴别什么是真正对我们有帮助的朋友,哪些是真朋友,哪些是酒肉朋友,不断打磨自身的能力,提高自己的专业水平。
其次,在人与人的相处中,我们要更多地思考“利他”而不是“索取”。思考这个人是不是需要我的帮助,我能够帮助他什么,我能够带给他什么价值。
当你发自内心地帮助他人,给予他人更多关心,为他人带来价值,成就他人的时候,他们才是你的人脉,你想要的机会和财富自然也会随之而来。
远离让你觉得不舒服的人
我交朋友有一个原则,一个人只能有一次恶心我的机会。当我们不熟时,如果这个人做了一件让我觉得很恶心、能够反映出他的人品、认知、道德底线有问题的事,那我不可能再给他任何接近我的机会,一般是直接删除,断开所有链接。如果是熟人,那么我会主动疏远,但是能成为我的熟人一般人品已经过关了,大概率没有恶心我的机会。
对于任何一个人来说,情绪都是底层逻辑。后天学习的东西都是理性,理性是把人往回拉的力量,但是驱动一个人的,其实是他的内在感受和情绪。
我们控制不了天气,但我们可以选择周围环境,选择看到的信息以及接触到的人。在所有影响情绪的因素中,人又是对情绪影响最大的因素。
你身边一定有这样充满负能量的人:自怨自艾,喜欢搬弄是非,背后说人坏话,一张嘴不是叹气就是抱怨,甚至通过贬低和打压你显示自己很强。这样的人,你每次跟他相处后,就像生了一场大病,需要三五天才能恢复能量。
“关注即强化”。关注负能量的人,就会吸引更多的负能量来自己身边。一个心里有怨言、嘴上爱抱怨的人,是积极不起来的。
使用极简帮助管理精力
潜意识里面,大部分人把忙碌和事业有成、功成名就等词语挂钩,而这也是很多人一直渴望的状态。但是实际上,他们要追求的是井然有序的高效生产力,而不是简单的“忙碌”两个字。
忙碌是一种状态,从容也是一种状态,忙碌与你的成就高低、工作努力程度、生活认真与否并没有直接的关系。
《巨人的工具》这本书里,作者采访的名人之一德里克·希维尔斯说:“什么是忙碌?‘忙碌’可能意味着‘失控’。比如,‘天啊,我太忙了,我没时间做这件事!’这句话在我听来就像是一个无法控制自己生活的人才会说的话。
以前我们总认为,金字塔顶端的人都是很忙碌的,长大了才明白,那些生活在金字塔顶端的人不是忙碌,而是有节奏、有计划地高效工作和生活。他们每天会按照小时、半小时甚至15分钟的时间颗粒来规划,高效地平衡工作和休息,专注地在每个时间段做规划好的事。他们很少拖延、纠结、犹豫,而我们大多数人花了太多的时间在犹豫、纠结、拖延、玩手机,真正做事的时间少之又少,还给自己造成一种忙碌的假象。
忙碌只是一种状态,是一个修饰词,你也可以选择从容地认真、从容地努力、从容地成功。
如何不再忙碌,优雅从容的掌控生活?
1.要有计划
小的计划可以是你今天的下班时间是几点,为了实现准时下班,你必须完成的事情是什么?以及下班之后到睡觉前,你要完成的事情,如健身30分钟、写一篇文章、洗澡。或者今天是放松日,下班后到睡觉前的自由时间,你允许自己玩手机放松,这也是计划。但是切勿把放松当作常态,哪怕是休息,你也要意识到自己是在休息。
大的计划可以是你这个月的工作KPI是多少?为此你每周需要完成多少业绩?这样计划好以后,你就不会再头疼自己今天该干什么,明天该干什么,毫无计划性,或在背后责怪老板太苛刻,给自己的压力太大了。如果你不知道你的KPI,可以明确地去问老板。
2.提高工作效率
培养抗干扰能力。干扰分为两种,一种是来自自己内部的干扰,另一种是外部的干扰。
内部的干扰,如工作时想要玩手机,对于这种情况你可以设定在完成某个任务后,奖励自己玩手机10分钟等措施,来和大脑谈判。工作时你的大脑可能会冒出来很多别的念头,有时候会想起一些事。这个时候不要马上去做这些事,先记下来,完成手头上的事情之后,再去一一处理。
外部的干扰是考验你的问题处理能力。任何人找你,你都可以告诉他你现在在忙,等你忙完手头上的事情再找他。如果手上的工作两三分钟之内可以处理完,你可以当场判断是拒绝他还是答应然后让他等待。
3.拒绝拖延症
真正让你忙碌的并不是事情本身,而很可能是做事之前的拖延和纠结。拖延症不是懒惰的表现,而是在你面临压力时的应对机制。当我们在拖延的时候,我们逃避的不是事情本身,而是压力。
下一次当你拖延的时候,你要知道,你的拖延正是你不能准时下班,忙忙碌碌却不知道自己做了些什么事情的原因。你可以直接采用《5秒法则》这本书里提供的方法:“屏蔽掉你的想法和行动之间的感受,倒数5、4、3、2、1,go!”生命这么短暂,我们不妨大胆一些。
你真的知道怎么休息吗
松浦弥太郎的《新100个基本:自我更新指南》里面有这样两句话:
“严格来说,身穿睡衣一天无所事事的状态,不算休息。”
“休息日,需要早起更衣、三餐不落,晚上早睡,身心愉悦,‘散漫’和‘休息’完全属于两种不同的行为。”
我们所有的休息都逃不出这两个目的:恢复体力和恢复脑力。其中很关键的是恢复两个资源——“注意力”和“意志力”。所以,一切消耗我们注意力和意志力的事情,都不是真正的休息。上网看新闻,上微博追热点,这些会占有我们的注意力;判断这些信息的真实性、判断电视剧中人物的好坏等需要消耗我们的意志力。
看肥皂剧、刷朋友圈都属于被动休息,被动休息能够带来短暂的多巴胺递质增加,多巴胺能够带来一定的愉悦感,但它属于递质类愉悦因子,有效性非常短。锻炼和休息属于主动休息,主动休息能够提高催产素水平,催产素属于激素类愉悦因子,它带来的时效会更长,当我们再次投入工作和学习中去,它还能继续发挥作用。
人类的左脑负责语言、阅读、思考和推理;右脑负责理解空间位置关系、模式识别、绘画、音乐和情感表达。当你阅读的时候,你在用你的左脑;当你构思图画和分类时,你在用你的右脑。你用左脑时,右脑在休息;你用右脑时,左脑在休息。做需要左右脑同时工作的事情,你可以通过停下来散散步、四处走走、游个泳来休息。当你写文章累了,算一下数学题就会跟换了个脑子一样清醒;当你在办公室没思路时,站起来活动活动,然后再回到办公室就会像脱胎换骨。
脑子累了,干点儿体力活;看书累了,就去游泳,或者以散步、做家务、洗澡等转移注意力,放松回来后还能再写一个方案;身体累,就去睡觉。
在睡觉这件事上,你的大脑白天休息20分钟就可以迅速恢复精力,很多牛人一天会睡好几次半个小时,也都有午休的习惯,就是这个道理。
每年100多天的假日,给自己一个承诺,你要高质量地休息。
总结高质量休息的几条路径
- 养成每天午休的习惯。
- 白天实在感到太累的话,也可以睡一觉,20~30分钟为好。
- 轮休:写文章累了,换成背英语单词;背英语单词累了,那就换成做数学题。
- 感到精神疲倦的时候,就去户外散步、洗澡、烘焙、做家务等,让大脑休息。
- 远离各种内容平台和热点事件,严格来说,任何需要用到脑力、接受信息的活动,都不算休息。宁愿放空发呆,也不要拿起手机刷朋友圈、热点等消耗更多的精力。
- 感到疲倦的时候,去做自己喜欢平时却没有时间做的事情,全然地沉浸其中。
- 休息日照样规律作息,不要熬夜赖床。
- 每个休息日都需要一定量的运动或者体力劳动
juejin freebie
手机也能跑大模型?DeepSeek-r1 部署教程来了!
现在,大家用手机的时间越来越长,对隐私安全的关注也越来越高。各大厂商也在琢磨,怎么才能让大模型直接跑在手机上。这几天写文章时,发现不少小伙伴都在问:怎么在手机上部署 DeepSeek?
既然大家都感兴趣,那今天就把我之前折腾的部署步骤整理出来,分享给大家,希望能帮到你!
在 Android 手机上运行 LLM****安装指南
1. 安装 Termux 应用
安装有两种方法,如果第一种能用,别浪费时间试第二种。
- 打开Termux GitHub Releases页面
- 下载
termux-app_v0.119.0-beta.1+apt-android-7-github-debug_arm64-v8a.apk。 - 安装 APK 文件。
2. 运行 Ollama 服务器前的环境配置
打开 Termux 后,你会看到一个看起来像 Linux 终端的界面。接下来,我们需要配置 Ollama 运行环境。
- 先授予存储权限:
termux-setup-storage
运行后,让 Termux 能够访问你的 Android 存储系统。执行后,系统会弹出“设置”应用,找到 Termux 并手动授予存储权限。
- 更新软件包
在安装任何工具之前,先更新软件包,就像在 Linux 上做的那样:
pkg upgrade
执行后,如果提示Y/N,直接输入Y并回车。
- 安装 Git、CMake 和 Golang
这些工具是下载和构建 Ollama 所必要依赖:
pkg install git cmake golang
3. 安装并构建 Ollama
- clone Ollama GitHub 仓库
如果你经常使用 Termux,可以先进入你想安装 Ollama 的目录;否则,直接执行以下命令:
git clone --depth 1 https://github.com/ollama/ollama.git
- 进入 Ollama 目录
下载完成后,切换到 Ollama 目录:
cd ollama
- 生成 Go 代码并构建 Ollama
运行以下命令,先生成 Go 代码:
go generate ./..
然后编译 Ollama(这一步耗时比较久,需要一点耐心):
go build .
等待构建完成后,我们成功在手机上安装 Ollama!
4. 运行 DeepSeek 模型或其他小型模型(1B 或 2B 参数)
选择一个合适的模型
注意:参数超过 3B(30 亿)的模型在手机上运行太慢,甚至可能无法加载进显存,所以别折腾太大的模型。
进入Ollama模型库,寻找适合手机的小型语言模型(SLM,Small Language Models)。一旦找到合适的模型,就可以开始跑 本地模型 了!
在 Ollama 模型库 页面,你会看到一个“复制”按钮(如果用手机访问,看不到的话,切换到“桌面视图”模式)。点击复制,等会儿我们部署时可以用的上。
- 下载并运行模型
这里以DeepSeek 1.5B模型为例,当然你可以选择其他模型,步骤都是一样的。
- 运行 DeepSeek 1.5B 模型:
./ollama run deepseek-r1:1.5b --verbose
运行你自己选择的模型(如果你是选择其他模型时请输入对应的命令):
./<刚刚从 Ollama 官网复制的命令>
等待下载完成
这个命令会开始下载模型到你的手机上,请耐心等待。下载时间取决于你的网速,如果你用的是移动数据,确保至少还有 1.5GB 流量,否则容易翻车!
开始使用 LLM
下载完成后,Termux 终端里会出现交互界面,你可以像在 PC 上那样使用 LLM。不过别对性能抱太高期待,毕竟这是在手机上运行的“小型”模型,速度肯定比不上 ChatGPT。
Cursor初体验
某天老板在群里统计大家目前使用的开发工具,我回答说是VS Code,老板再问:“为啥不用Cursor?”
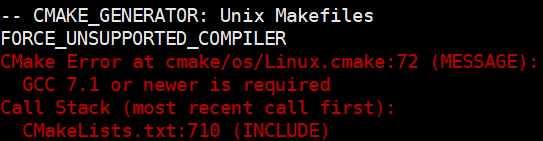
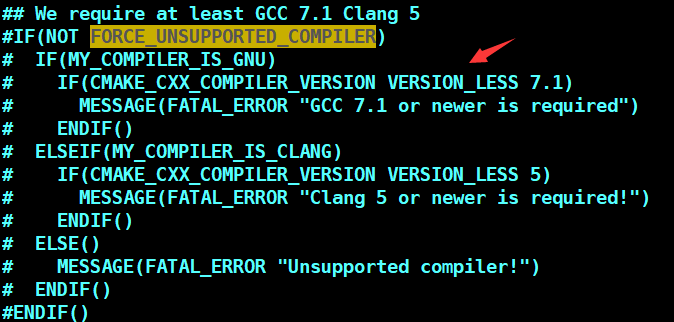
阻拦我尝试Cursor的那个报错
老板的提问是一个引子,解决掉——其实就只是将Cursor更新到最新——该报错之后,我便开始使用Cursor。两个月过去,我使用Cursor越来越重度,到现在,我想将目前使用Cursor的感受先记一记,于是有此篇。
一、初次使用个人感受
可以使用Cursor当天,我并不知道它有什么功能,只在Cursor中(之前是在VS Code中)继续完成我的一个小小测试脚本,我没想到的是,它的tab功能如此强大。如下图,那种仿佛可以预知我想法的代码补全,让我深感诧异。(对的,在我试用Cursor过程中,GitHub的Copilot也已经能免费使用,不过目前我看到的效果是,它在准确性上不及Cursor。)
Cursor的tab功能
这是一种发现新大陆的惊喜,我甚至开始怀疑,我是不是可以完全抛弃VS Code了。(好吧,这一句有点傻傻的话,是在Cursor中编辑时点按tab出来的,我并没有抛弃VS Code。不抛弃的原因是,同时打开两个应用,一个用来写一个用来看,切换起来方便许多。)
Cursor主要功能分为两种(此处严谨些,或许只是我目前使用到的):
- 代码补全,如上图,在编辑过程中,它会依据上下文,自动补全代码;
- 代码生成,我们可以在某个输入框当中,输入想要做的事情,它会根据输入,再结合整个项目中的上下文生成代码;(关于整个项目,我使用的是Privacy mode,所以还未感受到它的完全体功能:如果上下文更多些,生成出来的代码会更准确。)
需要诚实些的是,我初初使用Cursor时,是真以为它是免费的。但只使用大概5天,免费额度便已经用完。
二、薅羊毛
(这个标题,是Cursor帮我生成的。)
薅羊毛的方法,其实也是简单的,免费额度到期后,可以这样操作:
- 在网站
https://temp-mail.org/en/上生成一个新的邮箱,使用这新邮箱登录(temp-mail广告挺多,直接在其主页中间框框中收验证码即可); - 再修改下自己机器上Cursor使用的配置文件;
一张介绍修改机器的图片
修改自己机器上的Cursor配置文件,会有些麻烦,我甚至用Cursor帮我写了一段小小代码:
import os
import json
import uuid
import secrets
def generate_hex_string(length):
"""生成指定长度的十六进制字符串。"""
return secrets.token_hex(length // 2) # token_hex()接受的是字节数,一个字节等于两个十六进制字符
def modify_json_file(file_path):
# Change file mode to 666
os.chmod(file_path, 0o666)
# Read the JSON file
with open(file_path, 'r') as file:
data = json.load(file)
# Generate two different 64-bit hex numbers
hex1 = generate_hex_string(64)
hex2 = generate_hex_string(64)
# Ensure the two hex numbers are different
while hex1 == hex2:
hex2 = generate_hex_string(64)
print(hex1)
print(hex2)
# Generate a UUID
uuid_str = str(uuid.uuid4())
# Replace the telemetry fields
data['telemetry.macMachineId'] = hex1
data['telemetry.machineId'] = hex2
data['telemetry.devDeviceId'] = uuid_str
# Write the modified data back to the JSON file
file_path_new = f"{file_path[:-5]}_new.json"
os.chmod(file_path_new, 0o666)
with open(file_path_new, 'w') as file:
json.dump(data, file, indent=4)
os.chmod(file_path_new, 0o444)
if __name__ == '__main__':
modify_json_file('./storage.json')
接着,再将替换掉机器码的配置文件替换到Cursor的配置文件中,便可以开始新的体验之旅……
三、初次付费
薅羊毛,到底是有些不太方便的,每次过期之后都会点开Cursor的升级页面看一看,我内心想要付费使用的渴望,越来越强……
只是每次都被每月20刀吓退。
20刀,用不起,20RMB呢?好像是可以接受的。
我第一次花钱,是在咸鱼花22块钱买一个体验号,商家说可以用一个月,好评再赠送15天。
当我真正用起来后,发现这种体验模式纯纯是骗小白钱,商家帮我做的事情,只是申请一个邮箱而已,体验过期之后,我依然需要换邮箱换机器码。(啊哈,写这一段时,我有些生气,甚至想去找老板退钱……由此,我的建议是,大家如果买号使用的话,请不要买体验号。)
Pro账号的界面,长这样子
我第二次花钱,是一周之前。我将自己“很想付费使用”的想法在掘金沸点上表达,掘友们给我的建议是:去淘宝买共享号就好。
我上淘宝搜Cursor,找到销量第一那家店,花25块钱买一个月的3人共享号。
目前使用一周,只感觉好香好香!
四、使用感受
我现在敲代码,也大概分作两个方向:
- 项目代码,那些真正会用到我们产品中的内容;
- 测试与统计工具,测试用作某些技能的预研,统计用于代码上线之后的观察与调整;
项目代码不多说,我只需要写主要逻辑就好,那些log、异常、格式、甚至一些我没有考虑到的逻辑分支,Cursor都帮我完成。
我想要多聊聊的,是测试与统计工具。在写这些测试工具时,我是只用Cursor的代码生成的,即给一段话,让Cursor帮我生成相应功能的代码,这一段话,大概是这样的:
帮我写一个函数,这个函数的输入是这样的log文件,它的格式是
timestamp, user_id, action, used time 0.2359 xxxx这样的,这个函数需要做的事情是根据user_id,统计出这个用户在一天中,使用最多的action,我需要看时间的均值、方差,另外,再帮我生成一个图表。图标具体形式是怎样的我不太懂,但是我需要直观的看出来哪个action使用时间最长,哪个user_id使用最多。
这段话写完之后,Cursor就会帮我生成一个很长的函数。
接下来做的事情,我只需要测试代码是否生成正确,然后,再根据我自己的需求,进行调整就好。
上面过程当然是完美的,当看到那许多数据,都用直观图表展现时,我内心是很满意的。
不完美的地方,有两点:
一是Cursor生成的用作我自己测试的代码,我并不关注它的写法好是不好,我不关注是否可以复用,甚至它内里具体怎样完成我也不关注,这导致的问题是,在我需要对测试做些调整时,我只能再次借助Cursor,而当调整变多时,代码就变得越来越臃肿,更甚者,我会怀疑整段代码得出结论的正确性。
第二个不完美的地方,其实与Cursor无关,而关于我自己知识的储备。以上面一段话作为示例,Cursor帮我生成的图表中,有些很直观,有些我认为还可以做些改进,但其实我,并不知道改进的方向是怎样的,由此,我也并不知道该给予Cursor怎样的提示词。这就是,我有一个万能小助手,却只能让它帮我做些类似洗碗切菜这样的简单事。
Cursor很厉害,但要用好它,我依然需要学习很多。学习,又大概分作两个方向:一是提升自己知识的广度,让自己能够给予Cursor更多相对准确些的提示词;二是提升架构层面的能力,毕竟现在写代码有骨架之后,填肉这件事,让Cursor做就好。
以上,是我使用Cursor两个月所拥有的体验:工具真好用,但自我提升还不能停……
oschina news project
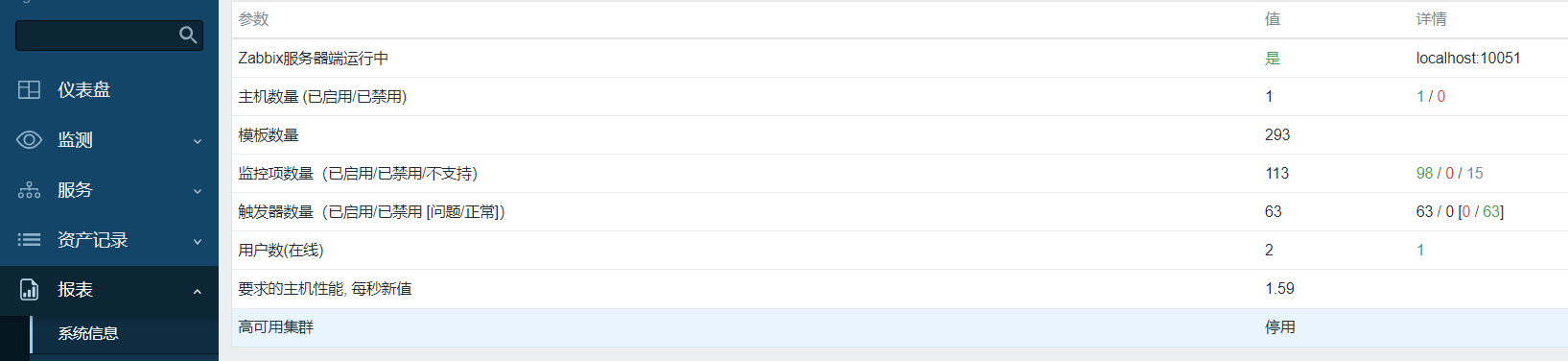
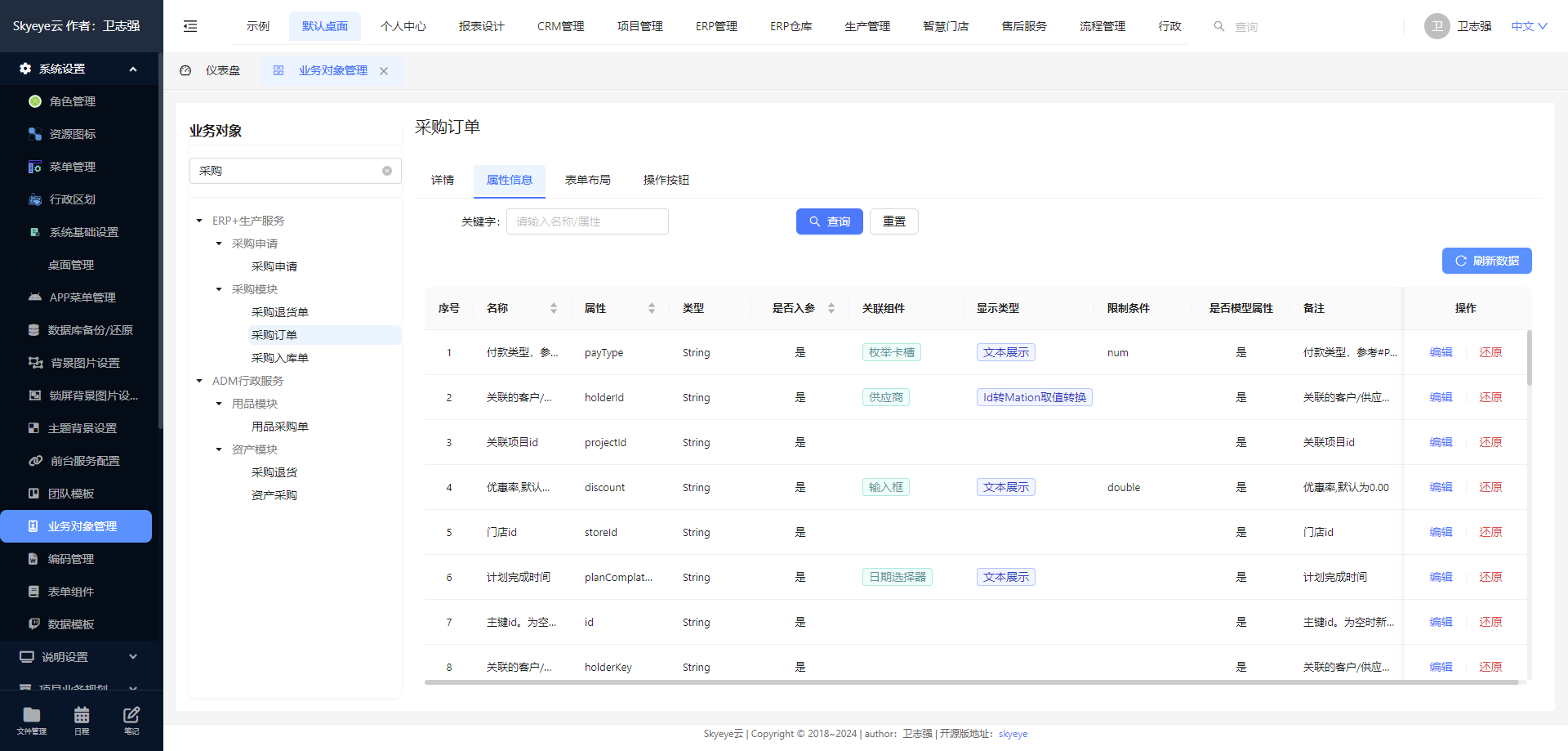
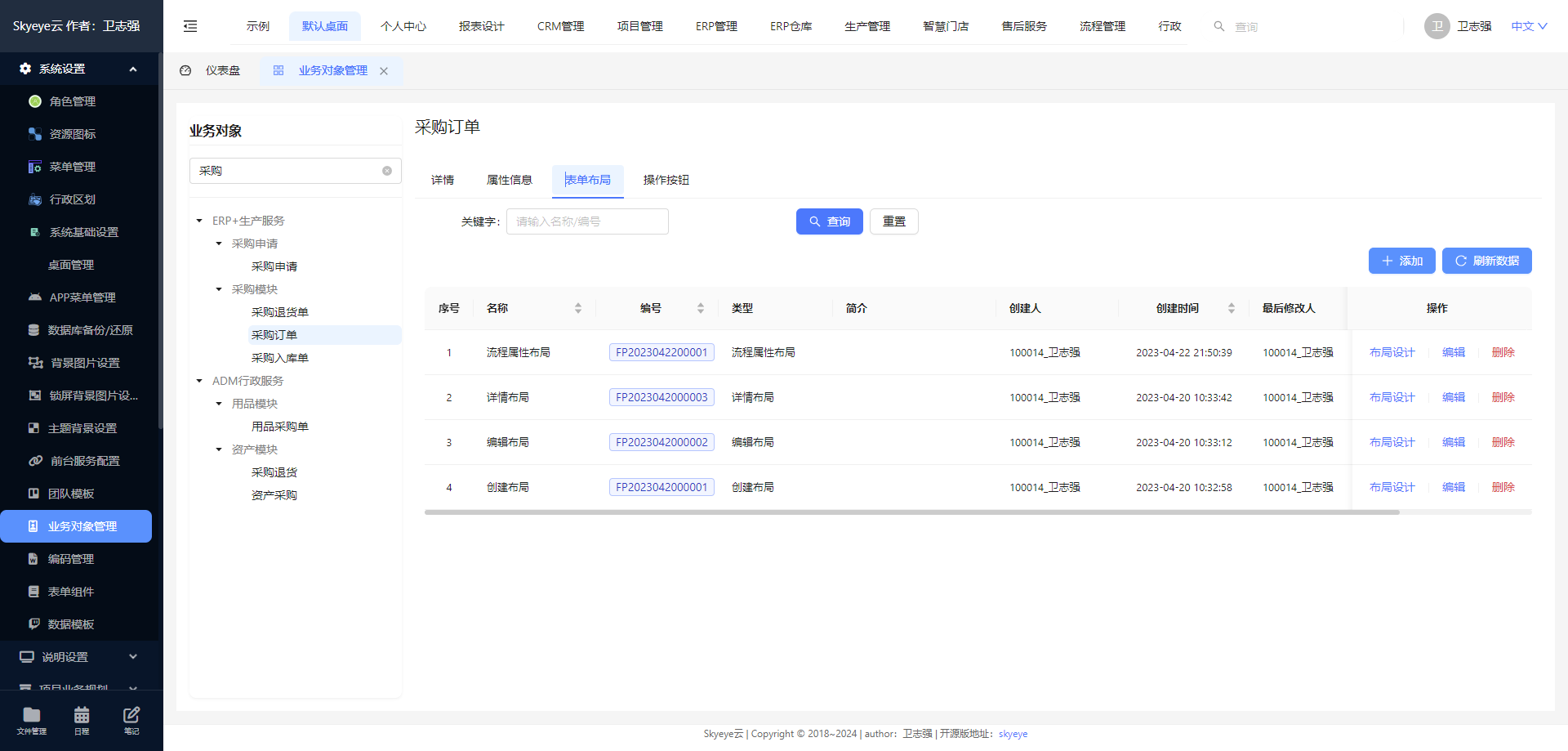
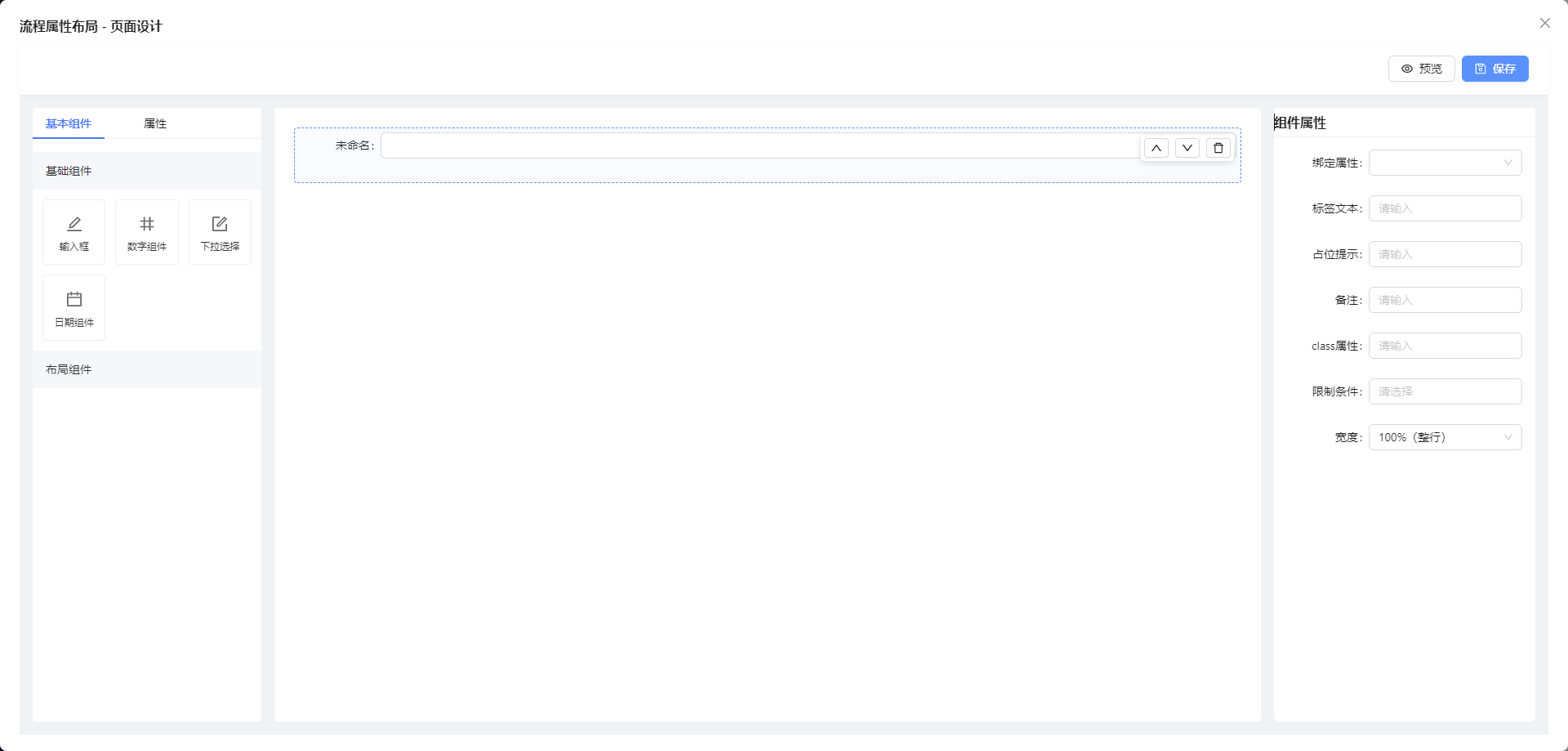
Skyeye 云 VUE 版本 v3.15.6 发布
Skyeye 云智能制造,采用 Springboot + winUI 的低代码平台、移动端采用 UNI-APP。包含 30 多个应用模块、50 多种电子流程,CRM、PM、ERP、MES、ADM、EHR、笔记、知识库、项目、门店、商城、财务、多班次考勤、薪资、招聘、云售后、论坛、公告、问卷、报表设计、工作流、日程、云盘等全面管理,实现智能制造行业一体化管理。实现管理流程 “客户关系 -> 线上 / 线下报价 -> 销售报价 -> 销售合同 -> 生产计划 -> 商品设计 -> 采购 -> 加工制造 -> 入库 -> 发货 -> 售后服务” 的高效运作,同时实现企业员工的管理以及内部运作的流程操作,完善了员工从 “入职 -> 培训 -> 转正 -> 办公 -> 离职” 等多项功能。
常见问题 开发文档
Skyeye 云【源代码】针对 {星球用户} 开源。拿到源码后可进行学习、毕设、企业等使用。
Skyeye 云智能制造 v3.15.6 发布 ,发布内容如下:
- Skyeye 云已加入 Dromara 社区
- VUE 版 Skyeye 云
-
全部使用低代码【列表布局】的页面重构完成
-
已重构 33 个组件,VUE 版重构进度可参考:https://kdocs.cn/l/cbf2cgCLrUyz
-
解决 Layui 版本存在的问题
-
重构已办事宜
-
重构我的请求
-
用车申请
-
用品领用
-
我的用品领用历史
-
印章借用,印章归还、我借用中的印章
-
证照借用、证照归还、我借用中的证照
-
HR人员需求申请单
-
我负责的人员需求
-
门店会员
-
门店商品库存
-
门店商品分类管理
-
- VUE 版 Skyeye 云
开始开发,已完成 100+个组件的开发
- 源代码对星球用户开放
-
解决若干问题。
Skyeye 具备低代码、快捷开发、可视化设计、微服务等特点,方便客户二次开发,极大的提高了开发效率。
erp: https://gitee.com/doc_wei01/skyeye
OA: https://gitee.com/dromara/skyeye
报表:https://gitee.com/doc_wei01/skyeye-report 有问题可以联系作者,详情请看开发计划。
PC 端效果图
| 效果图 | 效果图 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|


移动端效果图
| 效果图 | 效果图 | 效果图 | 效果图 |
|
|
|
|
|




juejin backend
简易好用的加密算法 - BCrypt加密算法
我以前使用的都是md5加盐存储用户密码,但是我们老师说md5不安全。然后我开始找一个相对安全的加密算法,最后找到了
BCrypt算法。
如果在Java中想使用BCrypt加密算法,有两种途径:
- 使用
springsecurity - 使用
org.mindrot.jbcrypt
我这篇文章用org.mindrot.jbcrypt演示BCrypt加密算法的使用。
1.创建简单的maven项目
项目结构:
pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.akbar</groupId>
<artifactId>bcrypt-project</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<!--引入jbcrypt坐标-->
<groupId>org.mindrot</groupId>
<artifactId>jbcrypt</artifactId>
<version>0.4</version>
</dependency>
</dependencies>
</project>
2.使用bcrypt算法
package com.akbar;
import org.mindrot.jbcrypt.BCrypt;
public class Main {
public static void main(String[] args) {
String password = "123";
// 生成加密哈希
String hashed = BCrypt.hashpw(password, BCrypt.gensalt());
System.out.println(hashed);
// 验证密码
boolean match = BCrypt.checkpw(password, hashed);
if (match) {
System.out.println("密码正确");
} else {
System.out.println("密码不正确");
}
}
}
3.jbcryp关键方法
| 方法 | 作用 |
|---|---|
hashpw(String password, String salt) | 使用 salt 对 password 进行加密 |
gensalt(int log_rounds) | 生成带有 log_rounds 计算成本的 salt |
gensalt() | 生成默认 10 轮加密的 salt |
checkpw(String plaintext, String hashed) | 验证 password 是否匹配 hashed |
gensalt()解读
gensalt() 是 bcrypt 计算的核心,决定了哈希强度。
默认使用:
String salt = BCrypt.gensalt(); // 默认 log_rounds = 10
System.out.println("Salt: " + salt);
自定义计算成本:
String salt = BCrypt.gensalt(12); // 使用 12 轮计算成本
System.out.println("Salt: " + salt);
gensalt(12) 计算成本 12,比 10 更安全但计算更慢。
checkpw() 如何验证密码
String password = "123";
// 生成加密哈希
String hashed = BCrypt.hashpw(password, BCrypt.gensalt());
// 验证密码
boolean match = BCrypt.checkpw(password, hashed);
🔹 不能直接用 equals() 比较密码,因为 bcrypt 每次生成的哈希都不同。
🔹 checkpw() 内部会自动解析 salt 并进行比较。
hashpw() 解析哈希格式
bcrypt 生成的哈希是 60 个字符的字符串,格式如下:
$2a$10$qO6PDKpRBK6N7d8GxOpCAO58wSINRdBSQ4kB2Jm3y85nKuqcqdSxa
解析结构(为了容易区分,用空格隔开):
$2a$ 10 $qO6PDKpRBK6N7d8GxOpCAO58wSINRdBSQ4kB2Jm3y85nKuqcqdSxa
│ │ │ └─────────── 哈希值(bcrypt 计算后)
│ │ └─────────── Salt(前 16 字符)
│ └────── 计算成本(log_rounds = 10)
└──── bcrypt 版本号($2a$ 代表标准 bcrypt)
🔹 bcrypt 的特性: 即使 password 相同,每次哈希都不同。
🔹 安全性来源:哈希值包含 动态 salt,所以无法用 hashmap 预计算彩虹表攻击。
juejin android
Now In Android 精讲 6 - UI Layer
界面层(UI Layer)概览
界面层的主要作用是展示数据,并且响应用户交互。下面的界面层官方架构图告诉我们,界面层是属于整个应用的最上层,他主要由 UI element 和 state holder 组成。 UI 元素通过从 State holders 获取 State 从而向用户提供可交互的 UI,那么什么是 State?
UI state 定义
if the UI is what the user sees, the UI state is what the app says they should see. Like two sides of the same coin, the UI is the visual representation of the UI state. Any changes to the UI state are immediately reflected in the UI.
官方对 UI state 介绍非常抽象,换成通俗意义上的话来说,UI 是给用户看的,UI State 是给 app 看的。UI state 首先告诉 app,app 才能告诉你该长啥样。
那么通常一个 UI state 应该长啥样?举个例子:
val topicUiState: StateFlow<TopicUiState> = topicUiState(
topicId = topicId,
userDataRepository = userDataRepository,
topicsRepository = topicsRepository,
)
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = TopicUiState.Loading,
)
一般来说 UI state 首要满足的就是不可变对象,多数情况我们使用 val 对外提供一个不可变的对象,其次他的命名习惯的是:功能 + UiState。例如在本例中是一个 topic 相关的状态,那么项目里面起名就叫 TopicUiState。
如何管理 UI state?
整个应用如上图所示,都应该遵循 Unidirectional Data Flow (UDF) 来管理 UI state, 按照图中所示即是:状态向下传递,事件向上传递。我们换种方式来理解即是,UI state 负责驱动 UI 的变化,但是 UI 的修改需要通过 event 传递给上层处理。state 跟 event 他们一个负责通知 UI 的变化,一个负责传递用户意图。单项数据流很好的把他们的职责分离出来。
NOTE:我们在谈论单向数据流的时候不要脱离了 UI layer,如果你在其他层,例如 Data layer 或是 Domain layer,我想是一件不合适的事情,因为他们本身就需要从本地获取/发送数据,进行各种复杂的交互。
通过 Now In Android 里面的代码来学习如何向外提供数据流
val uiState: StateFlow<InterestsUiState> = combine(
selectedTopicId,
getFollowableTopics(sortBy = TopicSortField.NAME),
InterestsUiState::Interests,
).stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = InterestsUiState.Loading,
)
sealed interface InterestsUiState {
data object Loading : InterestsUiState
data class Interests(
val selectedTopicId: String?,
val topics: List<FollowableTopic>,
) : InterestsUiState
data object Empty : InterestsUiState
}
一般来说我们通过向外暴露一个 StateFlow 类型的可观察数据流,对外提供不可变的数据。在应该也会有一些小伙伴在平时写的时候会贪图省事,使用 MutableStateFlow ,这样既可以操作,又可以提供数据,这样其实是破坏封装的,向使用方提供了过多的能力,会使得代码维护变得困难。
如何合理的提供 state?
- 首先 state 内部的各个 property 应该有相关性,举个例子:上面的代码 InterestsUiState 里面 Interests 提供的都是 Interest 相关内容,如果里面提供了订阅的信息,那应该甚为不妥。其次如果 state 某个 property 更新频率很高,那么 state 更新频率会变的很高,会引起很多 compose 不必要的重组,降低 UI 性能。这时候可以选择将这个 property 单独提取出去,再行暴露给调用方。
- 尝试使用
distinctUntilChanged(),或者其他操作符减少不必要的更新
如何理解 Event?
我们先看一段官方的介绍
UI events are actions that should be handled in the UI layer, either by the UI or by the ViewModel.
Event/事件 是 UI 层应该处理的操作,注意这里面说的 UI 层而不只是 UI element,他可能是 UI 亦或是 ViewModel。
Event 有哪些类型?
-
viewmodel 事件:ViewModel 事件应始终会引发界面状态更新。这里面官方文档的中文翻译 有一处不够准确, 英文原意是:Consuming events can trigger state updates,翻译成中文就变成了:使用事件可能会触发状态更新。can 这个词翻译成
可或者是能都行,唯独可能不行,这地方语义应该翻译成会。 -
导航事件:调用导航控制器路由到指定 composable screen。
参考下面项目里面的代码 onTopicClick = navController::navigateToTopicfun NiaNavHost( appState: NiaAppState, onShowSnackbar: suspend (String, String?) -> Boolean, modifier: Modifier = Modifier, ) { val navController = appState.navController NavHost( navController = navController, startDestination = ForYouBaseRoute, modifier = modifier, ) { forYouSection( onTopicClick = navController::navigateToTopic, ) ... interestsListDetailScreen() } }
状态容器与状态管理
逻辑
从前面一节里面我们学习到,状态是由事件驱动的,一般由 viewmodel 进行更新,用通俗的话来讲事件调用的负责更新或者生成新的状态的流程我们称之为 逻辑。
上面一节讲到了事件有 viewmodel 事件和导航事件,一般我们把 viewmodel 事件触发的逻辑称之为业务逻辑,导航事件触发的逻辑称之为界面逻辑。业务逻辑通常不依赖具体的生命周期(你是不是从来没在 viewmodel 里面依赖过 lifecyle 之类的代码),界面逻辑依赖生命周期(页面没了逻辑自然也不能执行)。
状态容器
一般来说,如果不是非常简单的界面,我们都会有一个状态容器来存储状态。然后与逻辑类似,不依赖界面生命周期的称之为业务状态逻辑容器,依赖界面的我们称之为界面状态逻辑容器。
业务逻辑状态容器 ViewModel
平时我们接触到最多的 viewmodel 就是业务状态逻辑容器,这个应该很好理解,viewmodel 本身不依赖界面,他依赖上游的 Data layer 或是 Domain layer 的能力,保存状态,作为业务逻辑的中转站而存在。(在依赖关系里面是 viewmodel 处于 UI 的上游,一般由 fragment 或者 compose 依赖 viewmodel,所以他的生命周期往往要长于 UI)
看个例子:
class InterestsViewModel @Inject constructor(
private val savedStateHandle: SavedStateHandle,
val userDataRepository: UserDataRepository,
getFollowableTopics: GetFollowableTopicsUseCase,
) : ViewModel() {
// Key used to save and retrieve the currently selected topic id from saved state.
private val selectedTopicIdKey = "selectedTopicIdKey"
private val interestsRoute: InterestsRoute = savedStateHandle.toRoute()
private val selectedTopicId = savedStateHandle.getStateFlow(
key = selectedTopicIdKey,
initialValue = interestsRoute.initialTopicId,
)
val uiState: StateFlow<InterestsUiState> = combine(
selectedTopicId,
getFollowableTopics(sortBy = TopicSortField.NAME),
InterestsUiState::Interests,
).stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = InterestsUiState.Loading,
)
fun followTopic(followedTopicId: String, followed: Boolean) {
viewModelScope.launch {
userDataRepository.setTopicIdFollowed(followedTopicId, followed)
}
}
fun onTopicClick(topicId: String?) {
savedStateHandle[selectedTopicIdKey] = topicId
}
从上面的例子我们可以看到一个典型的 viewmodel 可能要处理页面重建,负责与 Data layer 以及 domain 交互,UI 提供 state 的职责,是一个非常重要的角色。
如何在 UI 中使用 state 和调用业务逻辑?
我们先看一段项目里面的代码:
@Composable
fun InterestsRoute(
onTopicClick: (String) -> Unit,
modifier: Modifier = Modifier,
highlightSelectedTopic: Boolean = false,
viewModel: InterestsViewModel = hiltViewModel(),
) {
val uiState by viewModel.uiState.collectAsStateWithLifecycle()
InterestsScreen(
uiState = uiState,
followTopic = viewModel::followTopic,
onTopicClick = {
viewModel.onTopicClick(it)
onTopicClick(it)
},
highlightSelectedTopic = highlightSelectedTopic,
modifier = modifier,
)
}
@Composable
internal fun InterestsScreen(
uiState: InterestsUiState,
followTopic: (String, Boolean) -> Unit,
onTopicClick: (String) -> Unit,
modifier: Modifier = Modifier,
highlightSelectedTopic: Boolean = false,
) {
...
}
从上面的代码我们可以看出来,状态的获取是通过 val uiState by viewModel.uiState.collectAsStateWithLifecycle() 这样的方式获取,然后与生命周期绑定。然后只向 compose 传递需要的参数和 Event,而不是整个 viewmodel。这一点非常重要,如果你的组件依赖了 viewmodel 那么你的组件的可复用性会变得很低。
严禁向 compose 方法传递 viewmodel
在这里我们稍微看一段上面的 viewmodel 的代码:
class InterestsViewModel @Inject constructor(
private val savedStateHandle: SavedStateHandle,
val userDataRepository: UserDataRepository,
getFollowableTopics: GetFollowableTopicsUseCase,
) : ViewModel()
可以看到他依赖了 Data layer 和 Domain layer 里面的部分 class,如果我一个 compose 的组件依赖了 viewmodel 那么,他是不是也需要依赖这些文件,这无疑让其使用这个组件的人增加了成本,而且这破坏了单一职责。再看看上面的 InterestsScreen ,这种方式是不是比之直接传递 viewmodel 要好上许多,复用性也更强了。
界面逻辑及其状态容器
界面逻辑我们平时开发中接触也不少,例如导航,获取图片资源。这些操作依赖于界面的存在,如果界面不存在了导航,获取图片资源这些便也没了意义。那么保存界面逻辑状态的容器便不需要很复杂,可以使用普通类来保存状态。
@Composable
fun rememberNiaAppState(
networkMonitor: NetworkMonitor,
userNewsResourceRepository: UserNewsResourceRepository,
timeZoneMonitor: TimeZoneMonitor,
coroutineScope: CoroutineScope = rememberCoroutineScope(),
navController: NavHostController = rememberNavController(),
): NiaAppState
这是一段项目里面的的界面状态容器代码,可以看到在 compose 里面界面容器本身也是 compose 的一部分,是可组合方法,那么其必然是可以被其他可组合方法复用的。
如何选择状态容器的类型?
一般来说业务逻辑我们会选择 viewmodel,跟 app 页面依赖较多的例如资源文件、导航控制器等我们可以选择使用普通类。
状态(state)、状态容器(state holder)、事件(event)如何串起来?
先来看一段状态生产的示意图:
首先事件他的来源可能是来自 viewmodel 依赖的 domain、data layer 的数据变化,也有可能是用户的交互操作,这些统一作为输入,然后 state holder,处理更新状态。
输入输出特点
举个例子:
val feedUiState: StateFlow<NewsFeedUiState> =
userNewsResourceRepository.observeAllBookmarked()
.map<List<UserNewsResource>, NewsFeedUiState>(NewsFeedUiState::Success)
.onStart { emit(Loading) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = Loading,
)
首先 viewmodel 也就是状态容器接受其他层的数据变化,整个过程是在异步的不在主线程执行,然后返回一个可观察的 stateflow。当然在实际开发过程中接受的输入不仅仅是 flow,其他类型的操作,或者两者混合使用都是可以的,灵活运用。
状态生产过程的初始化?
本着最小化调用的原则,生产过程应该在需要的时候才启动。所以我们应该尽可能延迟状态生成流水线的初始化,以节省系统资源。
在这里面有一个细节就是避免在 viewmodel 的构造或者 init 方法里面调用异步方法。这个应该是很多人都忽略的一点,首先如果调用异步方法,那么这个方法的生命周期可能会长于 viewmodel 自身,导致对象的泄露。其次根据函数式编程的理念就是不产生副作用,在构造或者 init 里面调用异步代码显然是不符合这个规范的。如果使用异步编程,不能保证构造函数的幂等性。而且有可能对象还没创建完就调用部分方法,产生不可预期的问题。
在学习 Now In Android 项目的时候我看到,每个 viewmodel 都是这么设计的,希望我们以后都能避免犯类似的错误。
下面举例说:
// 反面示例:不推荐的异步初始化
class BadViewModel(
private val userRepository: UserRepository
) : ViewModel() {
// 错误:在构造函数中直接启动异步操作
init {
viewModelScope.launch {
// 可能导致状态不一致和生命周期问题
val userData = userRepository.fetchUserData()
_userState.value = userData
}
}
}
// 正面示例:推荐的异步操作方式
class GoodViewModel(
private val userRepository: UserRepository
) : ViewModel() {
private val _userState = MutableStateFlow<UserData?>(null)
val userState: StateFlow<UserData?> = _userState.asStateFlow()
// 提供显式的加载方法
fun loadUserData() {
viewModelScope.launch {
try {
val userData = userRepository.fetchUserData()
_userState.value = userData
} catch (e: Exception) {
// 处理错误
_userState.value = null
}
}
}
}
The end,本章完
在这里给您拜个晚年,祝您晚年生活愉快 😄
juejin frontend
Angular 项目中 Could not find Nx modules in this workspace 错误的分析与解决
在 Angular 项目中运行命令 npx nx run-many --target=build 时,遇到错误消息 Could not find Nx modules in this workspace. Have you run npm/yarn install?,可能会让开发者感到困惑。这篇文章将从错误信息的含义、产生的原因以及如何解决问题等方面展开详细分析,并给出具体的示例代码。
错误信息含义解析
错误消息 Could not find Nx modules in this workspace 的字面意思是:在当前工作区中未找到 Nx 模块。随后的一句 Have you run npm/yarn install? 则提示开发者是否已经执行了 npm install 或 yarn install 命令来安装项目依赖。
从技术角度看,这个错误通常表明当前项目缺少 Nx 所需的依赖模块。Nx 是一个增强型的构建工具,用于支持 Angular、React 等框架的大型单体和多包仓库项目管理。为了让命令 npx nx run-many 能够正常工作,必须确保以下条件:
- 项目工作区中包含 Nx 的依赖项。
- 已安装所需的依赖模块。
- 工作目录的结构和配置文件(如
nx.json和angular.json)正确无误。
常见问题分析
问题 1:未安装项目依赖
如果项目的依赖未安装,npx nx 无法找到必要的模块和配置文件,导致错误。可能的原因包括:
- 刚克隆项目到本地后未运行
npm install或yarn install。 - 安装过程中出错,例如网络问题导致依赖未完全安装。
问题 2:项目缺少 Nx 相关配置
一个合法的 Nx 工作区需要包含 nx.json 文件和一些其他配置文件(如 angular.json 或 project.json)。如果这些文件缺失或结构被破坏,npx nx 无法识别当前目录为 Nx 工作区。
问题 3:依赖版本不匹配
如果 package.json 文件中声明的 Nx 版本与实际安装的版本不一致,也可能导致模块加载失败。
问题解决步骤
检查并安装依赖
运行以下命令,确保项目依赖已经安装:
npm install
或者:
yarn install
这一步会根据 package.json 文件中声明的依赖下载并安装模块。
检查项目是否为 Nx 工作区
确认项目根目录下是否存在 nx.json 文件。如果文件缺失,则表明项目并不是一个 Nx 工作区或工作区配置损坏。可以通过以下方式验证:
-
在项目根目录运行命令:
ls检查是否有
nx.json文件。 -
打开
angular.json文件,确认其内容是否包含projects字段,并且字段下的项目配置与 Nx 工作区一致。
如果 nx.json 文件缺失,可以使用以下命令重新初始化 Nx 工作区:
npx create-nx-workspace@latest
按照提示重新配置工作区。
检查 Nx 依赖项版本
确保 package.json 中的 Nx 依赖项声明正确。常见的 Nx 相关依赖项包括:
@nrwl/workspace@nrwl/angular
以下是一个标准的 package.json 示例:
{
"dependencies": {
"@nrwl/angular": "^16.0.0",
"@nrwl/workspace": "^16.0.0",
"rxjs": "^7.8.0"
},
"devDependencies": {
"@angular/cli": "^16.0.0",
"@nrwl/cli": "^16.0.0"
}
}
运行以下命令,安装或更新依赖项:
npm install @nrwl/angular @nrwl/workspace
示例项目
以下是一个简单的 Nx 工作区项目结构:
my-nx-workspace/
├── apps/
│ ├── my-app/
├── libs/
├── nx.json
├── angular.json
├── package.json
├── tsconfig.base.json
└── node_modules/
在该项目中运行 npx nx run-many --target=build,需要满足以下条件:
nx.json文件中配置了工作区和项目的基础信息。angular.json中定义了项目的构建配置。
实例代码运行
在 my-nx-workspace 目录下,执行以下命令,验证项目是否正确构建:
npx nx run-many --target=build
如果运行成功,将输出类似以下内容:
> nx run-many --target=build
Building project: my-app
...
Done in 5.32s.
如果仍然遇到问题,可以尝试清除缓存并重新安装依赖:
rm -rf node_modules package-lock.json
npm install
结论
Could not find Nx modules in this workspace 错误通常由依赖未安装、项目配置文件缺失或版本不匹配等问题引起。通过检查和修复项目的依赖安装状态、Nx 工作区配置文件和版本兼容性,能够有效解决问题并确保命令正常运行。
juejin backend
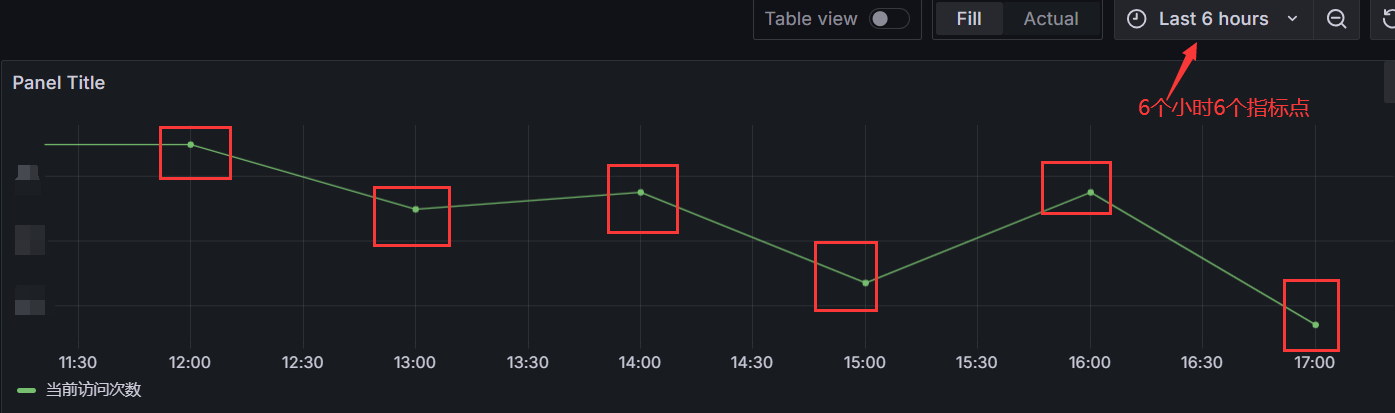
Go Gin 项目实战-API路由的分模块管理
随着项目开发的迭代,我们写的接口往往会越来越多,如果都把API的路由写到一个文件里,那么整个路由文件就会变得又乱又长,所以我们最好在项目开始阶段就给路由的分模块管理做好规划。
今天这个文章给大家介绍一下Web项目API路由的分模块管理,我们的项目使用的是Gin框架,但基本上所有的Web框架都能按照这个方式来分模块管理API接口的路由。
一些路由管理混乱的例子
首先,我先给大家看一个曾经维护过的项目的路由文件 router.go, 这个项目用的也是Gin框架,整个文件里500多行全是API接口的路由。
你说这么写不好维护吧,全项目的路由都在这里不用其他地方找,按能用就行的标准,确实是能用。
而且Gin的官方文档里在路由这块的例子确实也是这么写的。
// Gin 官方文档示例
func main() {
router := gin.Default()
// 简单的路由组: v1
v1 := router.Group("/v1")
{
v1.POST("/login", loginEndpoint)
v1.POST("/submit", submitEndpoint)
v1.POST("/read", readEndpoint)
}
// 简单的路由组: v2
v2 := router.Group("/v2")
{
v2.POST("/login", loginEndpoint)
v2.POST("/submit", submitEndpoint)
v2.POST("/read", readEndpoint)
}
router.Run(":8080")
}
随着项目开发的迭代,我们写的接口往往会越来越多,如果还按上面这样把API的路由写到一个文件里,那么整个路由文件就会变得像上面那个例子一样,变得又乱又长。
今天介绍两个步骤让我们能把项目路由分模块管理起来。本节内容节选自我的专栏《Go项目搭建和整洁开发实战》
本专栏力主实战技能,配备完整的实战项目,访问xiaobot.net/p/golang 即可订阅
项目中怎么规划和管理路由
首先根据我们上一节 「Go 项目怎么做好分层架构和目录规划」中设计的项目目录结构,在API处理器对应的api目录下的controler和router子目录中分别存放每个模块对应的Api handler 和 router 文件。
举例来说,假设我们项目中想在有用户和订单两个模块,那么此时项目的api/controller 和 api/router 中应该分别有俩个文件与业务模块对应。
.
|---api # API 处理器模块
| |---controller # 控制器
| | |---order.go # 订单模块的 Api Handler
| | |---user.go # 用户模块的 Api Handler
| |---router # 路由
| | |---order.go # 订单模块的路由文件
| | |---router.go # 负责路由初始化和注册各模块路由的总文件
| | |---user.go # 用户模块的路由文件
在路由目录中 router.go 负责路由初始化和注册各模块路由的总文件,此外一些要全局应用的中间件也会在这里设置,比如像下面这样。
而进入到每个模块的路由文件中,首先其路由组设置的路由前缀要跟模块名保持统一,另外还可以根据该模块中接口的统一特征在路由组上应用中间件。
比如是订单模块的接口,那么路由组的前缀可以设置成"/order/"这样所有订单相关的接口都在这个路径下,因为用户只能看自己的订单,所以所有订单相关的接口都需要用户认证后才能访问。我们可以在路由组上应用用户认证中间件,为组内的所有接口增加这项限制,比如像下面这样。
最后多提一点,如果业务模块里的接口太多,像controller/order.go 这样,单个文件不好组织整个模块的API handler的时候也可以把其升级为目录,变成下面这种结构。
.
|---api # API 处理器模块
| |---controller # 控制器
| | |---order # 订单模块的 Api Handler
| | | |---xxx.go
| | | |---yyy.go
| |---router # 路由
......
好了,介绍完Web项目管理路由的大概思路后,我带大家一起看下,怎么用这个思路在Gin项目中分模块管理
用Gin实现路由的分模块管理
分模块首先就是按照URI的目录或者叫路由组进行管理,首先我们在项目的 api/router 目录下定义一个router.go文件,它负责路由初始化和注册各模块的路由。
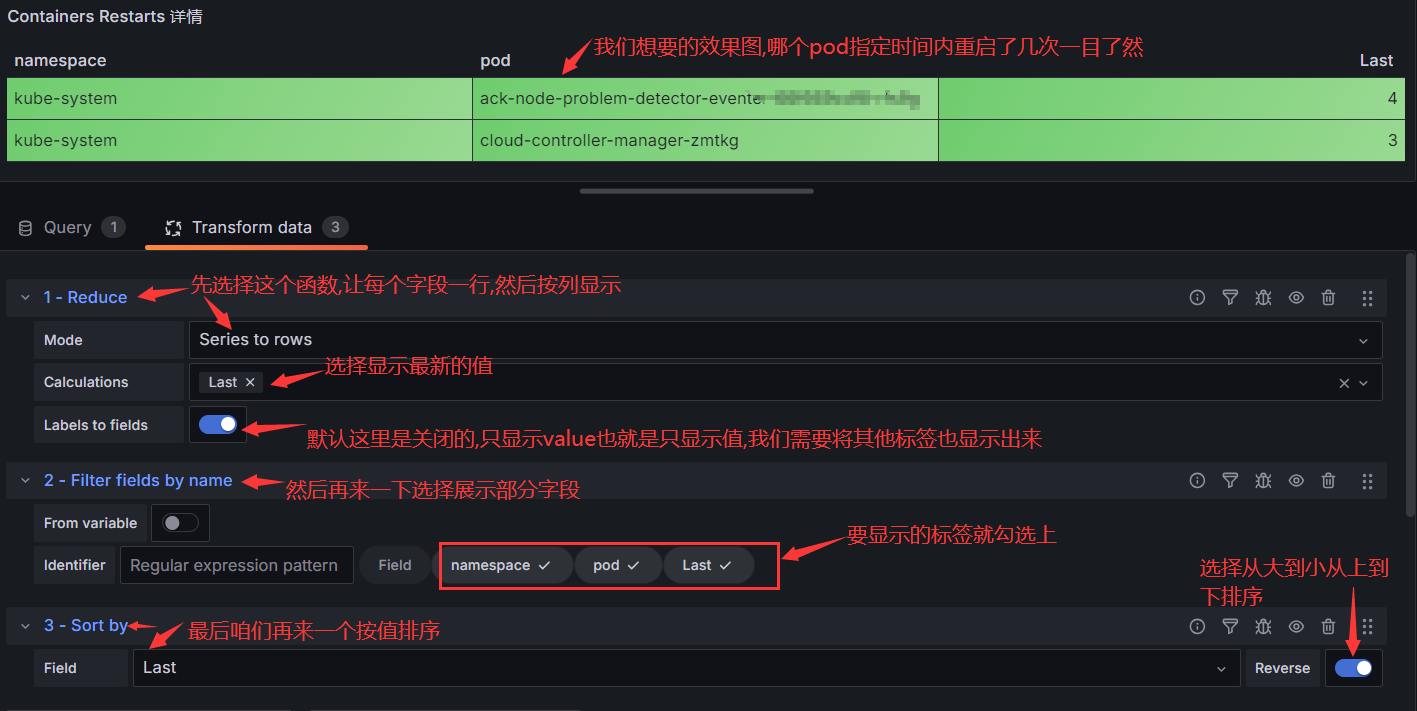
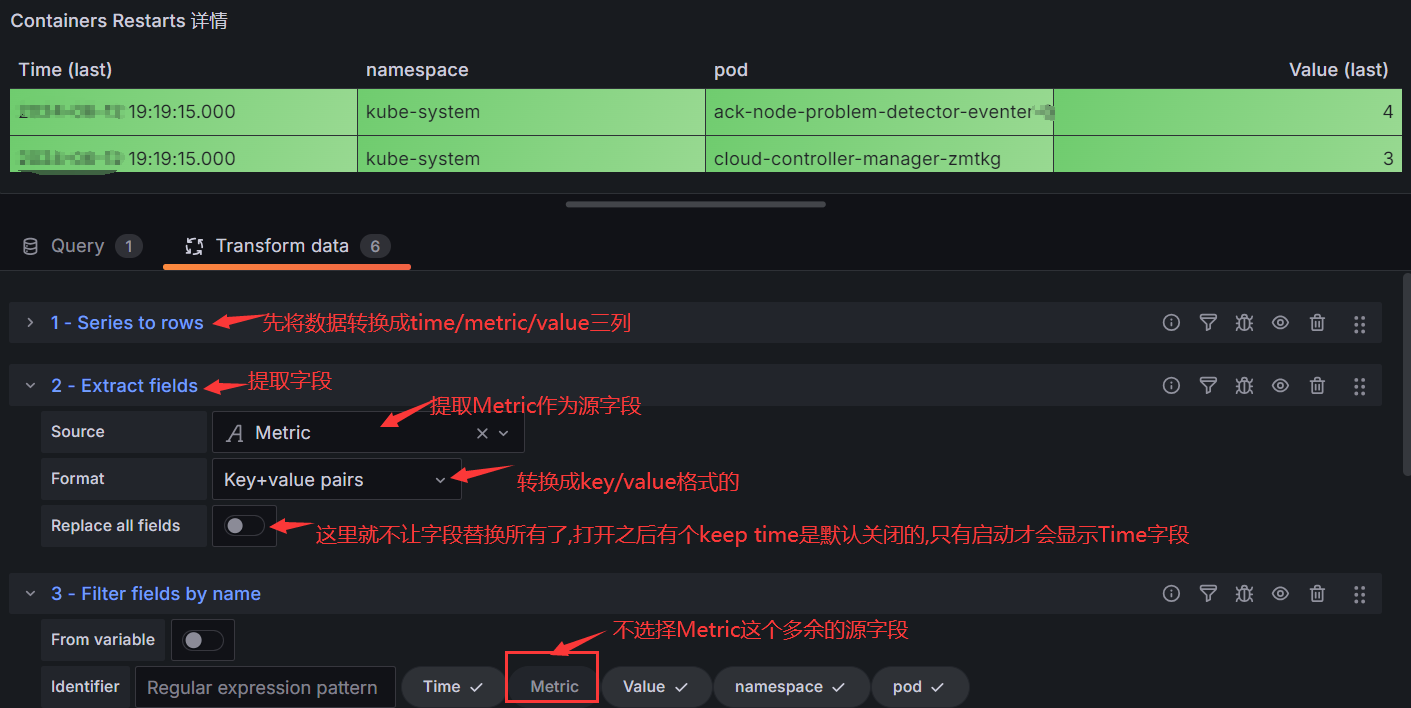
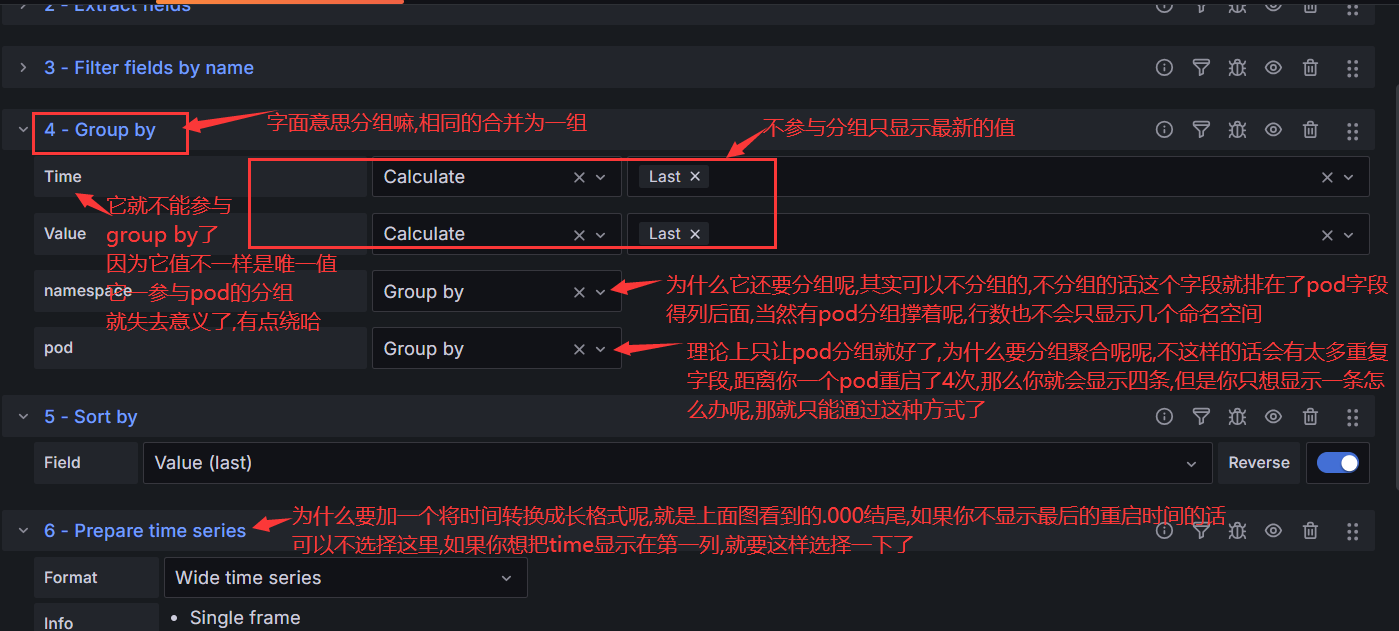
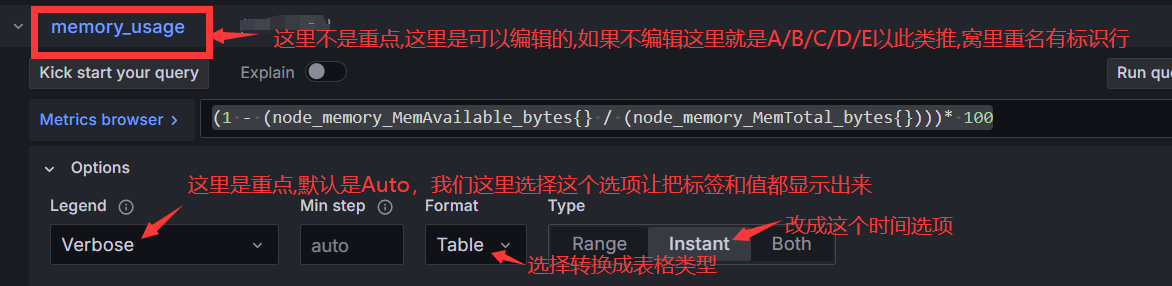
在其中增加如下代码:
func RegisterRoutes(engine *gin.Engine) {
// use global middlewares
engine.Use(middleware.StartTrace(), middleware.LogAccess(), middleware.GinPanicRecovery())
routeGroup := engine.Group("")
registerBuildingRoutes(routeGroup)
}
在这里我们先把所有全局中间件应用上,Gin框架的路由组是靠 gin.Group 来维护的,我们先在全局的router方法中通过 engine.Group("") 拿到一个不带任何路由前缀的 gin.Group 作为顶级路由组。
之后再把它传递给每个子模块的路由注册方法,在这个顶级路由组的基础上再去生成各个路由模块的路由组对象,用来注册它们各自的路由。
我们先把之前搭建框架时写的那些测试方法的路由都放在api/router/building.go 文件中,所有路由都以"/building/"作为前缀。
// 存放一些项目搭建过程中验证效果用的接口的路由
func registerBuildingRoutes(rg *gin.RouterGroup) {
// 这个路由组中的路由都以 /building 开头
g := rg.Group("/building/")
// 测试 Ping
g.GET("ping", controller.TestPing)
// 测试日志文件的读取
g.GET("config-read", controller.TestConfigRead)
// 测试日志门面Logger的使用
g.GET("logger-test", controller.TestLogger)
// 测试服务的访问日志
g.POST("access-log-test", controller.TestAccessLog)
// 测试服务的崩溃日志
g.GET("panic-log-test", controller.TestPanicLog)
// 测试项目自定义的AppError 打印错误链条和错误发生位置
g.GET("customized-error-test", controller.TestAppError)
// 测试统一响应--返回对象数据
g.GET("response-obj", controller.TestResponseObj)
// 测试统一响应--返回列表和分页
g.GET("response-list", controller.TestResponseList)
// 测试统一响应--返回错误
g.GET("response-error", controller.TestResponseError)
}
相应的路由对应的API Handler也需要从main.go 中挪到 controller 包中, 我们在api/controller中新建building.go 用来存放搭建框架过程中编写的那些测试接口的Handler方法。
把已有的Controller挪到对应的文件后,可以随机抽查几个看看看到这些接口是否都还能正常访问,接下来再观察下我们请求接口时产生的应用日志。
应用日志仍然是能正常的把请求的访问日志和错误响应日志都给记录下来,证明代码改动没问题。
路由分模块管理的规则
上面我演示了为了做路由分模块管理在项目中做的那些基础工作,未来进入需求开发阶段我们只要按照这个规则分模块去管理路由就行啦。
后面我们在项目开发时,API的路由管理也遵循这个原则:
- 每个业务模块的API,都编写单独的路由注册函数,把路由放在api/router/目录的一个单独的文件中,文件名与模块名相对应。
- 每个业务模块的API Handler,都放在api/controller 目录下的一个单独文件或者单独的目录中。
如果按照我们上节课「Go 项目怎么做好分层架构和目录规划」中介绍的使用应用服务和领域服务拆分逻辑的方式。控制器层应该每个Controller 方法的代码都很少,Controller中的代码不会太臃肿,除非某个模块下接口数量特别多才需要多个controller文件来存放模块下的Controller代码。
总结
本专栏力主实战技能,配备完整的实战项目,访问xiaobot.net/p/golang 即可订阅
订阅后,可加入专栏配套的实战项目,获得完整实战教程,同时也有专属的读者群,欢迎加入一起学习。
本节对应的代码版本为c6,订阅后加入课程的GitHub项目后访问 github.com/go-study-la… 可以直接查看本章节对应的代码更新。
下一节,在开始用代码进一步讲解如何使用分层架构做项目开发之前我们先为项目集成GORM,同时我们还会把GORM的日志统一整合到项目的应用日志中,这样即使访问DB时除了问题或者有慢查询后,也能通过我们的项目日志来统一追踪查询。
web安全 - CSRF
跨站请求伪造CSRF(Cross Site Request Forgery):是一种利用用户身份认证漏洞,骗取服务器信任,让受害者在不知情的情况下,执行攻击者指定的恶意请求。
攻击原理
- 用户登录A网站,浏览器保存了用于身份认证的Cookie。
- 攻击者诱导用户访问B网站。
- B网站“静悄悄”地向A网站发送请求,浏览器自动携带用户的Cookie进行身份认证。
- 用户账号被攻击者“控制”,例如转账、删除资源等。
示例
用户在 meow.com 登录账号(此时Cookie仍然有效)
攻击者在自己的钓鱼网站上嵌入了一张恶意图片:
<img src="https://meow.com/transfer?to=attacker&amount=5000">
或构造一个form表单,然后利用Javascript自动提交
<p>只是和你开个小玩笑👿,新年快乐🎉</p>
<form id="myForm" action="https://meow.com/transfer">
<input type="hidden" name="to" value="attacker">
<input type="hidden" name="amount" value="5000">
</form>
<script>
document.getElementById('myForm').submit()
</script>
用户访问后链接后,浏览器会自动带上会话数据(Cookie),导致用户的账户向攻击者转账!
防御
- 二次认证:在进行某些关键操作时(如转账、删除用户),要求用户进行二次登录或者输入验证。
- 设置
sameSite=Strict,限制Cookie只能在同源站点提交,防止跨站滥用。
Koa设置Cookie的SameSite属性:
ctx.cookies.set('sessionId', sessionId, {
path: '/',
httpOnly: true,
secure: false,
sameSite: 'strict',
})
- Token认证:服务器生成随机的Token,并在表单或请求中携带,服务器在收到请求时验证Token。
前端提交服务器返回的CSRF Token:
<form method="POST" action="https://meow.com/login">
<input type="hidden" name="_csrf" value="token">
<input type="submit" value="登录">
</form>
六. Redis当中的“发布” 和 “订阅” 的详细讲解说明(图文并茂)
六. Redis当中的“发布” 和 “订阅” 的详细讲解说明(图文并茂)
@[toc]
1. 发布 和 订阅的概念
发布和订阅是什么?
一句话: Redis 发布(pub) 订阅(sub) 是一种消息通信模式:发送者(pub) 发送信息,订阅者(sub) 接收信息 。
- 订阅:subscribe
- 发布:publish
Redis 客户端可以订阅任意数量的频道。
客户端订阅频道示意图:
当给这个频道发布消息后,消息就会发送给订阅了的客户端:
发布了一个消息 Hello ,给了对应的频道,然后这些订阅了该频道的客户端,就会读取到发布的(Hello)的消息。
客户端可以订阅多个频道。
可以发布多个消息给多个频道 。
如何理解发布和订阅模式:
任务队列:
-
顾名思义,就是“传递消息的队列”
-
与任务队列进行交互的实体有两类:
- 一类是:生产者(producer) ,
- 另一类则是消费者(consumer)
生产者 将需要处理的任务放入到任务队列 当中,而消费者 则不断地从任务队列中读取任务信息并执行。
如何简单理解:
- Subscriber:看作是收音机 。可以收到多个频道,并以队列方式显示。
- Publisher:看做是电台 。可以往不同的 FM 频道中发送消息。
- Channel:不同频率的 FM 频道
从 Pub/Sub 的机制来看,它更像是一个广播系统,多个订阅者(Subscriber) 可以订阅多个频道(Channel) ,多个发布者(Publisher) 可以往多个频道(Channel) 中发布消息。
简单通俗一点就是说:发布消息到一个
中间件上,而订阅/配置了这个中间件的客户端,就会实时/接收到这个发送到中间件上的消息。
2. 发布订阅模式分类
2.1 一个发布者,多个订阅者
一个发布者,多个订阅者
主要应用:通知、公告。
可以作为消息队列或者消息管道。
2.2 多个发布者,一个订阅者
多个发布者,一个订阅者
各应用程序作为 Publisher 向 Channel 中发送消息,Subscriber 端收到消息后执行相应的业务逻辑,比如写数据库,显示。
主要应用:排行榜,投票,计数 。
2.3 多个发布者,多个订阅者
多个发布者,多个订阅者。
可以向不同的 Channel 中发送消息,由不同的 Subscriber 接收
主要应用:群聊,聊天
3. Redis 命令行实现发布和订阅
关于Redis 实现发布和订阅有如下 6 个相关的命令:
PUBLISH channel msg将消息 message 发送到指定的频道 channel
SUBSCRIBE channel [channel ...]订阅频道,可以同时订阅多个频道
UNSUBSCRIBE [channel ...]取消订阅指定的频道,如果不指定频道,则会取消所订阅的所以频道
PSUBSCRIBE pattern [pattern ...]订阅一个或多个符合给定模式的频道,每个模式以*作为匹配符,比如it*匹配所有以 it 开头的频道(it.news,it.blog,it.tweets 等等);news.*匹配所有以news.开头的频道(new.it,new.global.today 等等),诸如此类。
PUNSUBSCRIBE [pattern [pattern ...]]退订指定的规则,如果没有参数则会退订掉所i有规则 。
PUBSUB <subcommand> [argument [argument …]]是一个查看订阅与发布系统状态的内省命令,
代码示例:
# client-1 订阅 news.it 和 news.sport 两个频道
client-1> SUBSCRIBE news.it news.sport
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "news.it"
3) (integer) 1
1) "subscribe"
2) "news.sport"
3) (integer) 2
# client-2 订阅 news.it 和 news.internet 两个频道
client-2> SUBSCRIBE news.it news.internet
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "news.it"
3) (integer) 1
1) "subscribe"
2) "news.internet"
3) (integer) 2
# 首先, client-3 打印所有活跃频道
# 注意,即使一个频道有多个订阅者,它也只输出一次,比如 news.it
client-3> PUBSUB CHANNELS
1) "news.sport"
2) "news.internet"
3) "news.it"
# 接下来, client-3 打印那些与模式 news.i* 相匹配的活跃频道
# 因为 news.sport 不匹配 news.i* ,所以它没有被打印
redis> PUBSUB CHANNELS news.i*
1) "news.internet"
2) "news.it"
4. Redis 命令行实现发布和订阅
4.1 一个发布者,多个订阅者演示
让 client01 ,client02 两个客户端都订阅上 channel1 频道。
127.0.0.1:6379> subscribe channel1 # 让客户端订阅 channel1频道
当订阅上了一个频道,就会实时监听该频道的存在的内容。所以我们想要退出的话,可以
Ctrl + C或者quit
让 client02 也订阅上channel 频道,进行接收消息。
127.0.0.1:6379> subscribe channel1
两个 Client 客户端都订阅上了 channel1 频道了。
接下来,让 publish 客户端向 channel1 频道发送信息。看看 ,client01 ,client02 两个订阅了 channel1的客户端是否会监听到 发送的信息。
127.0.0.1:6379> publish channel1 "hello,jack"
4.2 多个发布者,一个订阅者演示
这里我们演示:让 client01 客户端通过订阅 channel1 频道,实时监听/接收: publish01和 publish02 向 channel 发送的信息。
127.0.0.1:6379> subscribe channel1
127.0.0.1:6379> publish channel1 "hello tom"
127.0.0.1:6379> publish channel1 "hello lihua"
4.3 多个发布者,多个订阅者演示
让 publish01,publish01两个客户端都向 channel1 频道发送消息,client01 和 client02 都订阅 channel1 频道,接收/监听该 (channel1) 频道的信息。
127.0.0.1:6379> subscribe channel1
127.0.0.1:6379> subscribe channel1
# 返回的是订阅者的数量
127.0.0.1:6379> publish channel1 "hello AAA"
127.0.0.1:6379> publish channel1 "BBB"
5. 注意事项:
publish同一时刻只能向一个 channel 频道发送信息,不可以多个。
subscribe命令可以同一时刻订阅多个 channel 频道。 返回的是订阅者的数量。
- 发布的消息没有持久化,所以订阅的客户端, 只能收到订阅后发布的消息。无法接收该客户端还没订阅上时已经发布的消息(错过的消息 )。
6. 最后:
“在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。”
五. Redis 配置内容(详细配置说明)
五. Redis 配置内容(详细配置说明)
@[toc]
关于 Redis 配置文件的文档说明:www.cnblogs.com/nhdlb/p/140…
Redis 的配置的内容,都是在
/etc/redis.conf这个文件当中进行配置设置的。
redis.conf 配置内容有很多很多,这里我们讲解一些比较常用的一些配置信息。
1. Units 单位配置
:set number # 在 vim 工具当中 ,表示显示行号
- 配置大小单位,开头定义了一些基本的度量单位,只支持 bytes(字节) ,不支持 bit(比特),这是默认的,大家可以更加需要自行修改。
- 默认是不区分大小写的,对于命令来说,这个也是大家可以自行修改配置的。
2. INCLUDES (包含)配置
该配置信息表示:多实例的情况可以把公用的配置文件提取出来,然后 include 导入 。
3. NETWORK (网络)配置
3.1 bind(配置访问内容)
bind 127.0.0.1 -::1
- 默认情况
bind 127.0.0.1表示只能接收本地(本机)的访问请求,其它的主机是无法访问的。 - 如果服务器是需要远程访问的,需要将其注释掉。
- 这里,我们可以启动 redis ,查看当前允许连接的情况。
注销 bind , 重新启动 redis, 再查看当前允许连接的情况。
注意: 需要将 Redis 服务器,关闭了,再重启后,配置才能生效。
[root@localhost ~]# redis-cli -p 6379 shutdown
3.2 protected-mode (保护模式)
默认是保护模式,也就是 protected-mode no 。
如果服务器是需要远程访问的, 需要将 yes 设置为 no
3.3 port(端口)配置
Redis 服务默认端口 6379,可以自行修改,但是注意要在
655535的范围。
3.4 timeout(客户端超时时间)配置
如图默认配置:
timeout 0
一个空闲的客户端维持多少秒会关闭,0 表示关闭该功能, 即永不超时 。大家可以根据需要自行修改。
3.5 tcp-keepalive()配置
tcp-keepalive 300
tcp-keepalive是对访问客户端的一种心跳检测,每隔 n 秒检测一次,单位为秒。- 如果设置为 0 ,则不会进行 keepalive 检测,建议设置成 60
为什么需要心跳检测机制:
- TCP 协议中有长连接 和 短连接 之分。短连接 环境下,数据交互完毕后,主动释放连接。
- 长连接 的环境下,进行一次数据交互后,很长一段时间内无数据交互时,客户端可能意外断开,这些 TCP 连接并未来得及正常释放 ,那么,连接的另一方并不知道对端的情况。就会一直维护这个连接,长时间的积累会导致非常多的半打开连接,造成端系统资源的消耗和浪费,且有可能导致在一个无效的数据链路层面发送业务数据,结果就是发送失败。所以服务端要做到快速感知失败,减少无效链接操作,这就有了 TCP 的 Keepalive(保活探测) 机制
tcp-keepalive 10
配置成功后,需要重启 Redis 服务才会生效。
[root@localhost etc]# redis-cli -p 6379 shutdown
4. GENERAL 通用配置
4.1 daemonize(后台启动)配置
daemonize yes
- 是否为后台进程,设置为 yes
- 设置为 yes 后, 表示守护进程, 后台启动
4.2 pidfile(pid 文件存在路径)配置
pidfile /var/run/redis_6379.pid
存放 pid 文件的位置,每个实例会产生一个不同的 pid 文件, 记录 redis 的进程号
[root@localhost run]# ps -ef | grep redis
[root@localhost run]# cat redis_6379.pid
[root@localhost run]# ps -aux | grep sshd
4.3 loglevel(日志级别)配置
loglevel notice
Redis 日志分为 4 个级别,默认的设置为 notice,开发测试阶段可以用 debug(日志内容较多,不建议生产环境使用),生产模式一般选用 notice
Redis 日志级别为如下 4 种 :
debug:会打印很多信息,适用于开发和测试阶段。verbose(冗长的):包含很多不太有用的信息,但比 debug 要清爽一些。notice:适用于生产模式。warning:警告信息。
127.0.0.1:6379> config get loglevel
4.4 logfile(日志文件)配置
logfile ""
- logfile "" 就是说,默认为控制台打印,并没有日志文件生成
- 可以为 redis.conf 的 logfile 指定配置项。如下:
logfile "/var/log/redis/redis.log"
修改了配置文件,需要重启 redis 才会生成。
127.0.0.1:6379> config get logfile
4.5 databases 16(仓库数量)配置
databases 16
- 设定库的数量,默认是16个,默认数据库为 0 号,数据库索引是从 0 开始的
- 可以适用
select<dbid>命令在连接上指定数据库 id
5. SECURITY 安全配置
SECURITY 安全配置,就是为 Redis 客户端登录的时候,设置密码。
在 Redis 当中,设置密码有两种方式:
5.1 在 redis.conf 配置文件当中设置密码(永久)
# requirepass foobared
这里我们测试,将注释去掉,适用这个 foobared 作为密码。
requirepass foobared
修改了配置,需要重启 Redis 服务,才会生效。
127.0.0.1:6379> auth foobared
127.0.0.1:6379> auth 密码 # 登录 redis 客户端,使用密码
127.0.0.1:6379> acl list
# 注意:需要进入到 Redis 客户端
127.0.0.1:6379> acl whoami
# 注意:需要进入到 Redis 客户端
5.3 在 命令行设置密码
127.0.0.1:6379> config get requirepass
127.0.0.1:6379> config set requirepass rainbowsea
6. LIMITS 限制配置
6.1 maxclients(客户端连接数)配置
-
设置 Redis 同时可以与多少个客户端进行连接(包括远程连接)
-
默认情况下为 10000 个客户端。
-
如果达到了此限制,redis 会拒绝新的连接请求,并且向这些连接请求方发出
“max number of clients reached” -
注意一点的是:当超过连接数目了,你可以进入到 Redis 客户端,但是的命令是不会被 Redis 执行的,并提示
“max number of clients reached”。
6.2 maxmemory(Redis 最大占用内存)配置
# maxmemory <bytes>
- 在默认情况下, 对 32 位 实例会限制在 3 GB, 因为 32 位的机器最大只支持 4GB 的 内存,而系统本身就需要一定的内存资源来支持运行,所以 32 位机器限制最大 3 GB 的 可用内存是非常合理的,这样可以避免因为内存不足而导致 Redis 实例崩溃
- 在默认情况下, 对于 64 位实例是没有限制
- 当用户开启了 redis.conf 配置文件的 maxmemory 选项,那么 Redis 将限制选项的值 不能小于 1 MB
maxmemory 设置的建议:
- Redis 的 maxmemory 设置取决于使用情况, 有些网站只需要 32MB,有些可能需要 12GB
- maxmemory 只能根据具体的生产环境来调试,不要预设一个定值,从小到大测试, 基本标准是不干扰正常程序的运行。
- Redis 的最大使用内存跟搭配方式有关,如果只是用 Redis 做纯缓存, 64-128M 对一般小 型网站就足够了
- 如果使用 Redis 做数据库的话,设置到物理内存的 1/2 到 3/4 左右都可以
- 如果使用了快照功能的话,最好用到 50%以下,因为快照复制更新需要双倍内存空间, 如果没有使用快照而设置 redis 缓存数据库,可以用到内存的 80%左右,只要能保证 Java、 NGINX 等其它程序可以正常运行就行了
6.3 maxmemory-policy(Redis内存不够的算法配置处理)配置
# maxmemory-policy noevictio
policy 可以配置如下选项:
volatile-lru:使用 LRU 算法移除 key,只对设置了过期时间的键;(最近最少使用)allkeys-lru:在所有集合 key 中,使用 LRU 算法移除 keyvolatile-random:在过期集合中移除随机的 key,只对设置了过期时间的键allkeys-random:在所有集合 key 中,移除随机的 keyvolatile-ttl:移除那些 TTL 值最小的 key,即那些最近要过期的 keynoeviction:不进行移除。针对写操作,只是返回错误信息
无论是选择那种配置,都会丢失数据,所以,尽量还是设置好合适的 Redis 内存,方式内存不够用 。
6.4 maxmemory-samples(内存算法处理的比较样本) 配置
# maxmemory-samples 5
- 设置样本数量,LRU 算法和最小 TTL 算法都并非是精确的算法,而是估算值,所以你可 以设置样本的大小,redis 默认会检查这么多个 key 并选择其中 LRU 的那个。
- 一般设置 3 到 7 的数字,数值越小样本越不准确,但性能消耗越小。
举例理解:
简单的比较就是:当你在 8W 个人当中,找到身高 180 的人,很费时间和精力。但是当让你从 10,100个人当中找 身高 180的人,那就更简单了。简单的理解就是一个参考的样本。参考的数量越多精确度越高,但是成本也就越高。参考的数量少的,精确的就越低,但是消耗的成本却更低。
7. 总结:
- 注意: 上述的所有配置都需要将 Redis 服务器,关闭了,再重启后,配置才能生效。
- 查看 redis.conf 配置文件的信息,可以进入到 Redis 客户端后,使用
config get 配置属性/信息命令。注意: 需要先进入到 Redis 客户端才行。
127.0.0.1:6379> config get loglevel
1) "loglevel"
2) "notice"
127.0.0.1:6379> config get logfile
1) "logfile"
2) ""
- 在命令行当中设置 redis.conf 配置文件的信息,可以进入到 Redis 客户端后,使用
config set 配置属性/信息命令。注意: 需要先进入到 Redis 客户端才行。同时因为是在 客户端命令设置的配置信息,那么退出了客户端,该命令行配置的信息就都失效了。
127.0.0.1:6379> config set requirepass rainbowsea
127.0.0.1:6379> auth rainbowsea
127.0.0.1:6379> config get requirepass
8. 最后:
“在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。”
juejin frontend
深入浅出:Node.js高级重试机制
在分布式系统中,优雅地处理异常是构建可靠应用程序的关键。无论是网络抖动、服务暂时不可用,还是数据库连接超时,这些短暂的故障都可能让系统陷入混乱。而重试模式,作为一种经典的设计模式,正是解决这些问题的利器。今天,我们将深入探讨如何在 Node.js 中实现高级重试机制,并分享一些实用的策略和最佳实践。
什么是重试模式?
重试模式是一种用于提高系统稳定性的设计模式。它的核心思想是:在面对短暂的故障时,不要轻易放弃,而是尝试重新执行操作。这种模式特别适用于云环境,因为云服务中的临时网络故障、服务不可用和超时是家常便饭。
举个例子:假设你正在使用一个云服务来存储和检索用户数据。由于网络波动或服务端的临时问题,你的请求可能会偶尔失败。如果没有重试机制,一旦请求失败,应用程序就会直接报错,用户体验会大打折扣。而有了重试模式,应用程序会在第一次失败后等待一段时间,然后再次尝试发送请求。如果第二次仍然失败,它可能会继续重试,直到达到预设的最大重试次数。这样,即使在云环境中遇到短暂的故障,你的应用程序也有可能成功完成操作,从而提高了系统的稳定性和可靠性。
从基础到高级:重试模式的实现
基础实现:简单的重试逻辑
我们先从一个简单的重试实现开始。以下代码展示了如何在 Node.js 中实现一个基础的重试机制:
async function basicRetry(fn, retries = 3, delay = 1000) {
try {
return await fn();
} catch (error) {
if (retries <= 0) throw error;
await new Promise(resolve => setTimeout(resolve, delay));
return basicRetry(fn, retries - 1, delay);
}
}
const fetchData = async () => {
return basicRetry(async () => {
const response = await fetch('https://api.example.com/data');
return response.json();
});
};
这段代码的核心逻辑是:如果操作失败,等待一段时间后重试,直到达到最大重试次数。虽然这种实现简单直接,但它已经能够应对大多数短暂的故障。
高级策略 1:指数退避
在分布式系统中,简单的固定延迟重试可能会导致“重试风暴”,即大量请求在同一时间重试,进一步加剧系统负载。为了避免这种情况,我们可以使用指数退避策略。指数退避的核心思想是:每次重试的延迟时间呈指数增长,从而分散重试请求的压力。
以下是一个指数退避的实现:
class ExponentialBackoffRetry {
constructor(options = {}) {
this.baseDelay = options.baseDelay || 1000;
this.maxDelay = options.maxDelay || 30000;
this.maxRetries = options.maxRetries || 5;
this.jitter = options.jitter || true;
}
async execute(fn) {
let retries = 0;
while (true) {
try {
return await fn();
} catch (error) {
if (retries >= this.maxRetries) {
throw new Error(`Failed after ${retries} retries: ${error.message}`);
}
const delay = this.calculateDelay(retries);
await this.wait(delay);
retries++;
}
}
}
calculateDelay(retryCount) {
let delay = Math.min(
this.maxDelay,
Math.pow(2, retryCount) * this.baseDelay
);
if (this.jitter) {
delay = delay * (0.5 + Math.random());
}
return delay;
}
wait(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
}
在这个实现中,每次重试的延迟时间会随着重试次数的增加而指数增长。同时,我们还引入了**抖动(Jitter)**机制,通过随机化延迟时间来避免多个请求在同一时间重试。
高级策略 2:与断路器模式集成
重试模式虽然强大,但如果目标服务完全不可用,无限制的重试只会浪费资源。为了避免这种情况,我们可以将重试模式与断路器模式结合使用。断路器模式的核心思想是:当失败次数达到一定阈值时,暂时停止重试,直接返回错误。
以下是一个断路器模式的实现:
class CircuitBreaker {
constructor(options = {}) {
this.failureThreshold = options.failureThreshold || 5;
this.resetTimeout = options.resetTimeout || 60000;
this.failures = 0;
this.state = 'CLOSED';
this.lastFailureTime = null;
}
async execute(fn) {
if (this.state === 'OPEN') {
if (Date.now() - this.lastFailureTime >= this.resetTimeout) {
this.state = 'HALF_OPEN';
} else {
throw new Error('Circuit breaker is OPEN');
}
}
try {
const result = await fn();
if (this.state === 'HALF_OPEN') {
this.state = 'CLOSED';
this.failures = 0;
}
return result;
} catch (error) {
this.failures++;
this.lastFailureTime = Date.now();
if (this.failures >= this.failureThreshold) {
this.state = 'OPEN';
}
throw error;
}
}
}
在这个实现中,当失败次数达到阈值时,断路器会进入“打开”状态,停止所有重试操作。经过一段时间后,断路器会进入“半开”状态,尝试恢复操作。如果操作成功,断路器会恢复到“关闭”状态;如果失败,则继续保持“打开”状态。
高级策略 3:综合重试系统
为了充分发挥重试模式和断路器模式的优势,我们可以将它们结合起来,构建一个综合的重试系统。以下是一个高级重试系统的实现:
class AdvancedRetrySystem {
constructor(options = {}) {
this.retrier = new ExponentialBackoffRetry(options.retry);
this.circuitBreaker = new CircuitBreaker(options.circuitBreaker);
this.logger = options.logger || console;
}
async execute(fn, context = {}) {
const startTime = Date.now();
let attempts = 0;
try {
return await this.circuitBreaker.execute(async () => {
return await this.retrier.execute(async () => {
attempts++;
try {
const result = await fn();
this.logSuccess(context, attempts, startTime);
return result;
} catch (error) {
this.logFailure(context, attempts, error);
throw error;
}
});
});
} catch (error) {
throw new RetryError(error, attempts, Date.now() - startTime);
}
}
logSuccess(context, attempts, startTime) {
this.logger.info({
event: 'retry_success',
context,
attempts,
duration: Date.now() - startTime
});
}
logFailure(context, attempts, error) {
this.logger.error({
event: 'retry_failure',
context,
attempts,
error: error.message
});
}
}
class RetryError extends Error {
constructor(originalError, attempts, duration) {
super(originalError.message);
this.name = 'RetryError';
this.originalError = originalError;
this.attempts = attempts;
this.duration = duration;
}
}
这个综合系统不仅支持指数退避和断路器模式,还提供了详细的日志记录功能,帮助我们更好地监控和优化重试策略。
最佳实践与注意事项
- 幂等性:确保你正在重试的操作是幂等的。这意味着多次重试相同的操作应与执行一次具有相同的效果。
- 监控与日志记录:实施全面的日志记录,以跟踪重试尝试、成功率和失败模式。这有助于识别系统性问题并优化重试策略。
- 超时管理:始终为单次尝试实现超时,以防止挂起的操作:
async function withTimeout(promise, timeoutMs) {
const timeoutPromise = new Promise((_, reject) => {
setTimeout(() => reject(new Error('Operation timed out')), timeoutMs);
});
return Promise.race([promise, timeoutPromise]);
}
- 资源清理:确保在重试后正确清理资源,尤其是在处理数据库连接或文件句柄时。
实际应用示例
以下是如何在实际场景中使用高级重试系统的示例:
const retrySystem = new AdvancedRetrySystem({
retry: {
baseDelay: 1000,
maxDelay: 30000,
maxRetries: 5
},
circuitBreaker: {
failureThreshold: 5,
resetTimeout: 60000
}
});
async function fetchUserData(userId) {
return retrySystem.execute(
async () => {
const user = await db.users.findById(userId);
if (!user) throw new Error('User not found');
return user;
},
{ operation: 'fetchUserData', userId }
);
}
async function updateUserProfile(userId, data) {
return retrySystem.execute(
async () => {
const response = await fetch(`/api/users/${userId}`, {
method: 'PUT',
body: JSON.stringify(data)
});
if (!response.ok) throw new Error('API request failed');
return response.json();
},
{ operation: 'updateUserProfile', userId }
);
}
总结
在 Node.js 中实现可靠的重试逻辑是构建弹性系统的关键。通过结合指数退避、断路器模式和详细的日志记录,我们可以创建复杂的重试机制,优雅地处理故障,同时防止系统过载。
记住,重试逻辑应根据应用程序的具体需求和操作的性质进行谨慎实施。始终根据实际性能和故障模式监控并调整重试策略。希望这篇文章能帮助你更好地理解和应用重试模式,构建更加健壮的分布式系统!




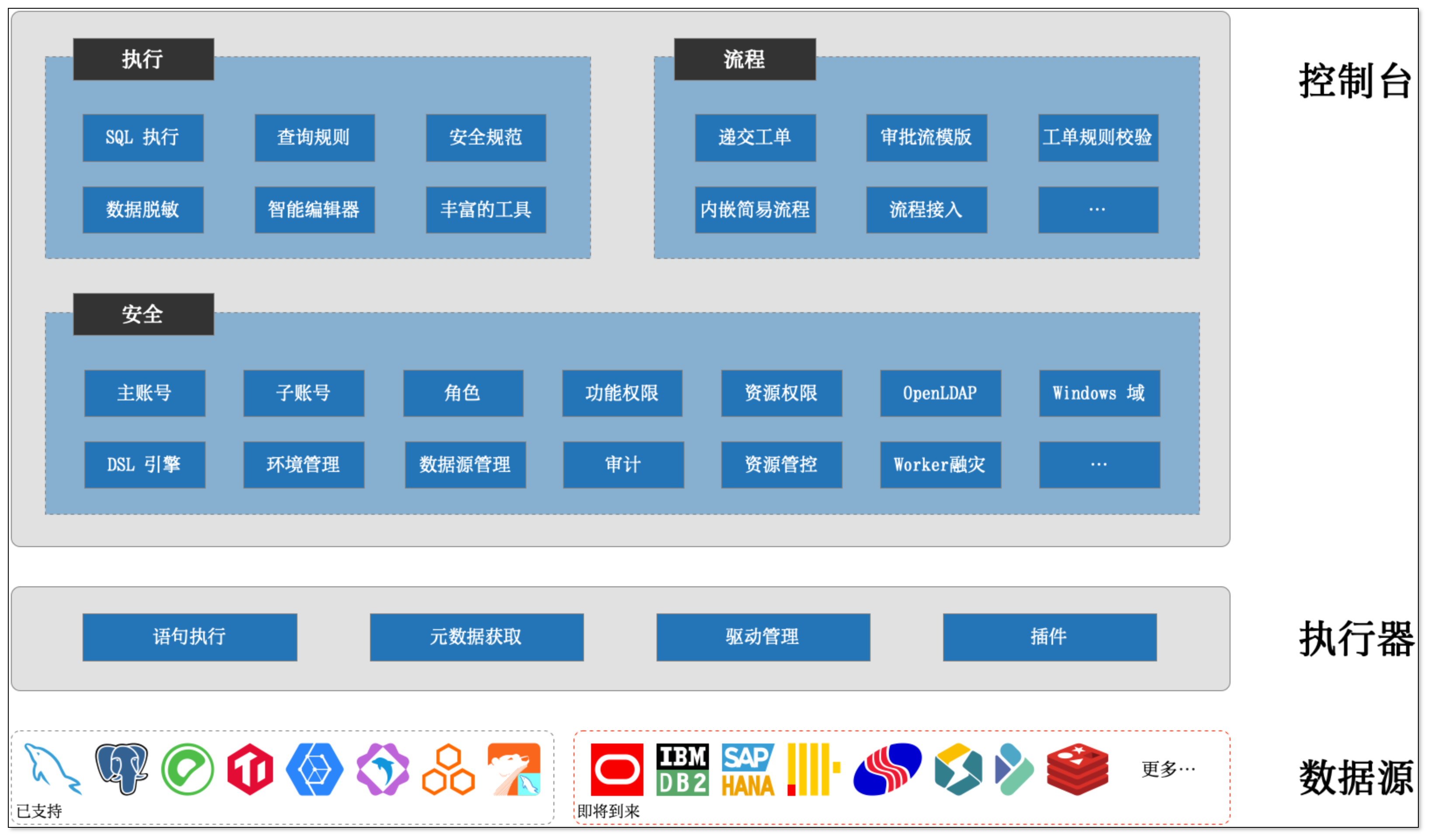
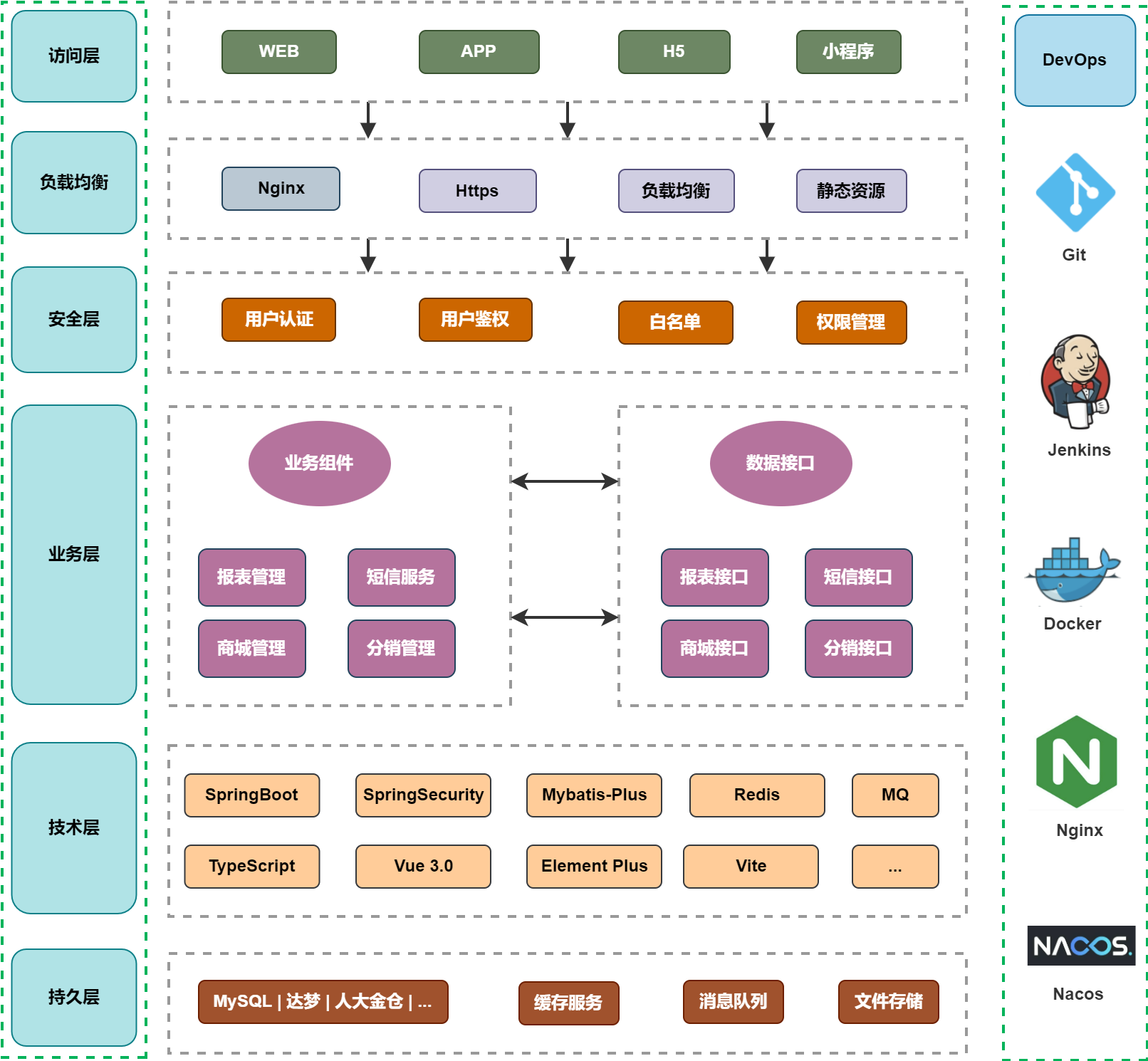
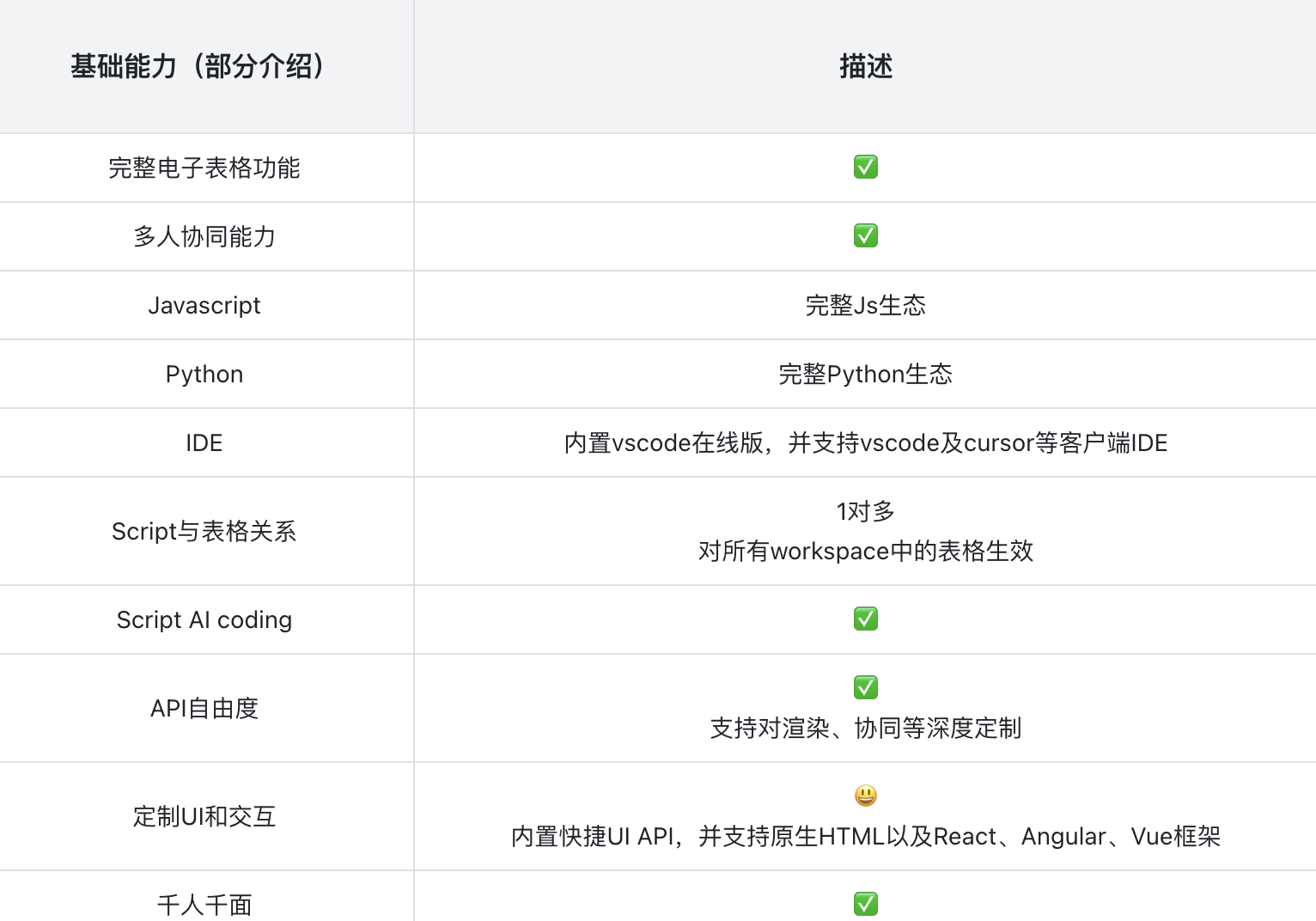
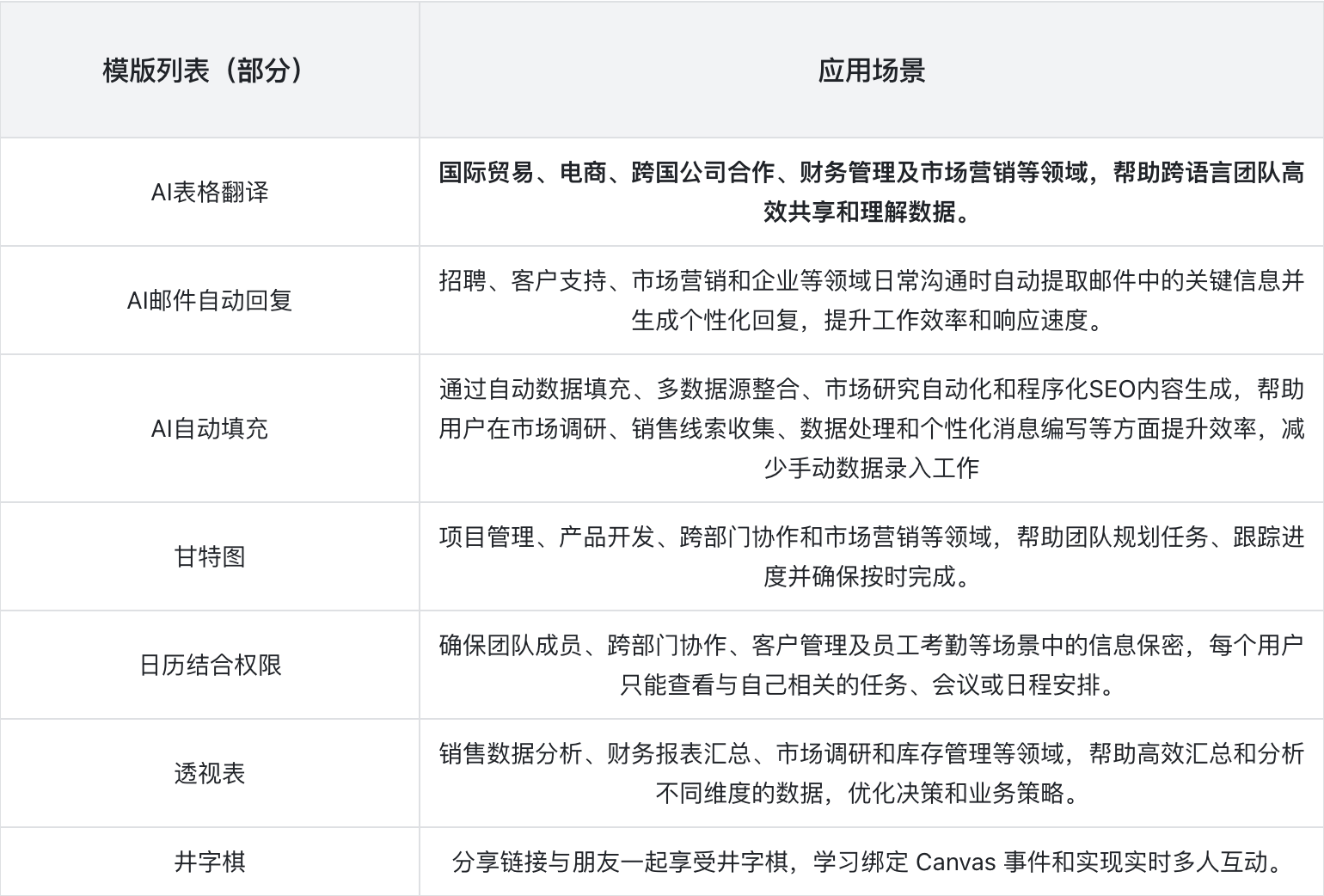


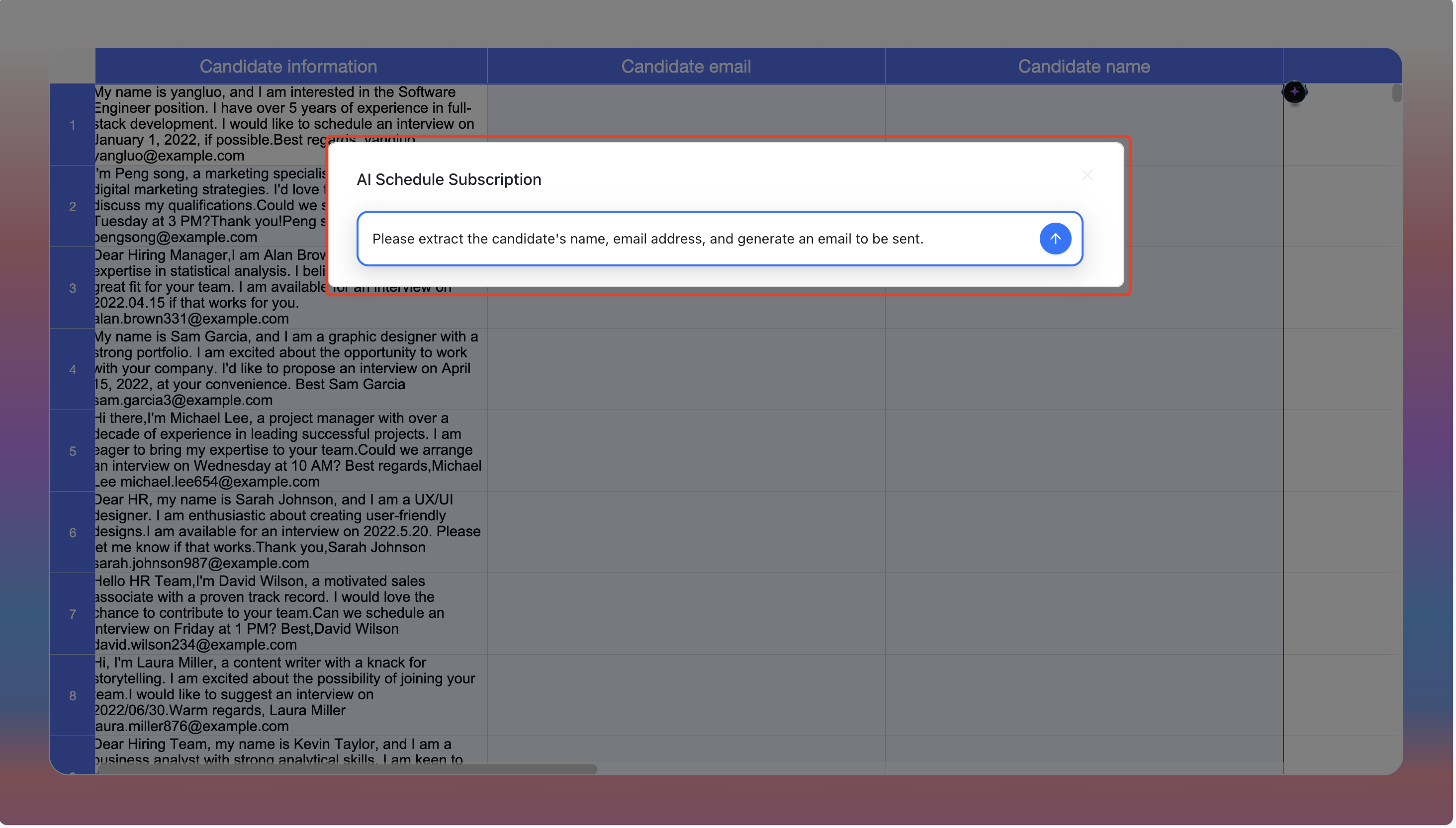
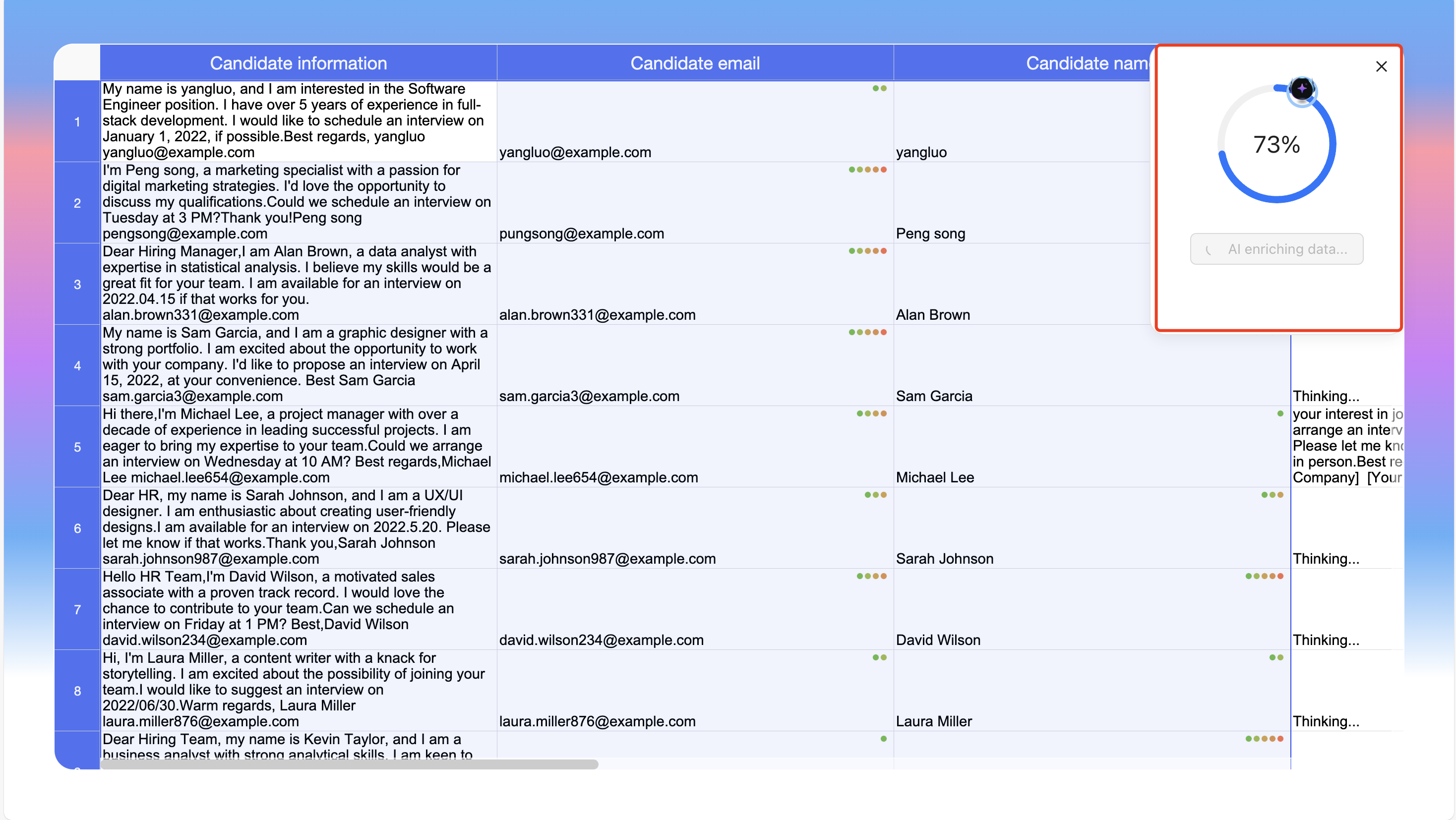
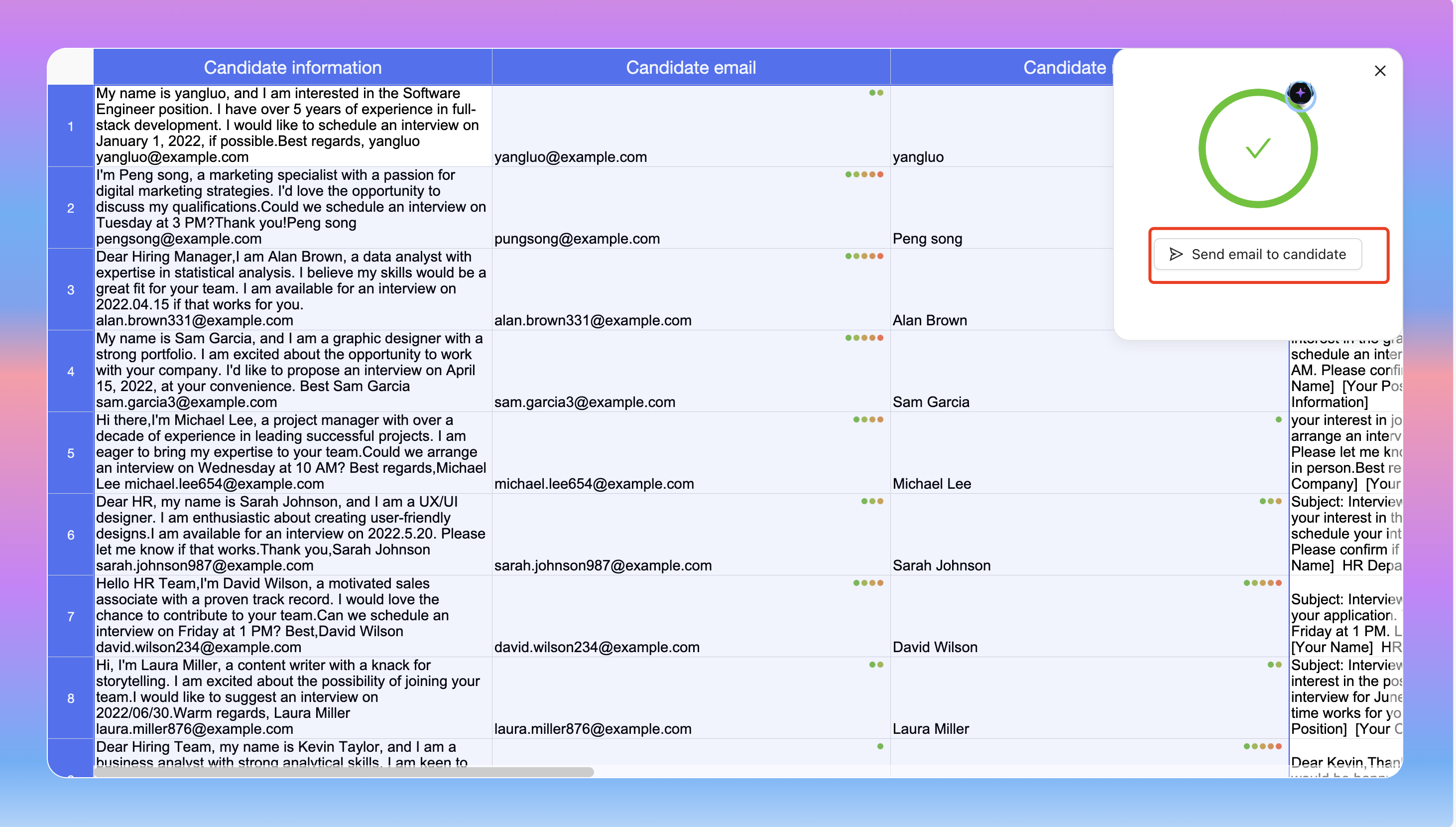
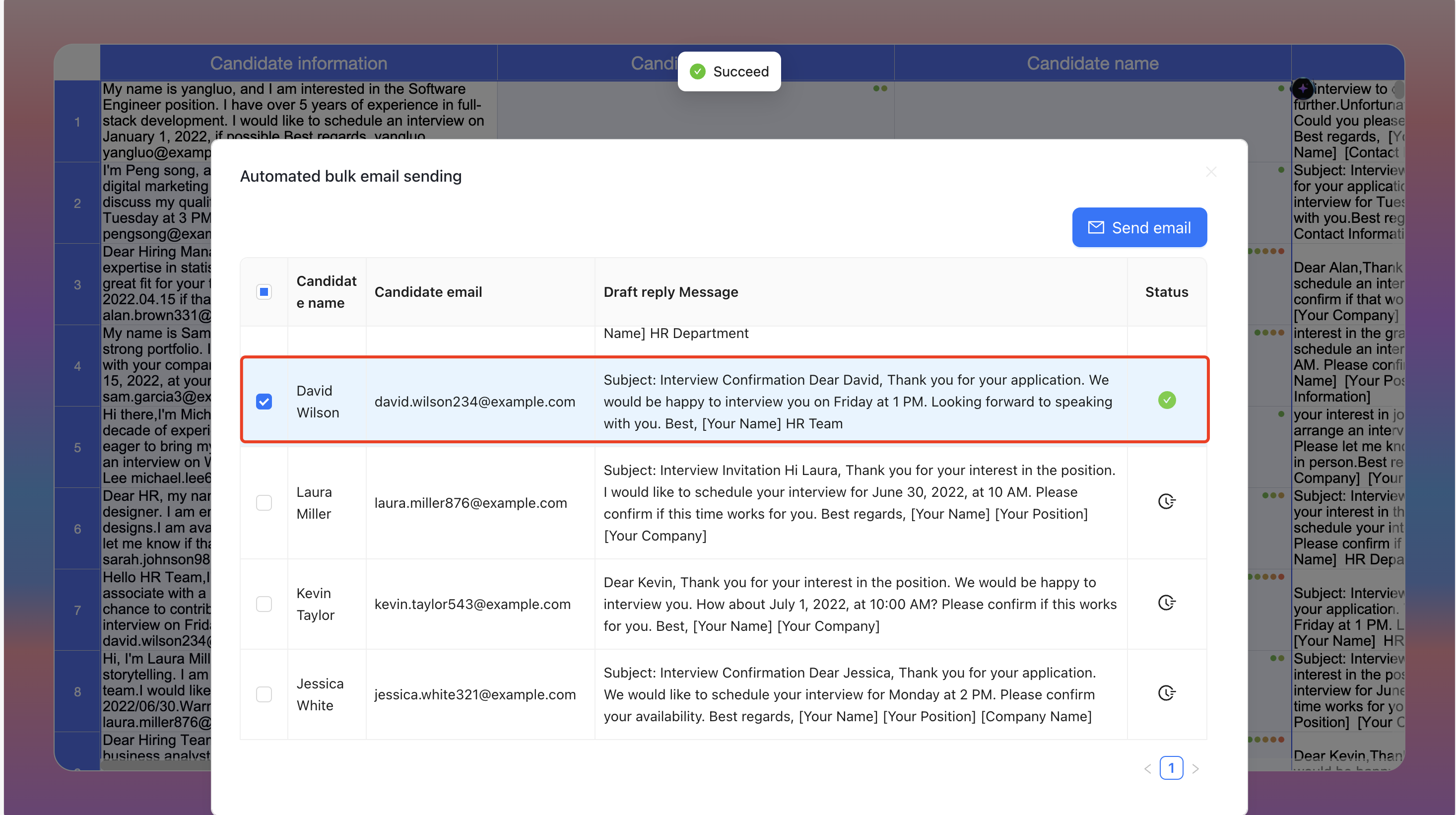

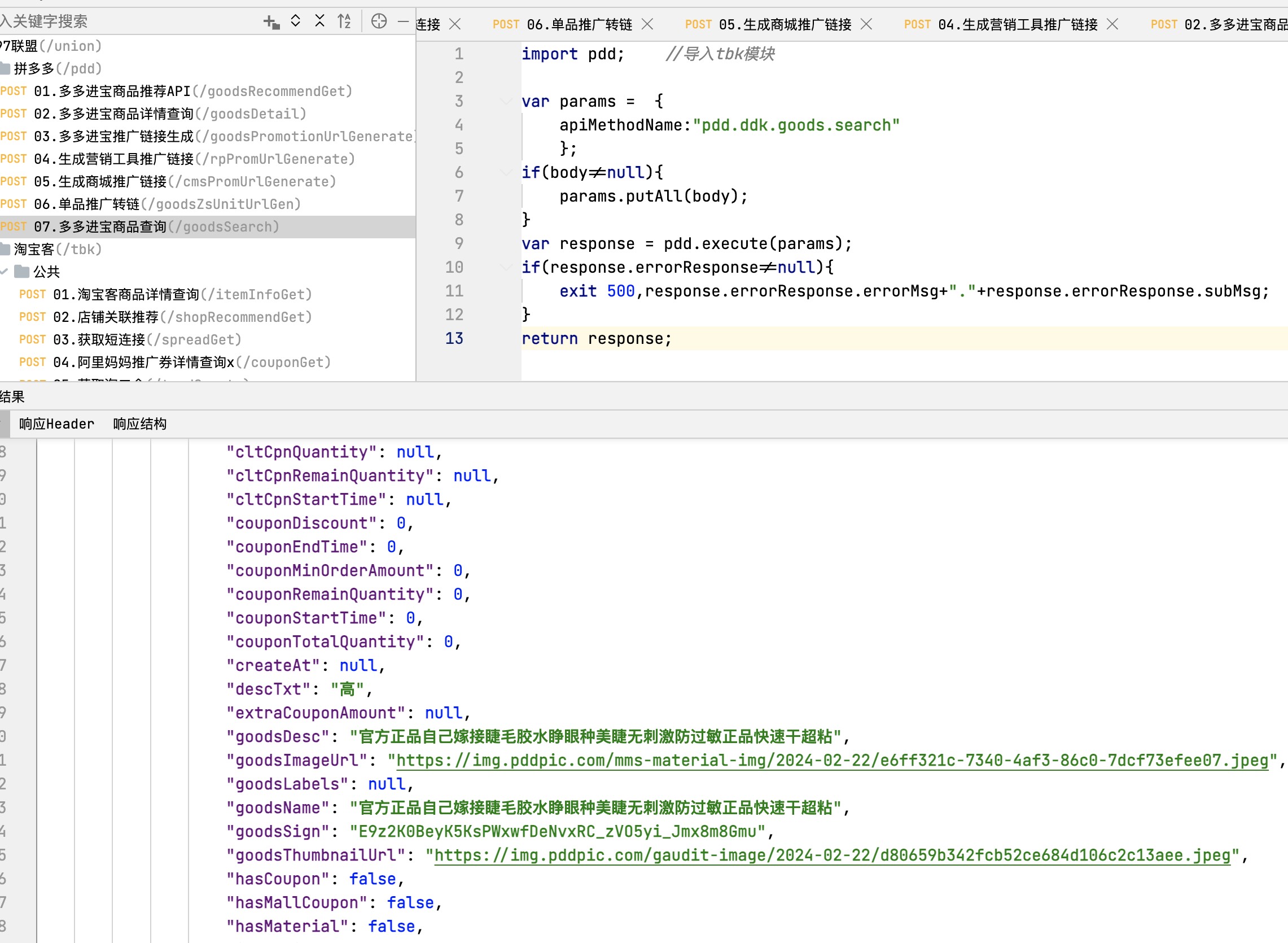
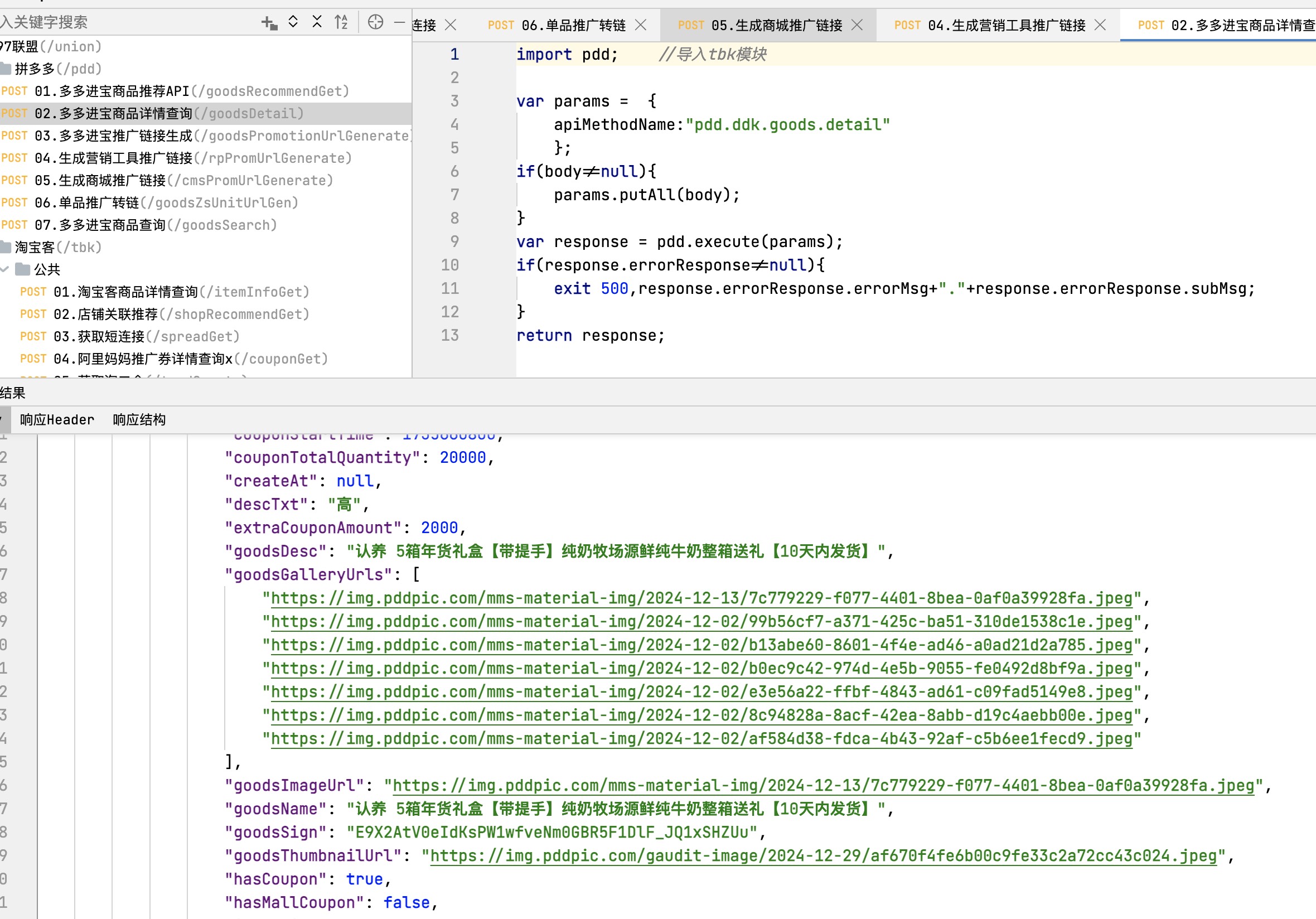





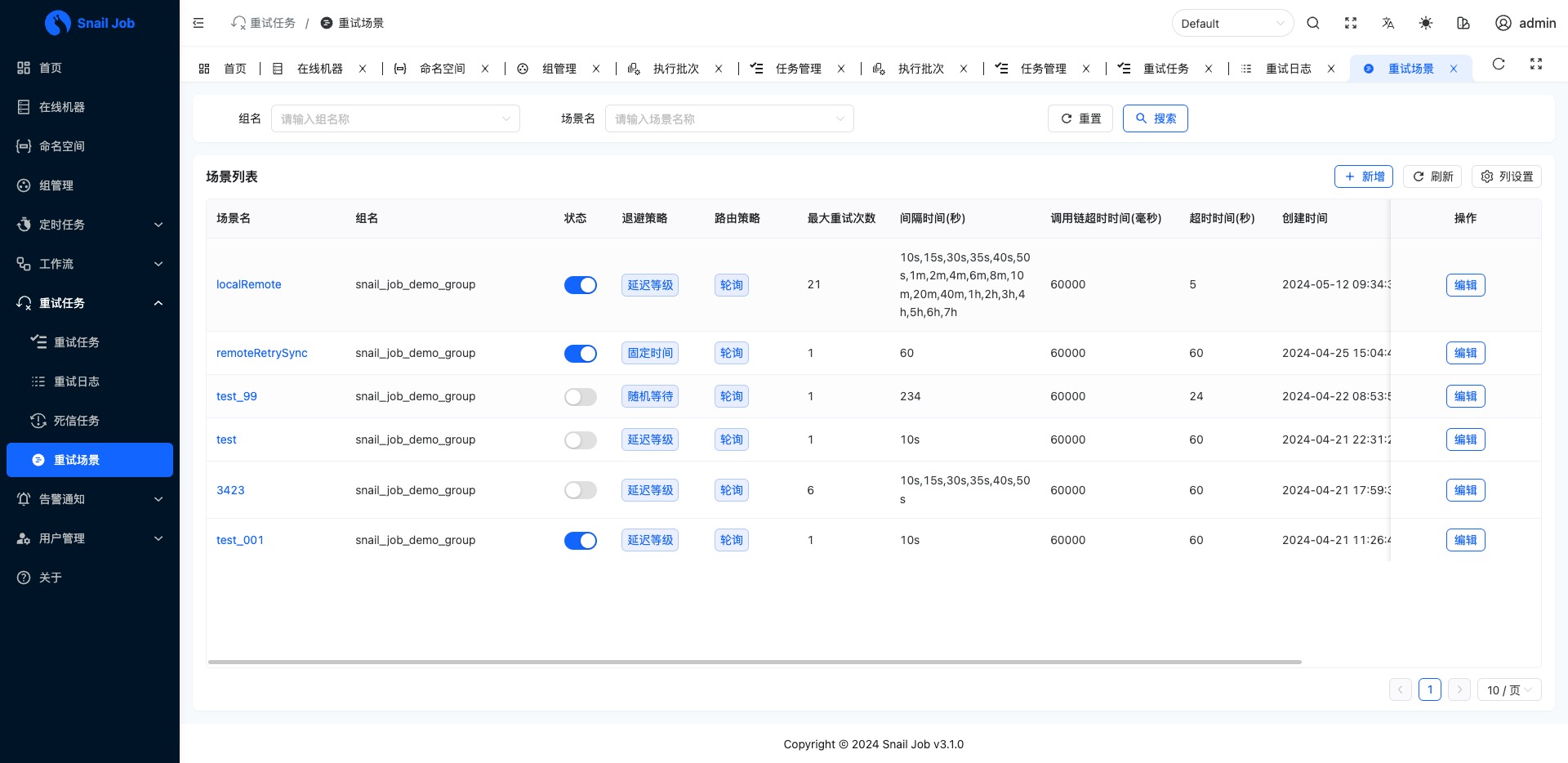
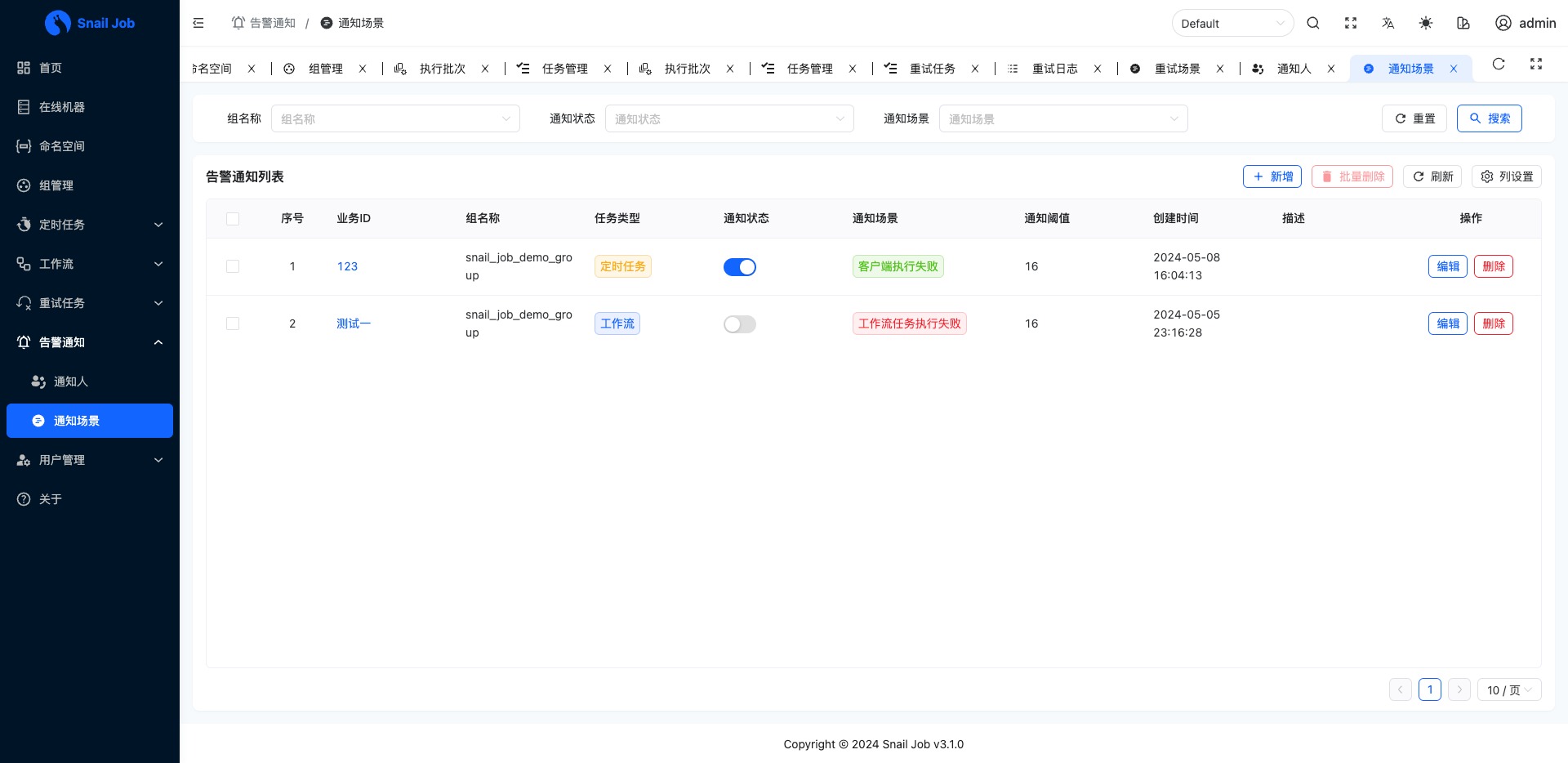
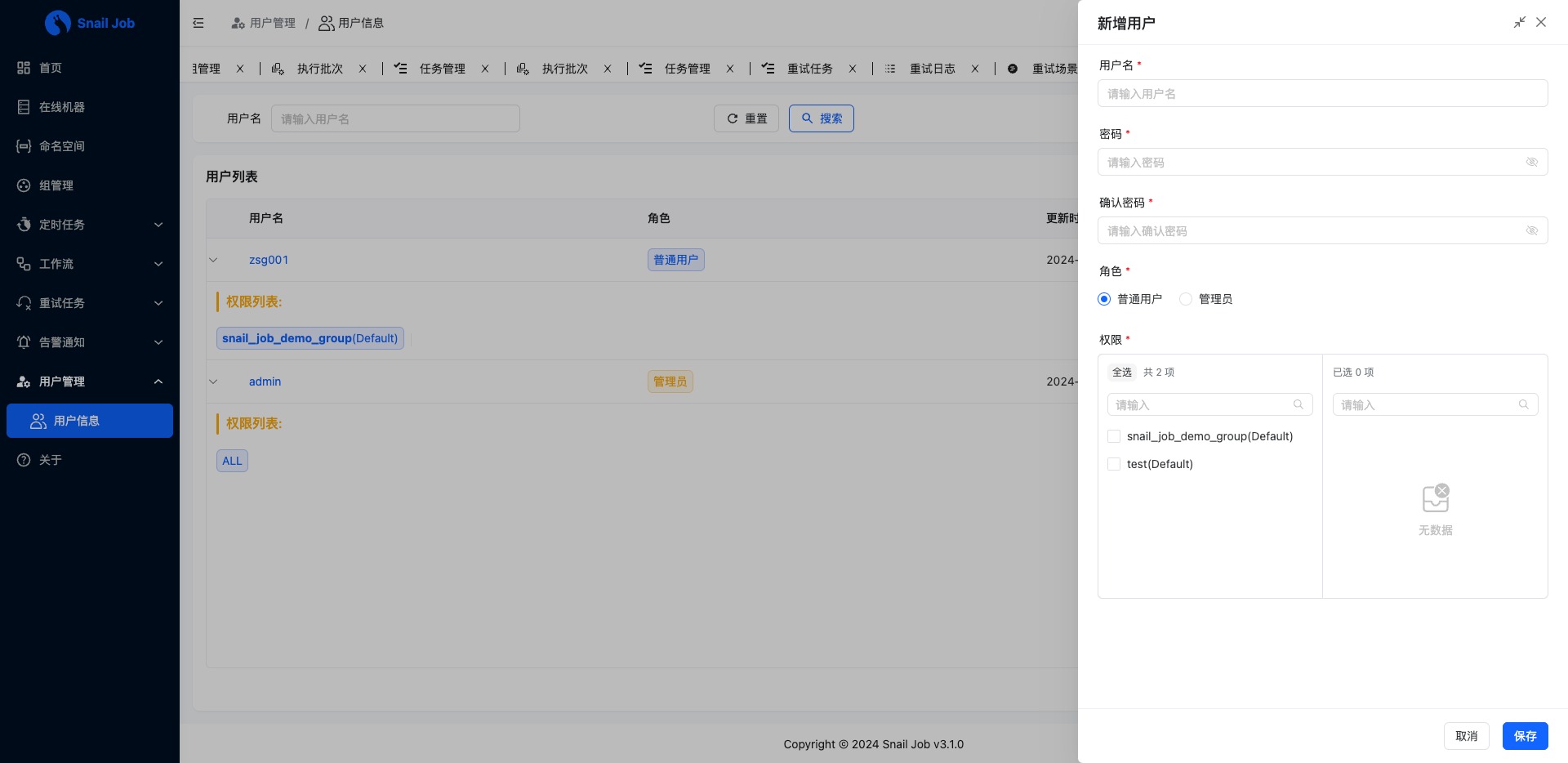




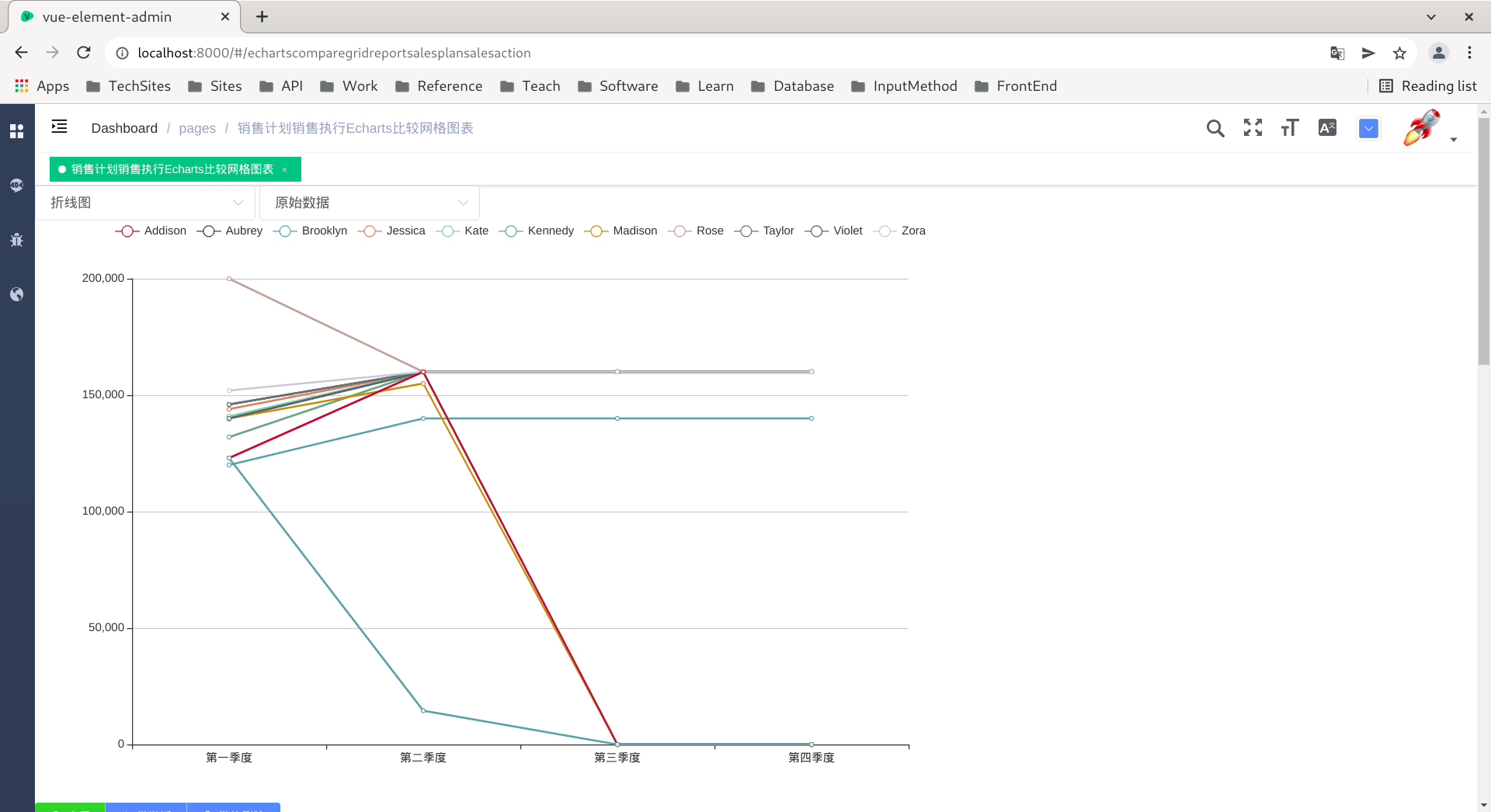 、
、

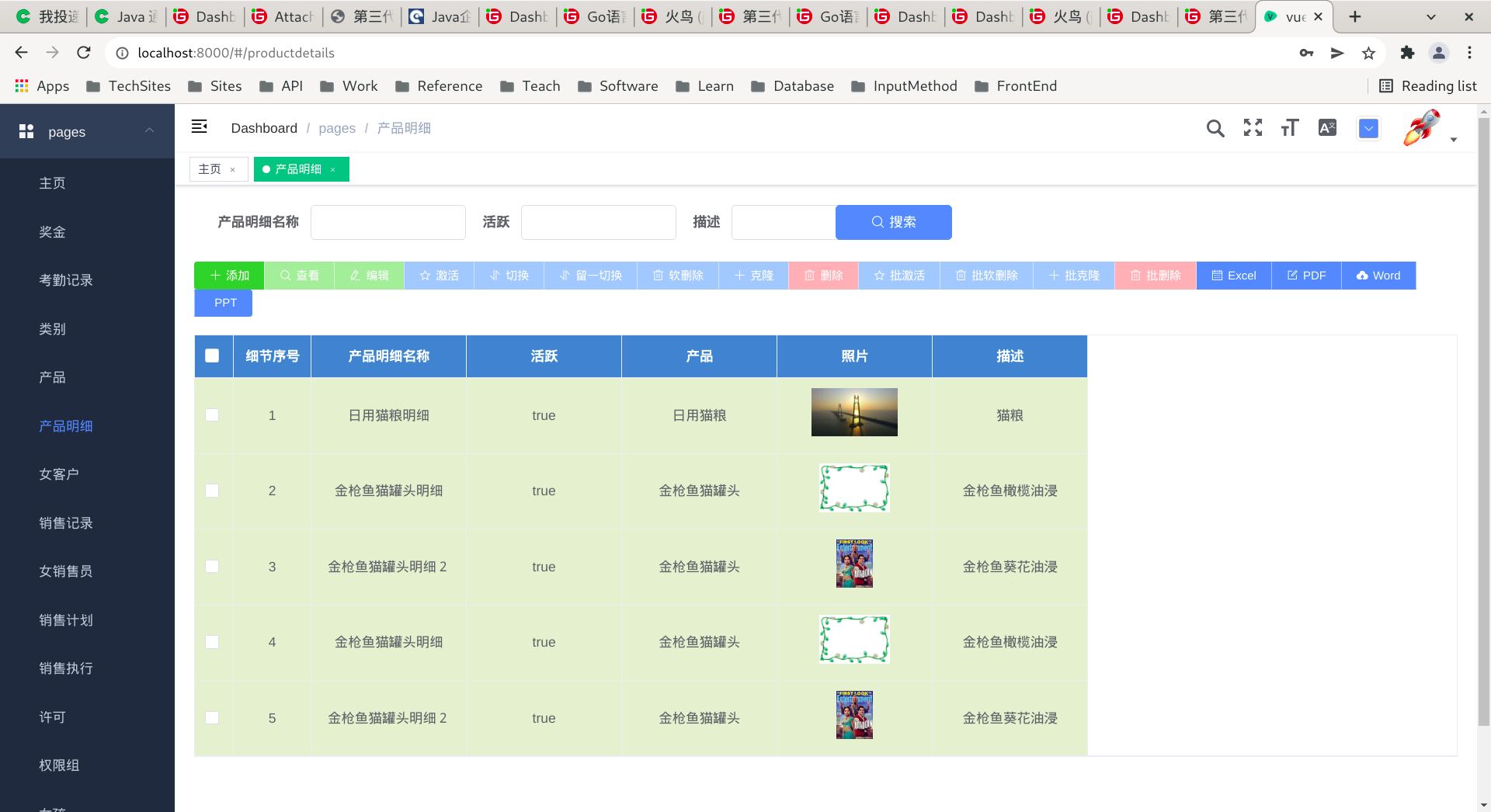




























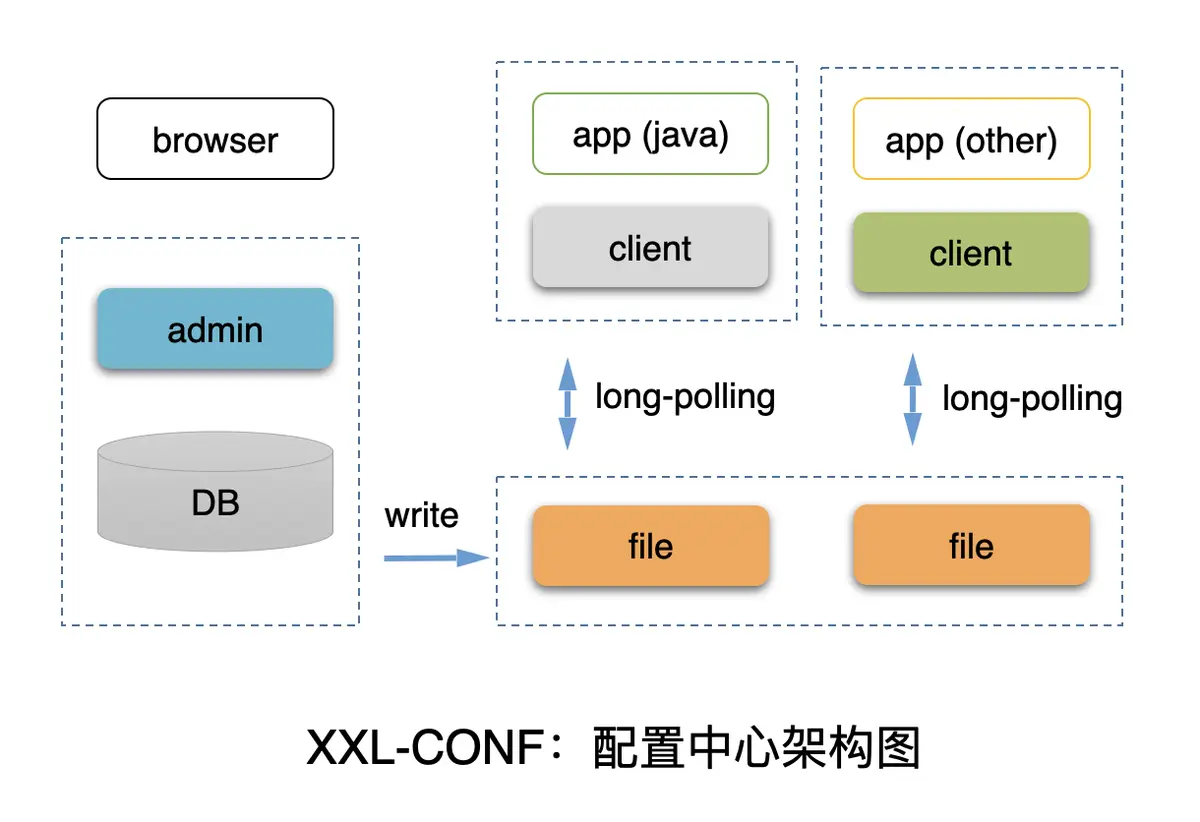
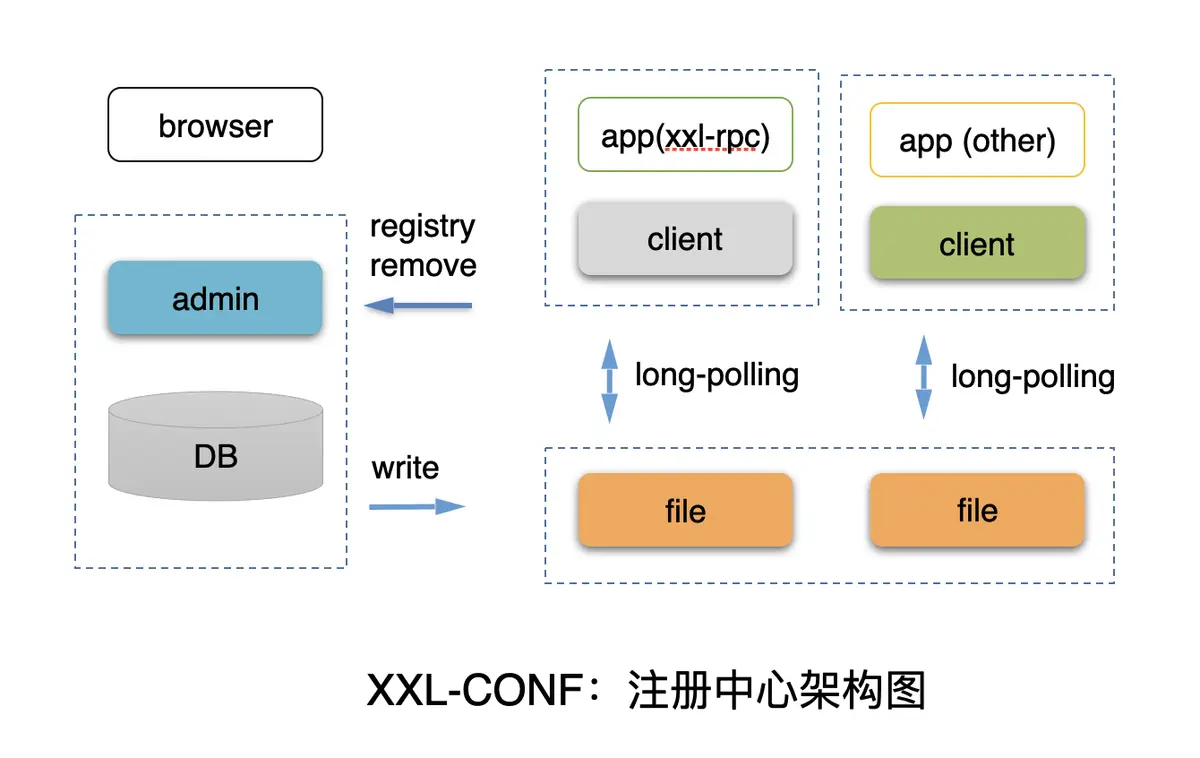
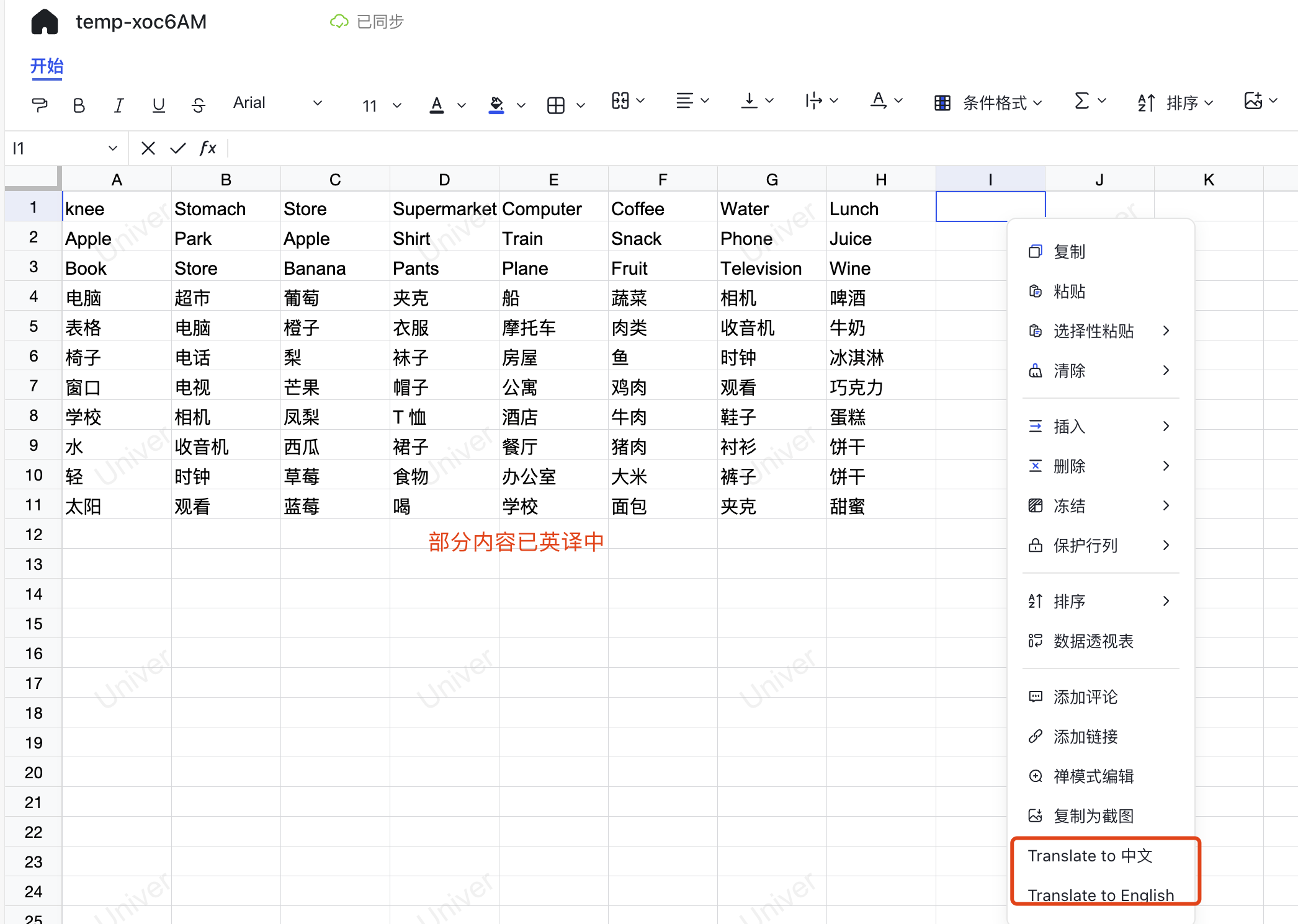



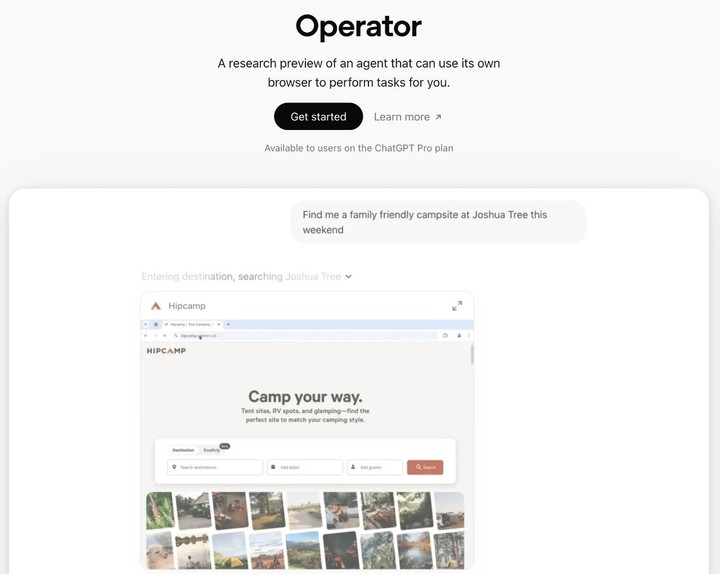
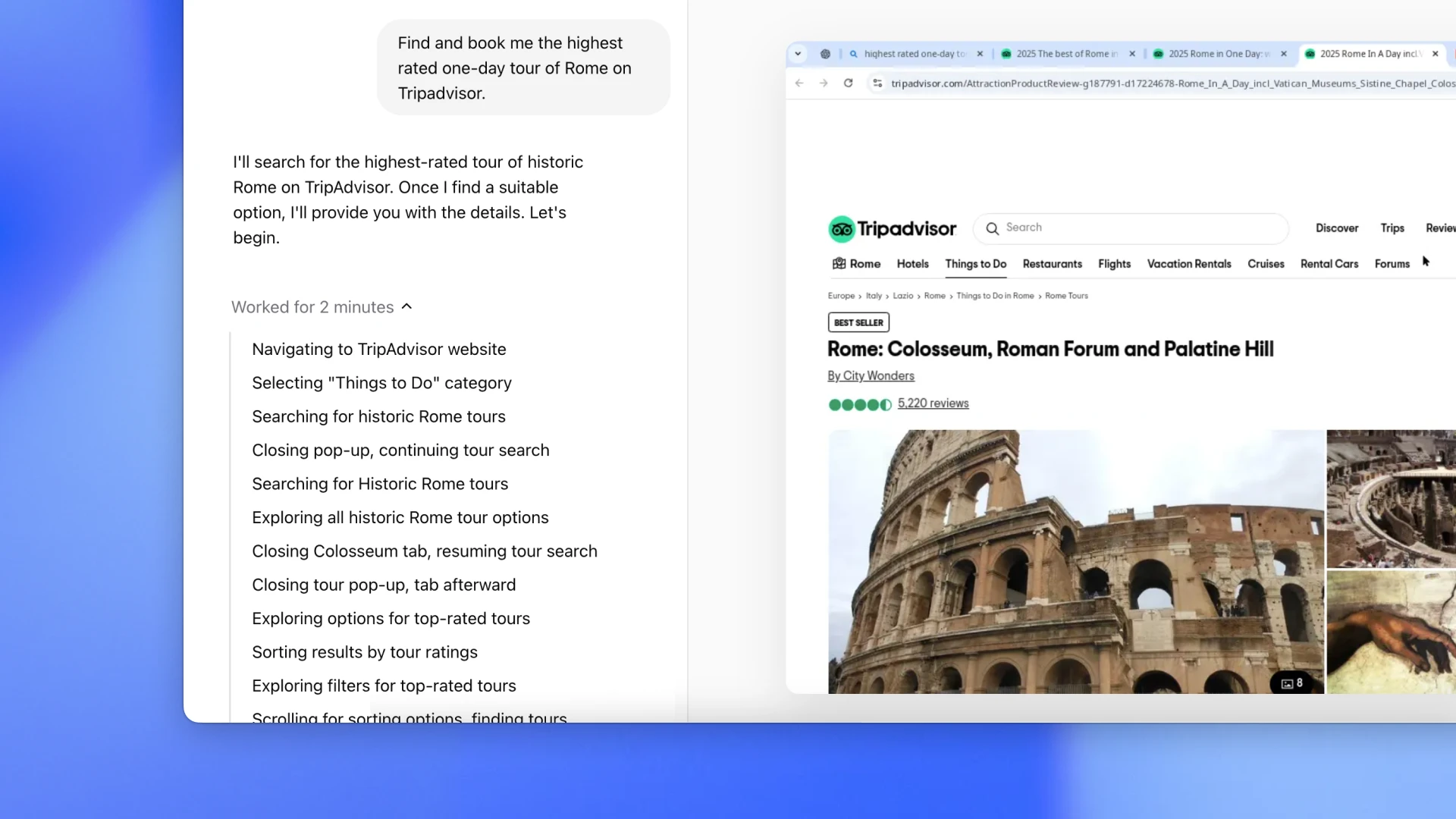
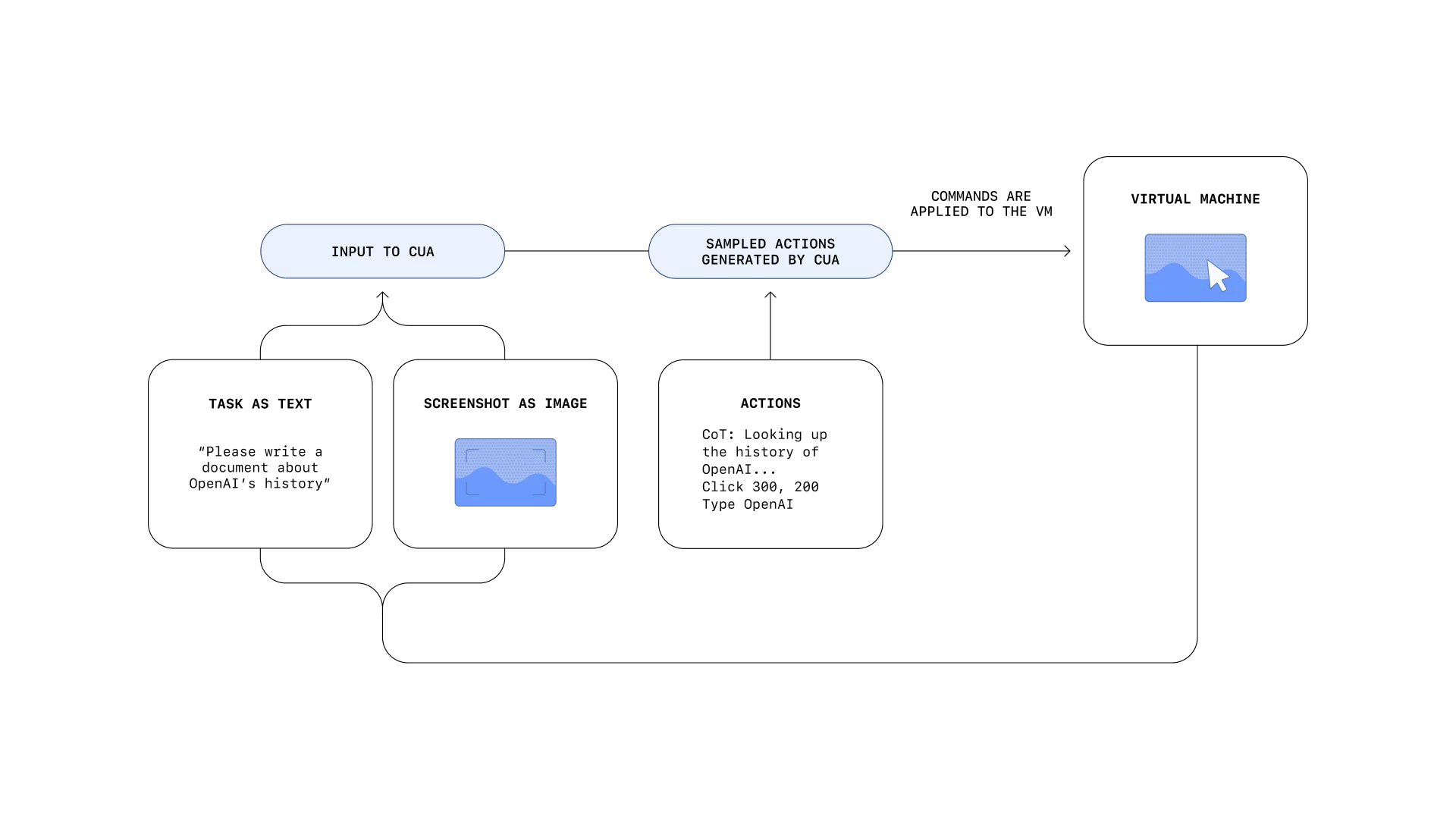




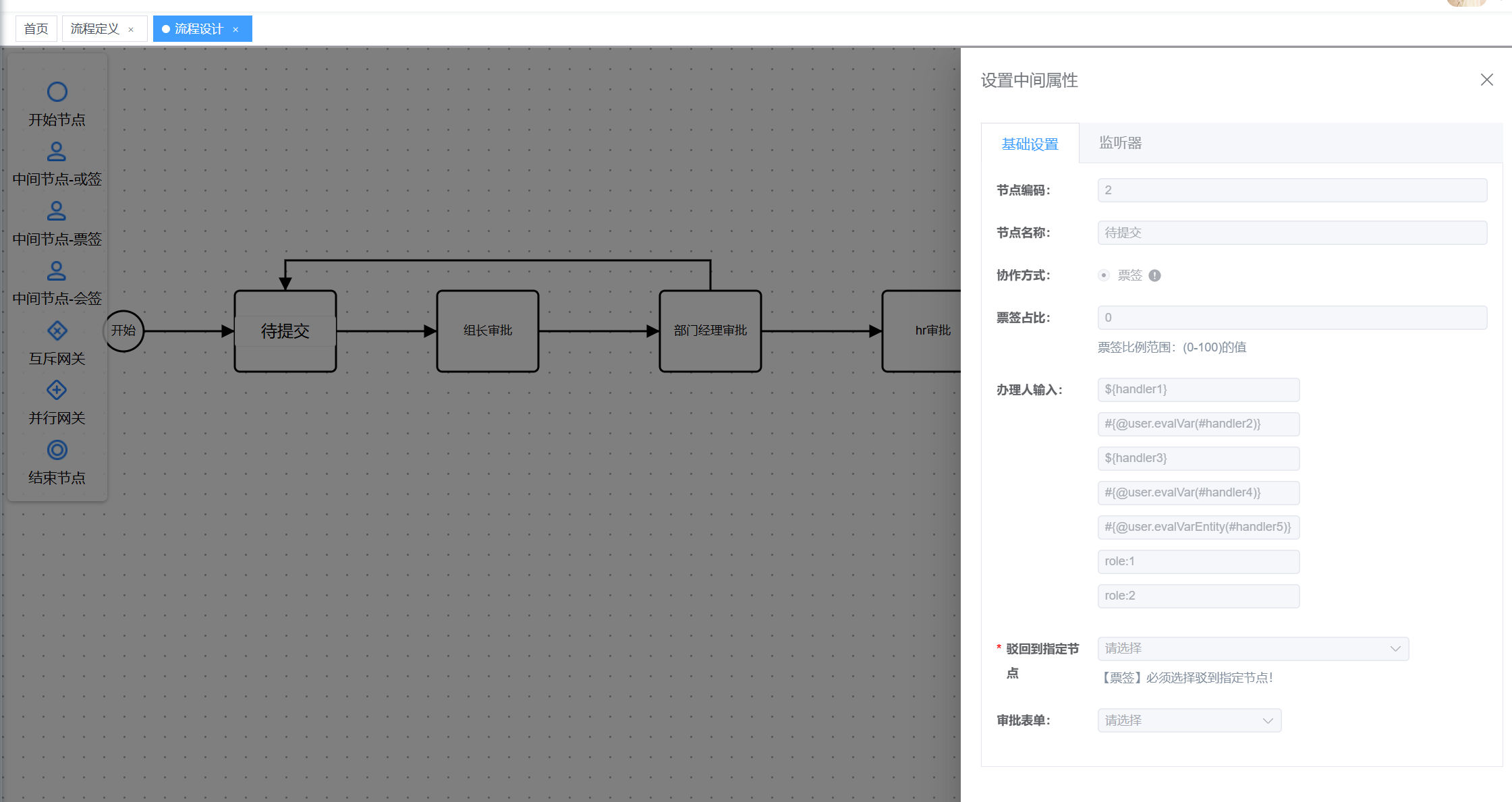


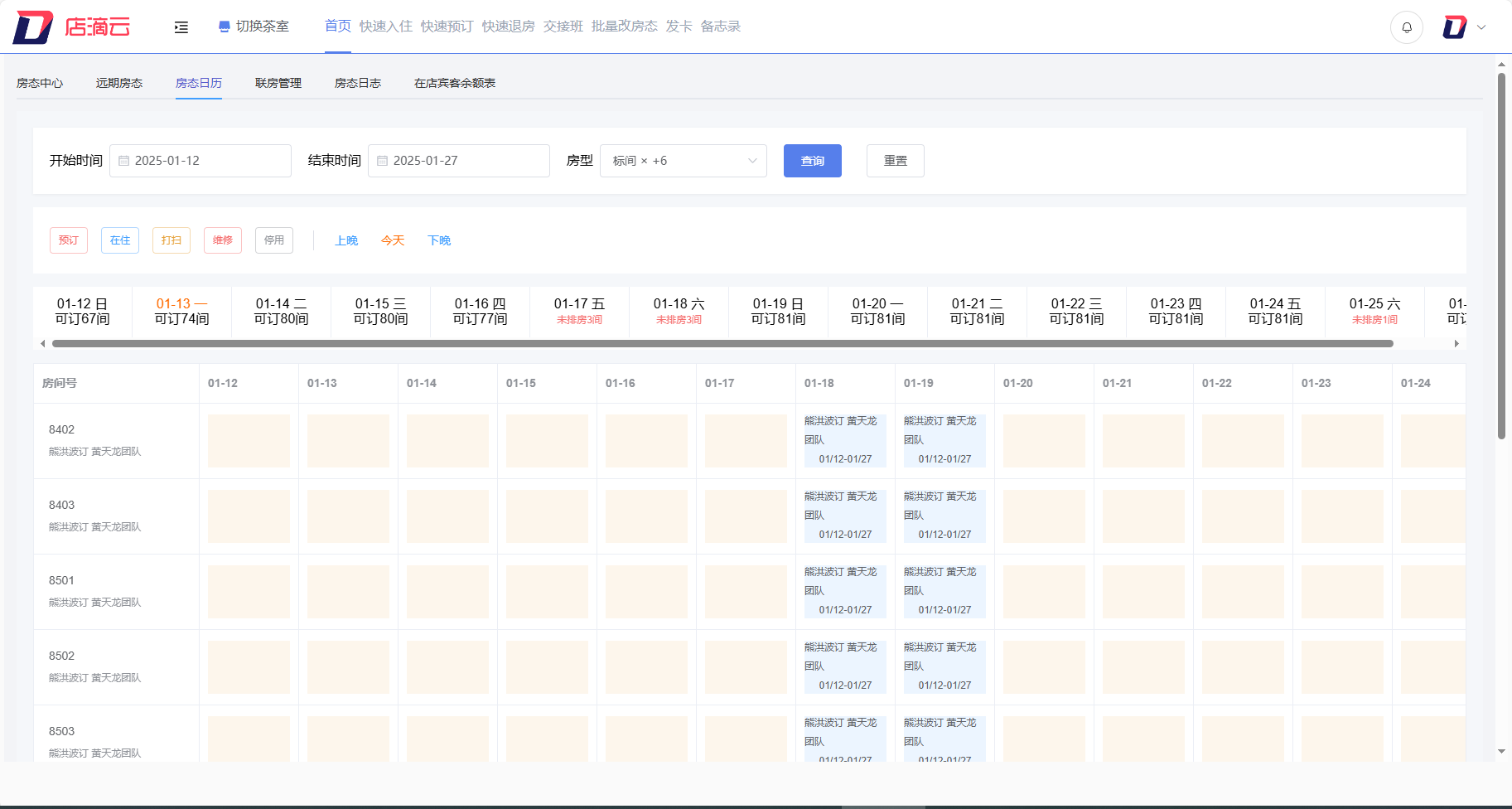
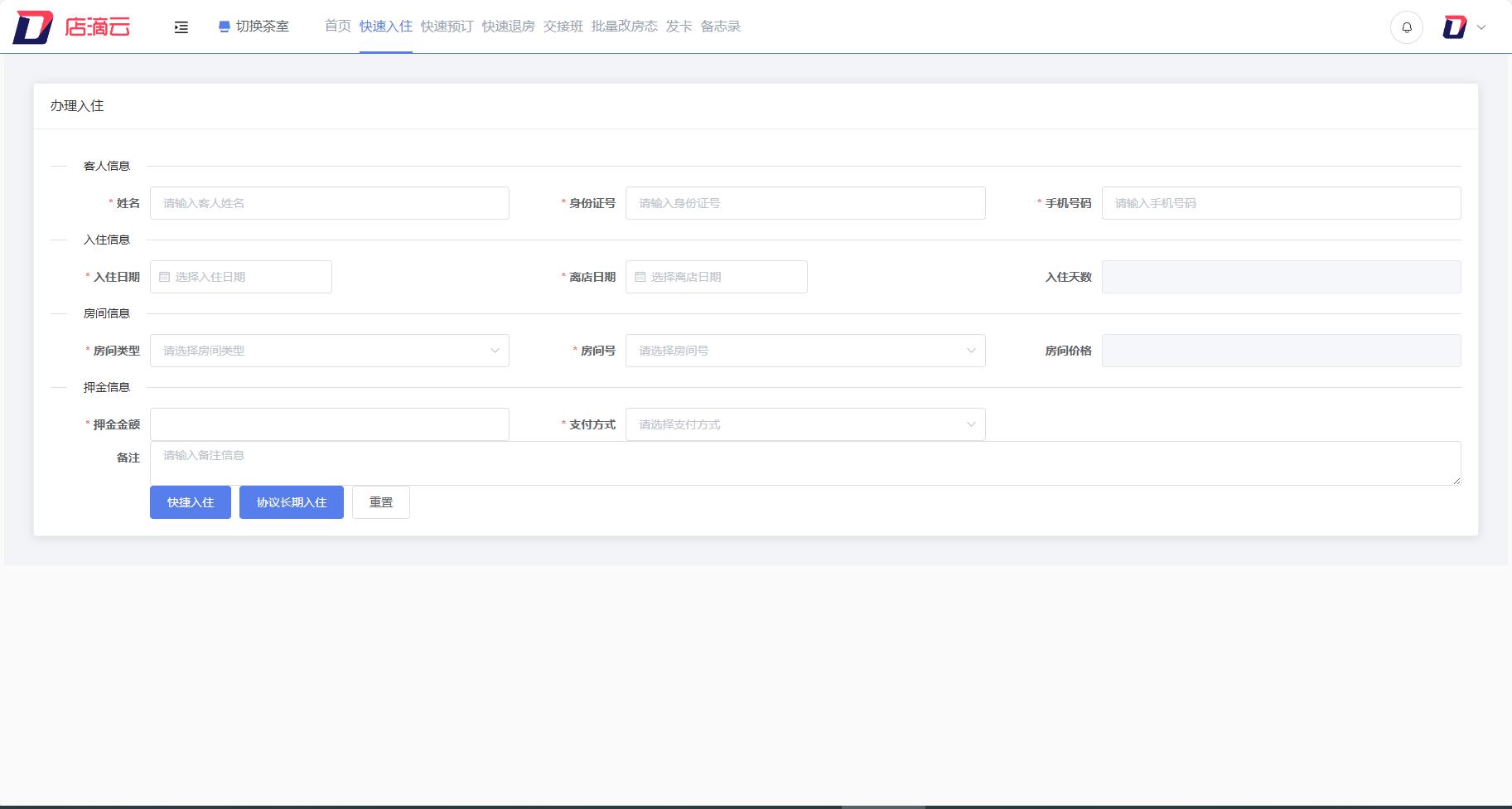
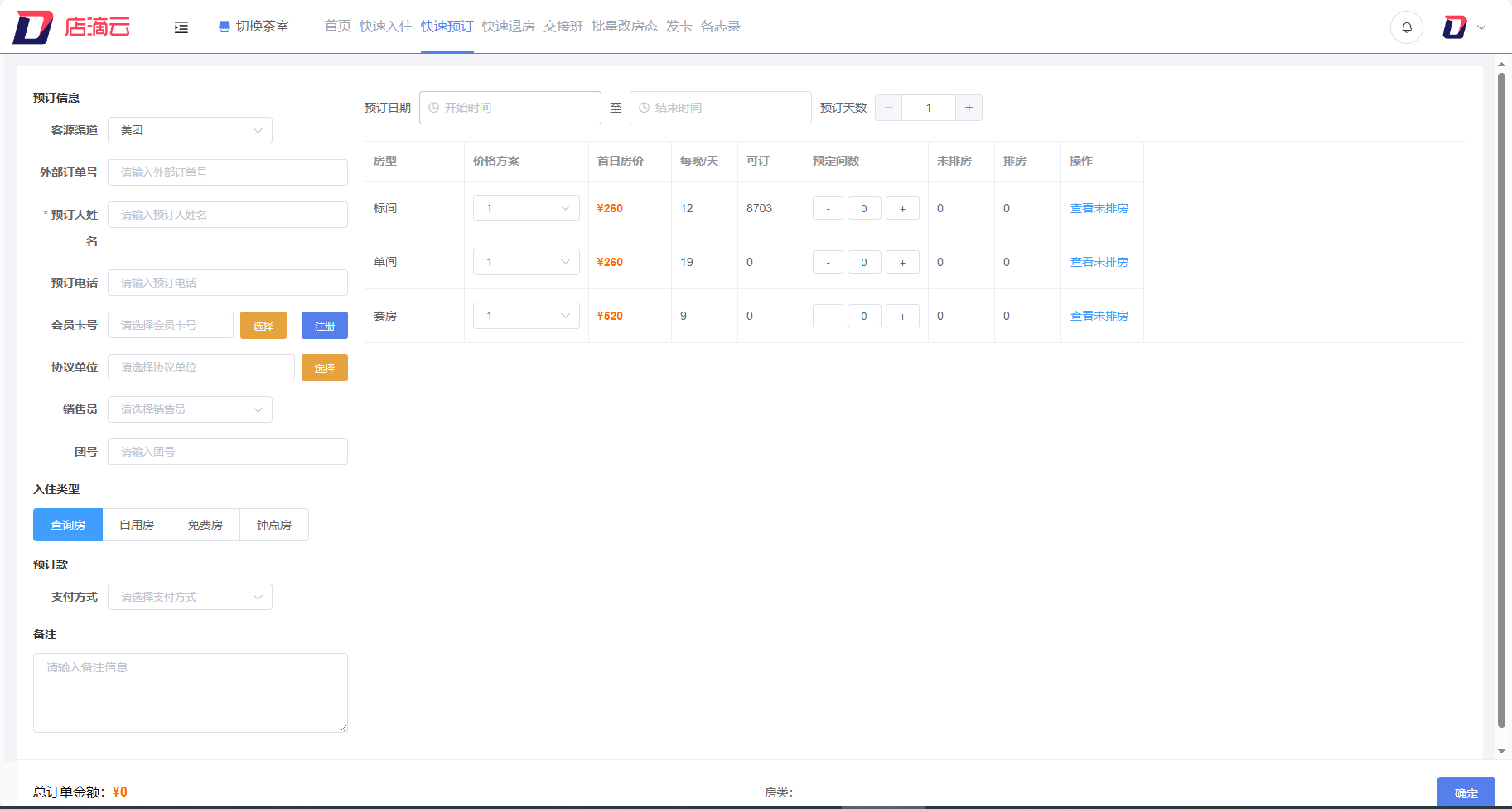
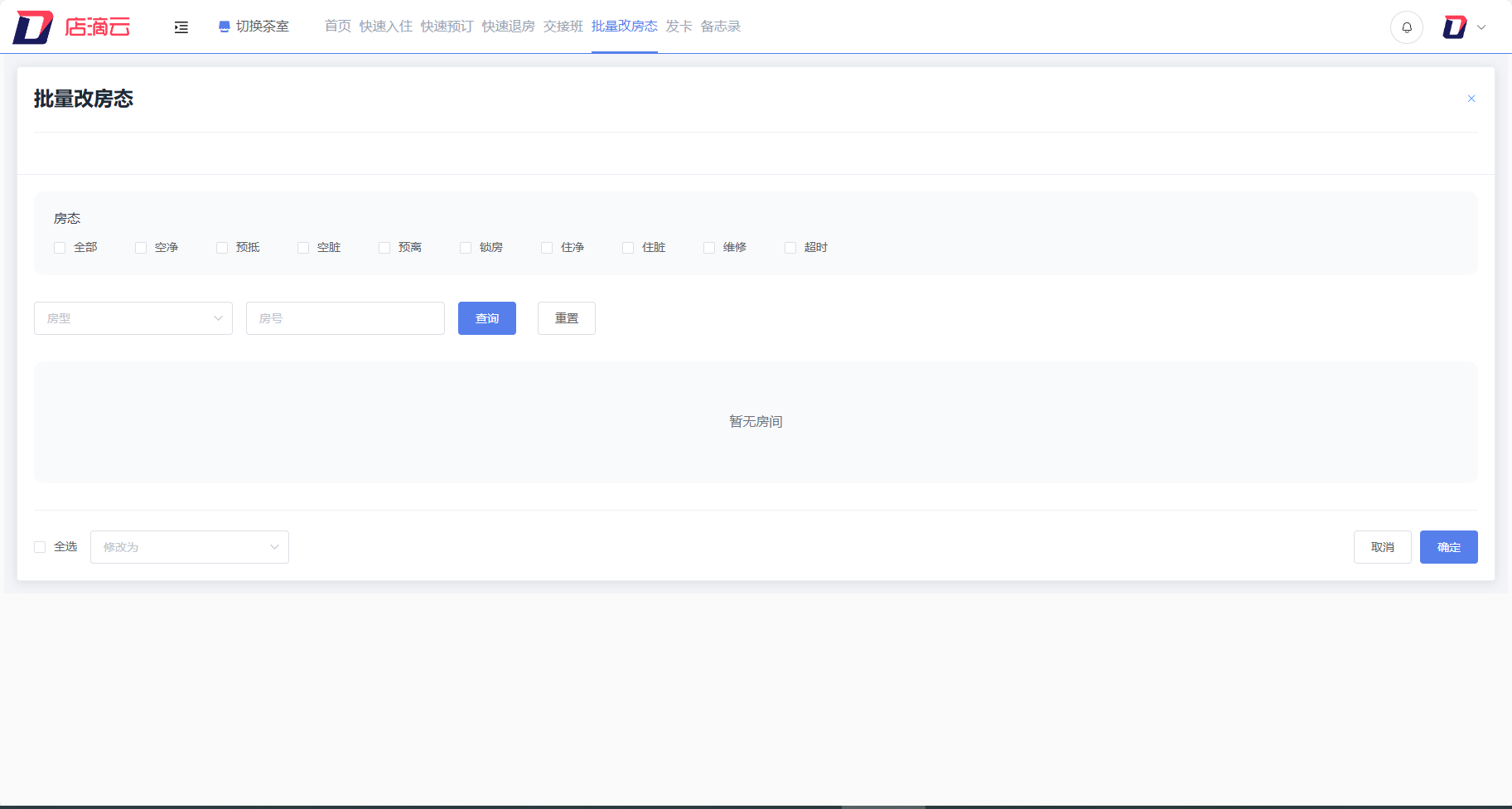











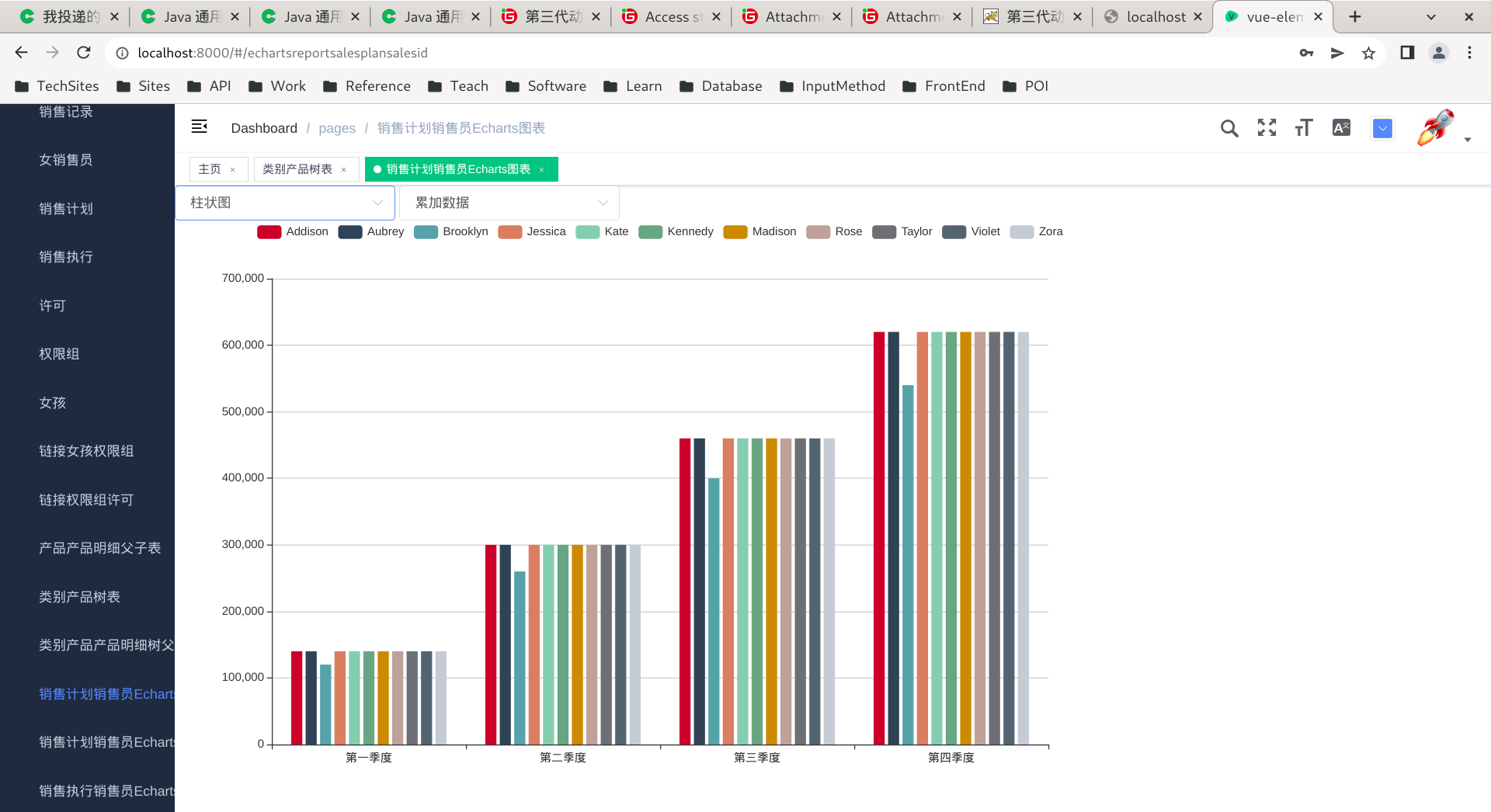
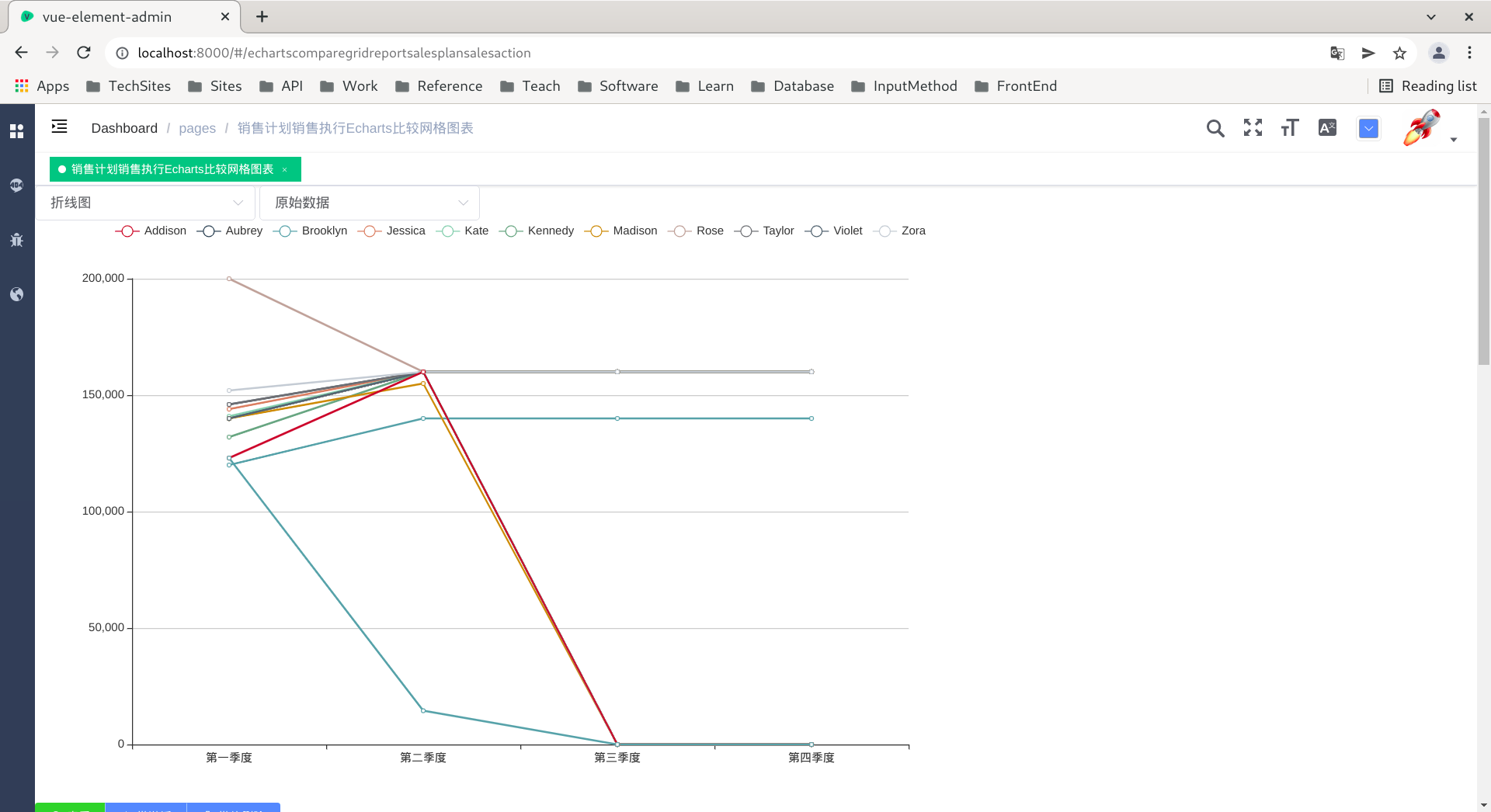 、
、
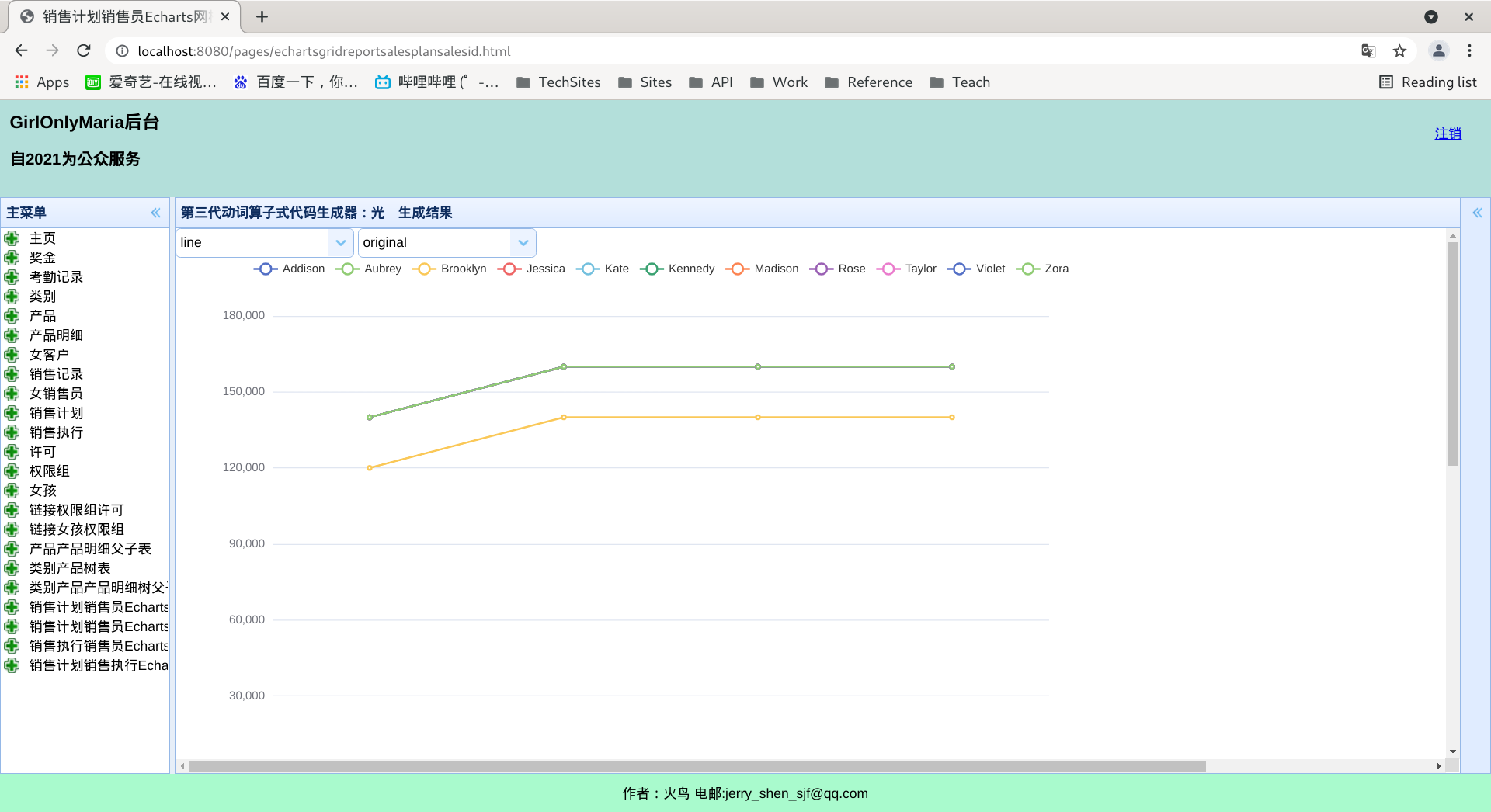
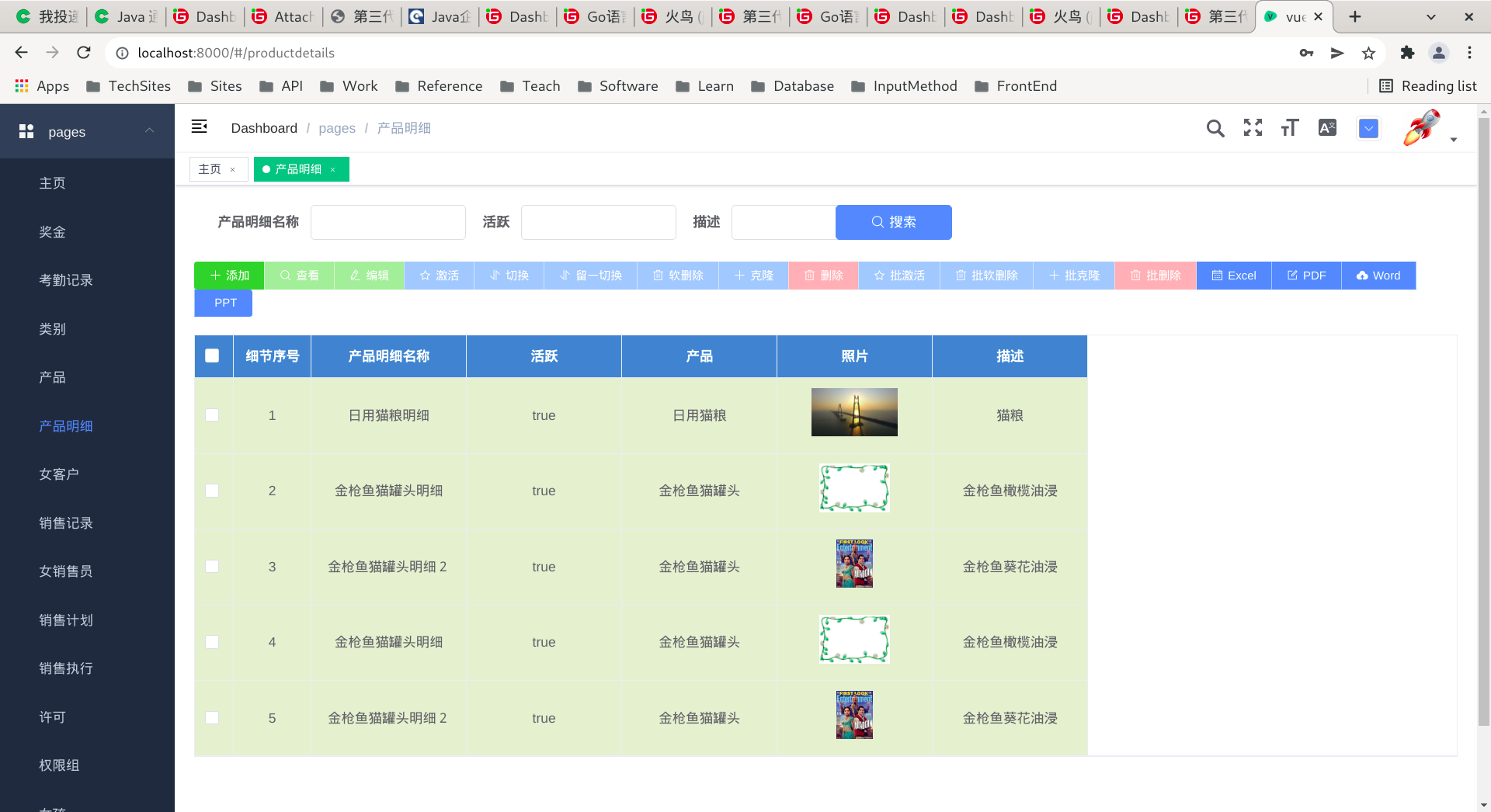

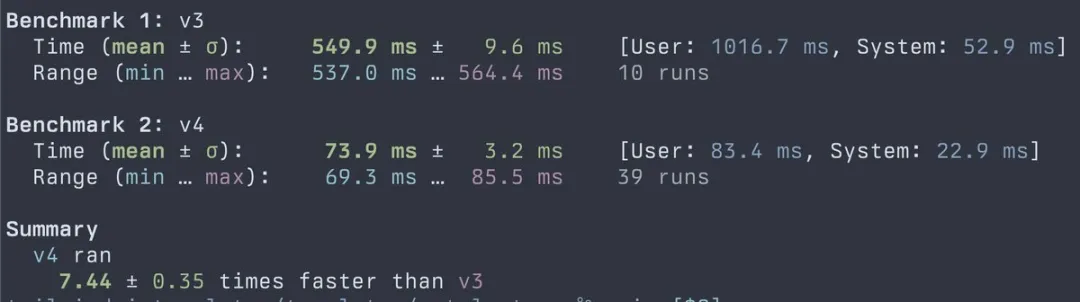
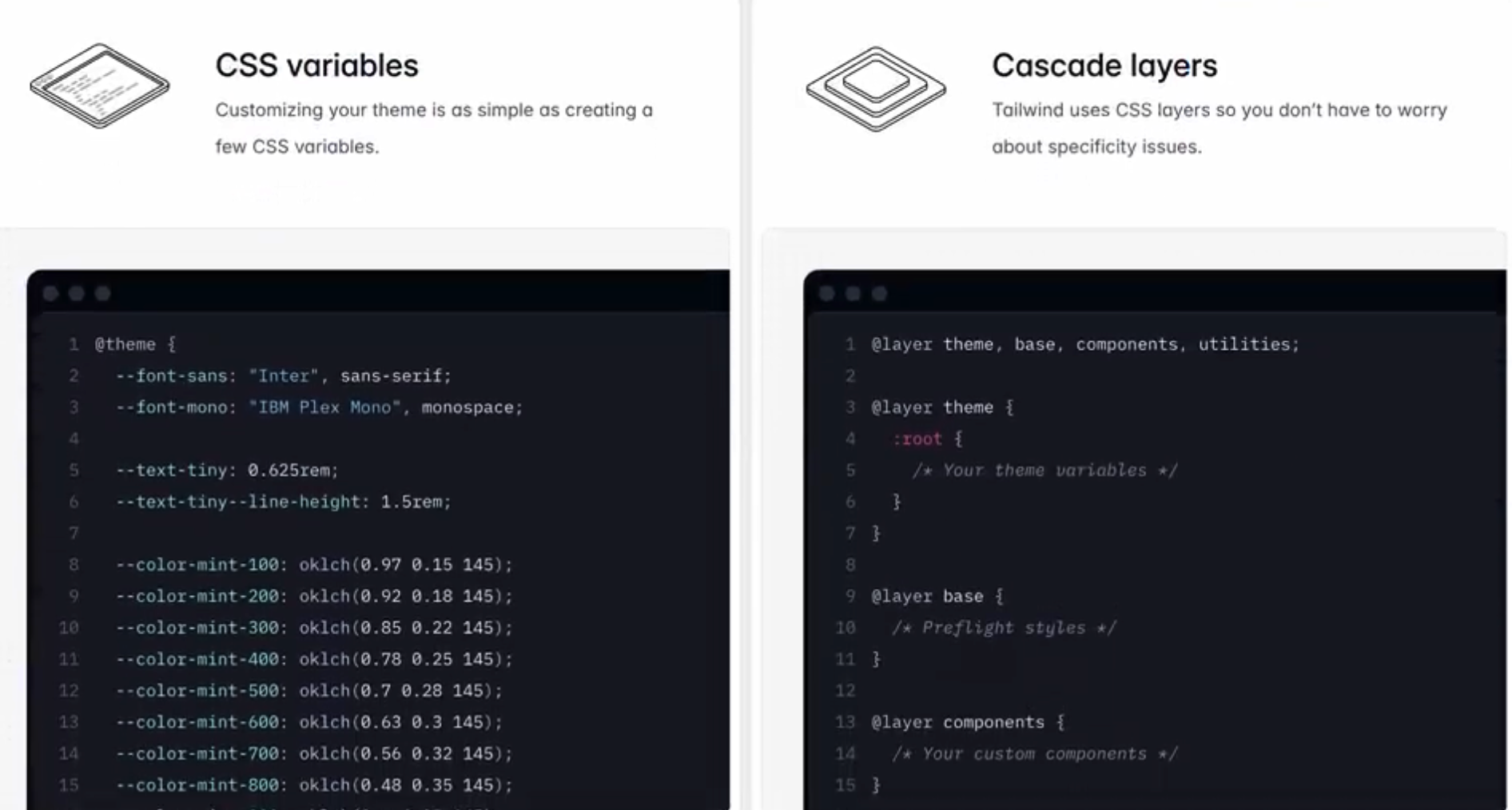
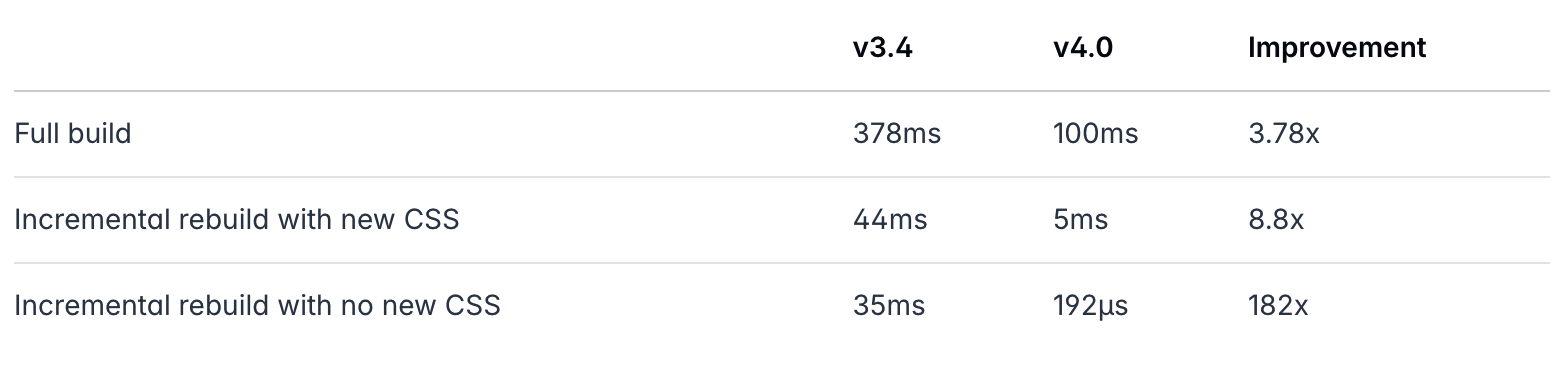




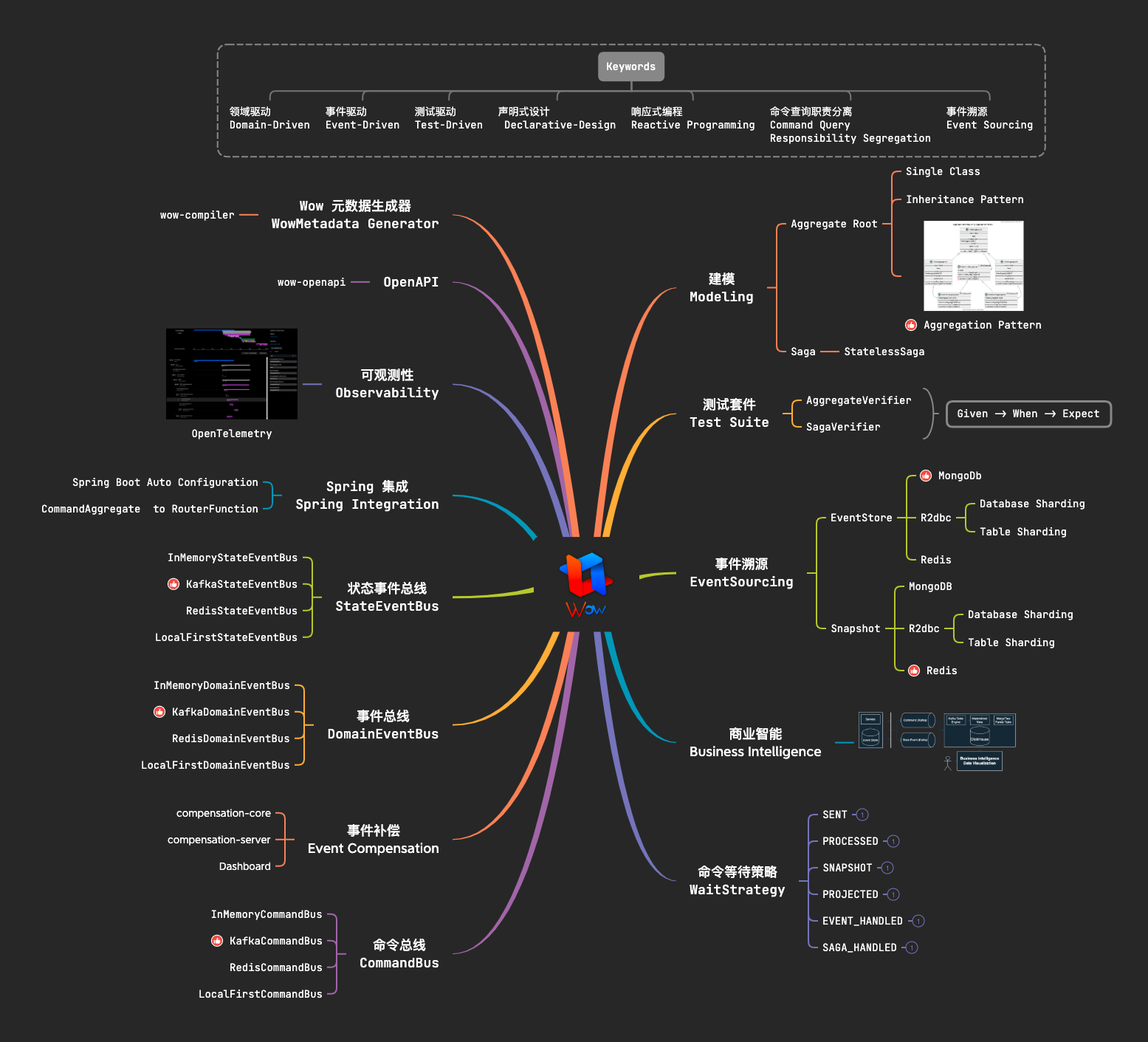

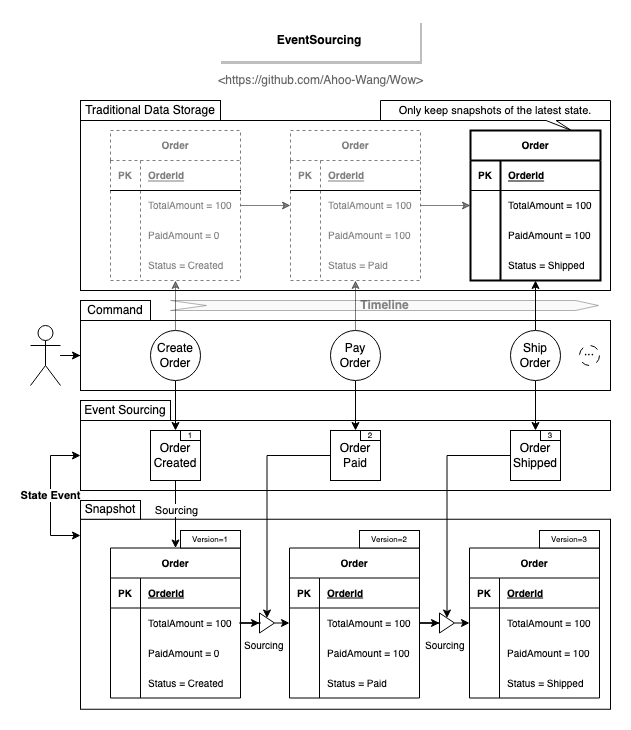
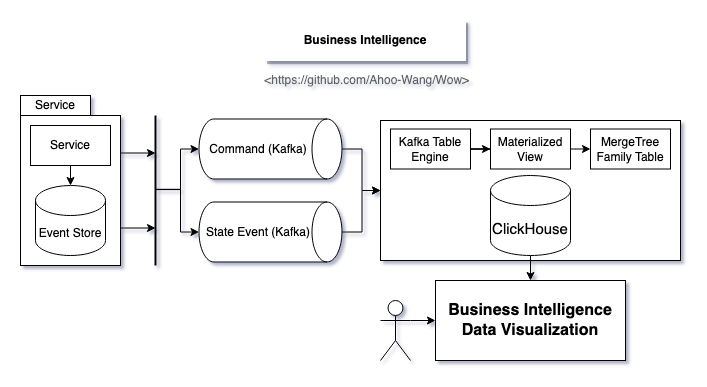
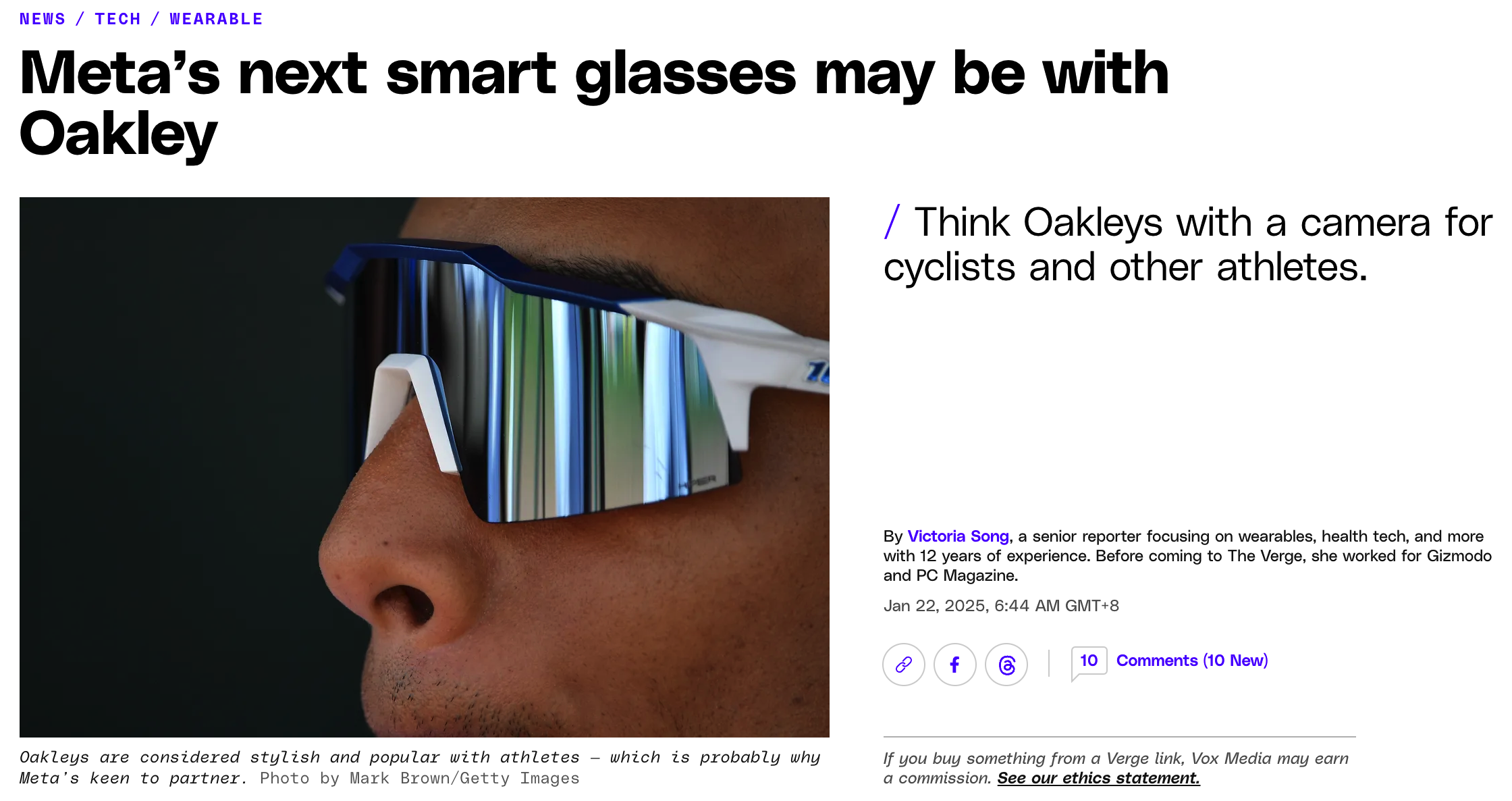












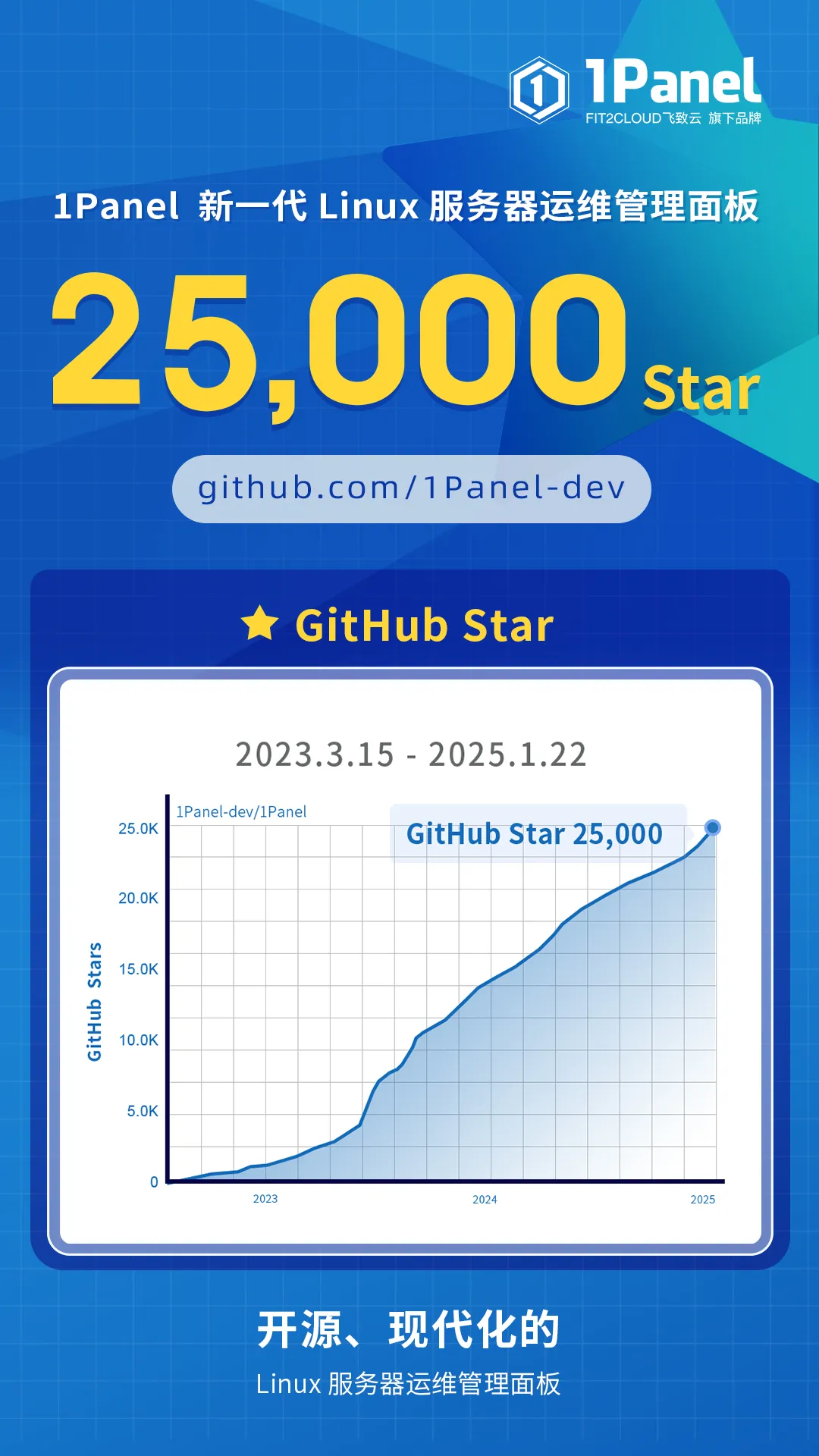









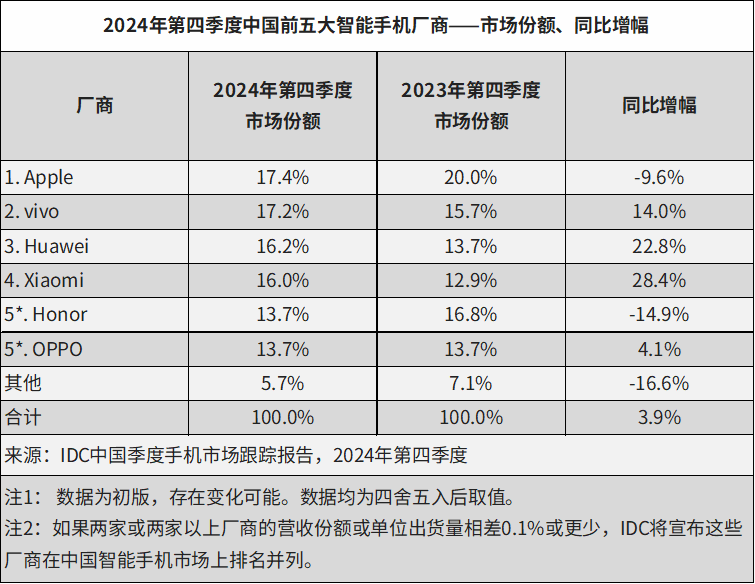










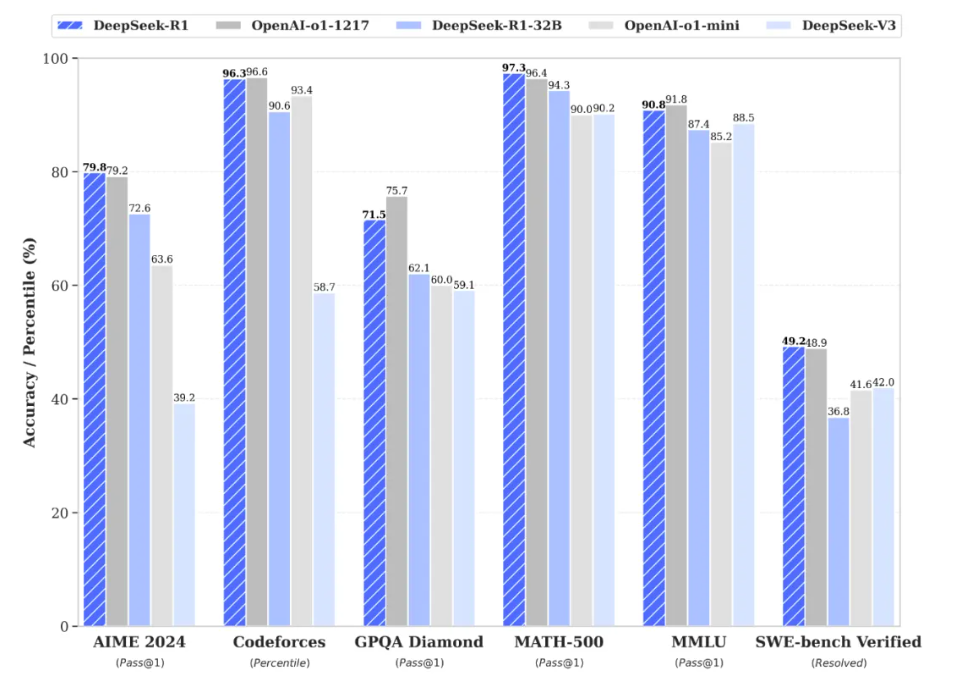
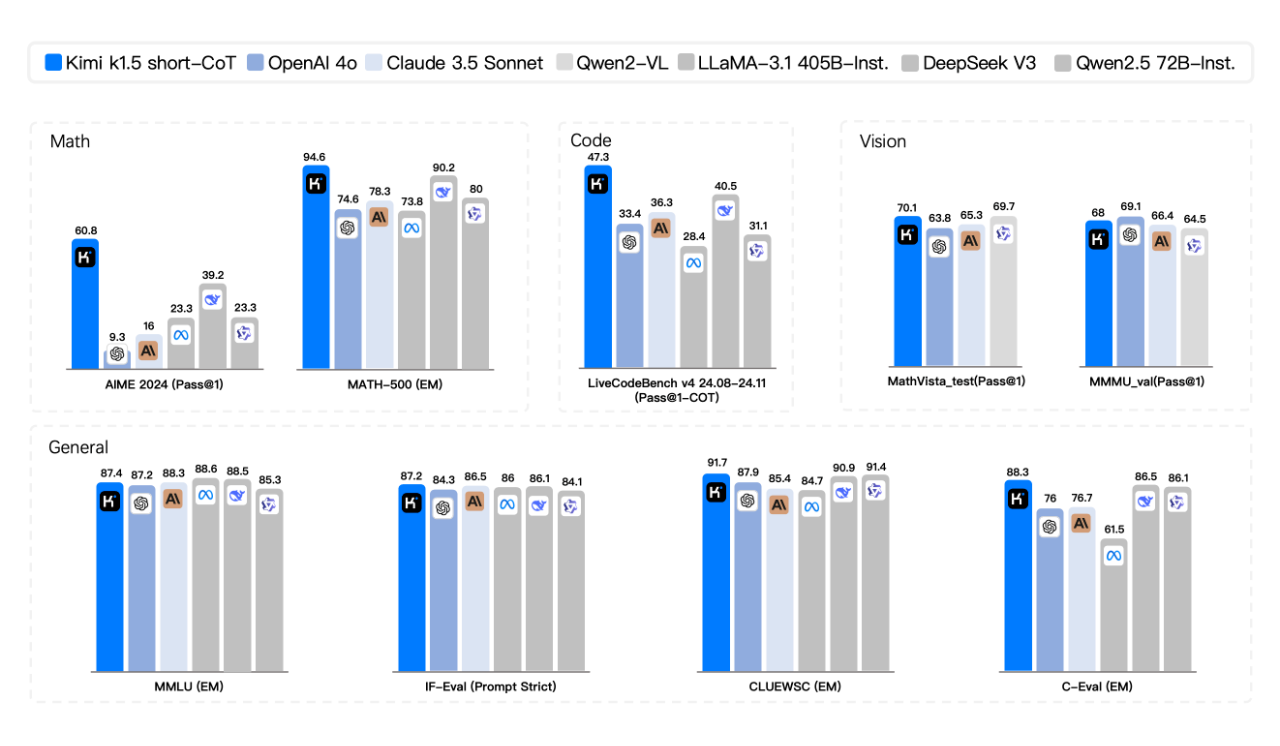
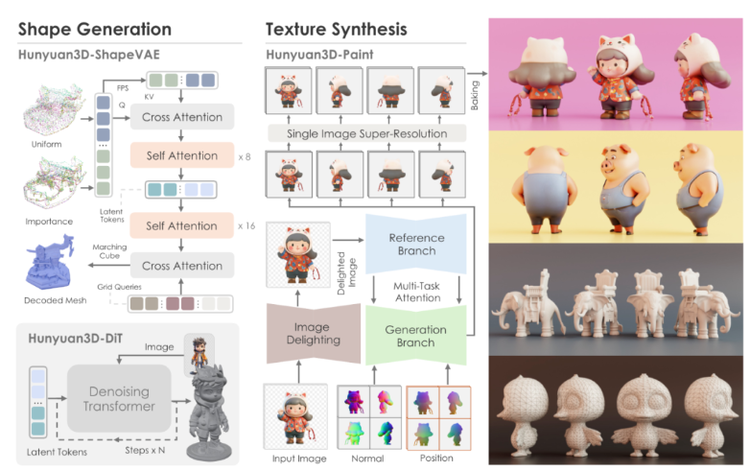
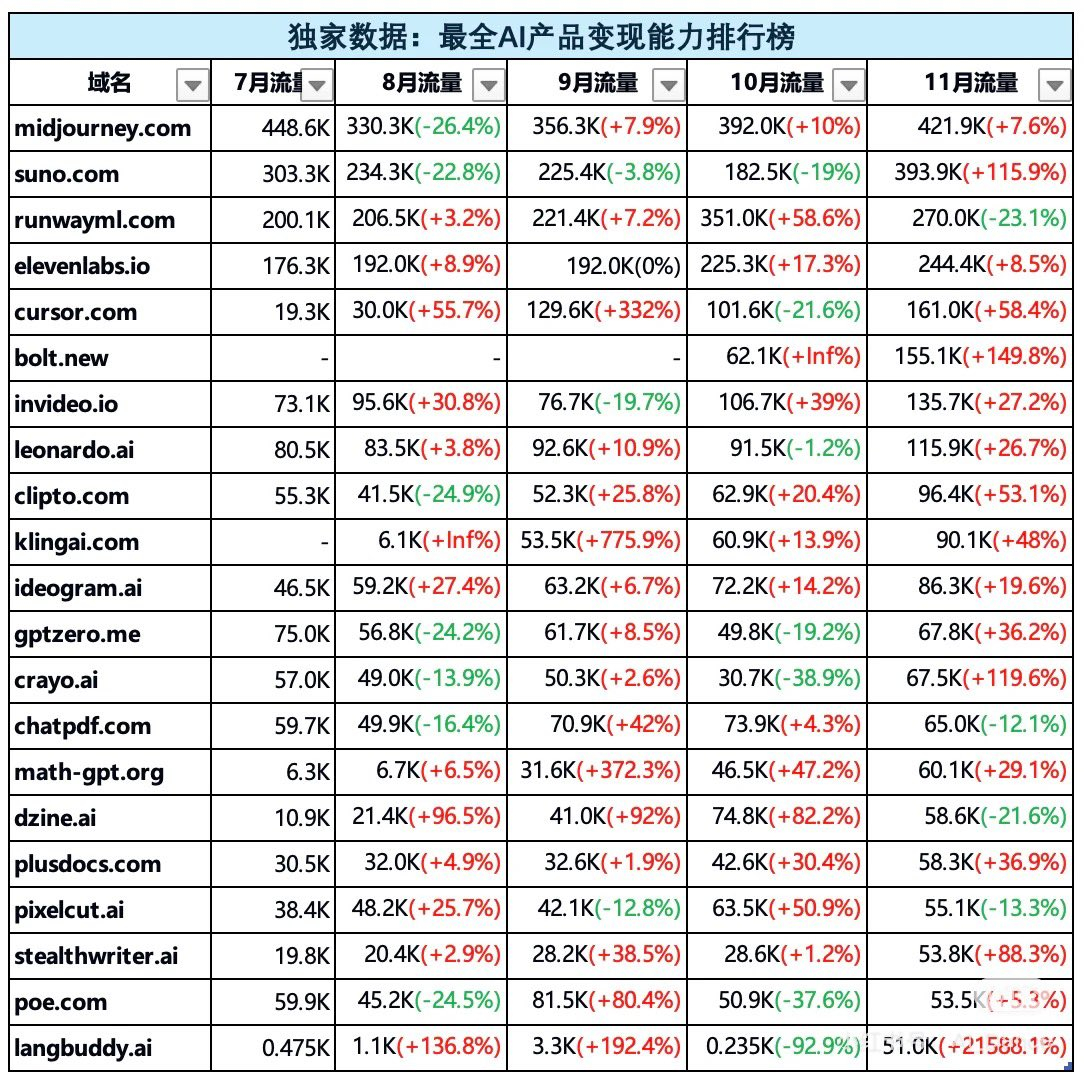

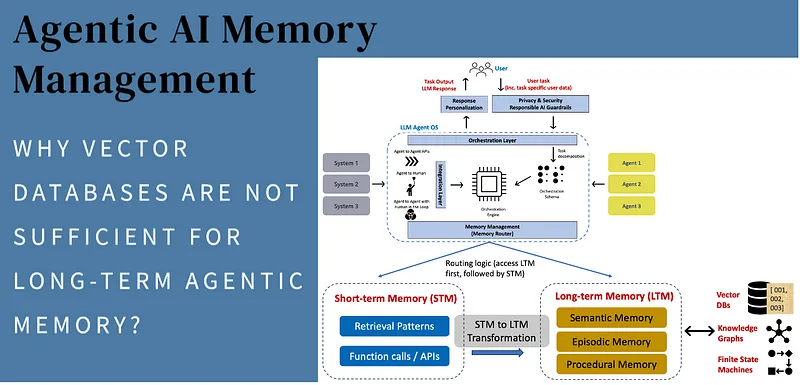












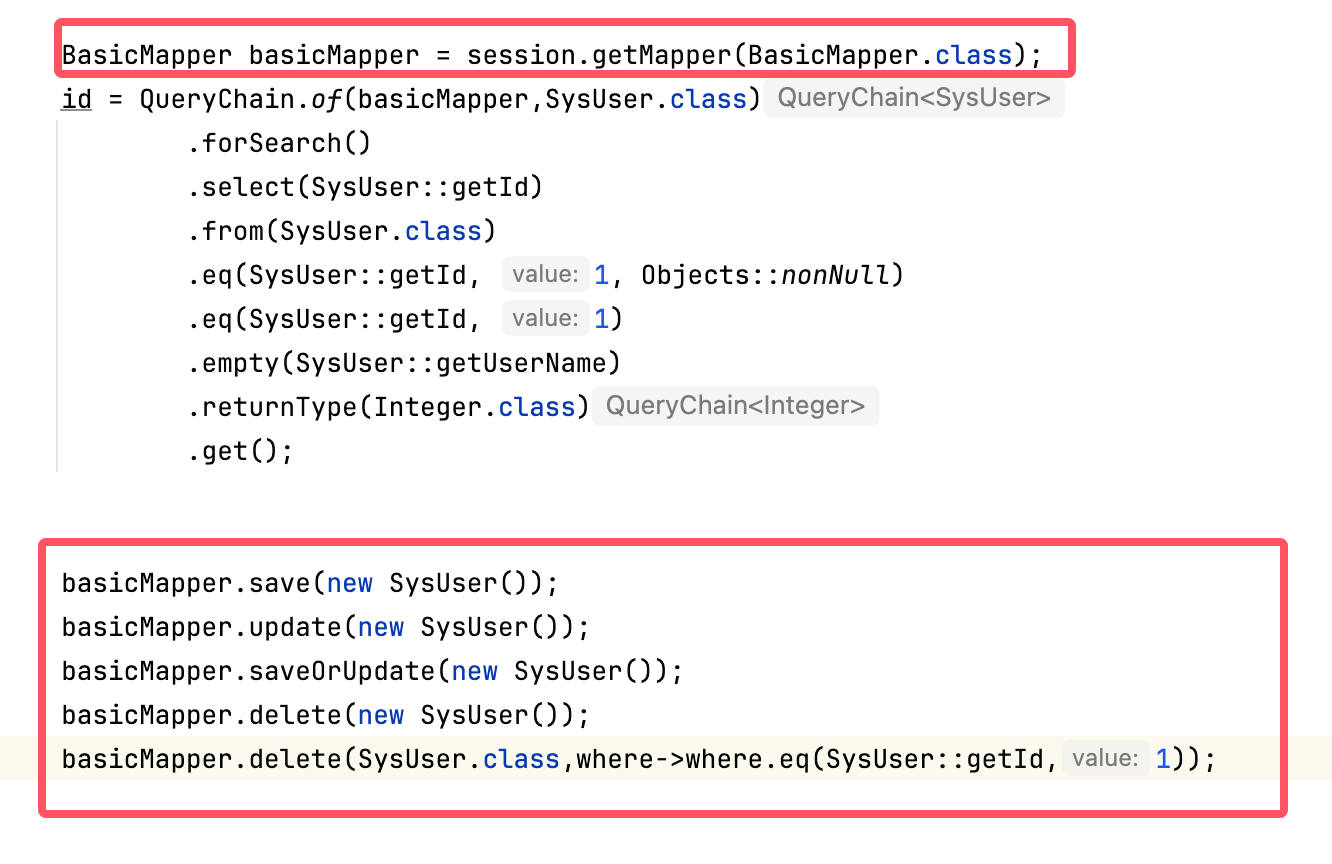
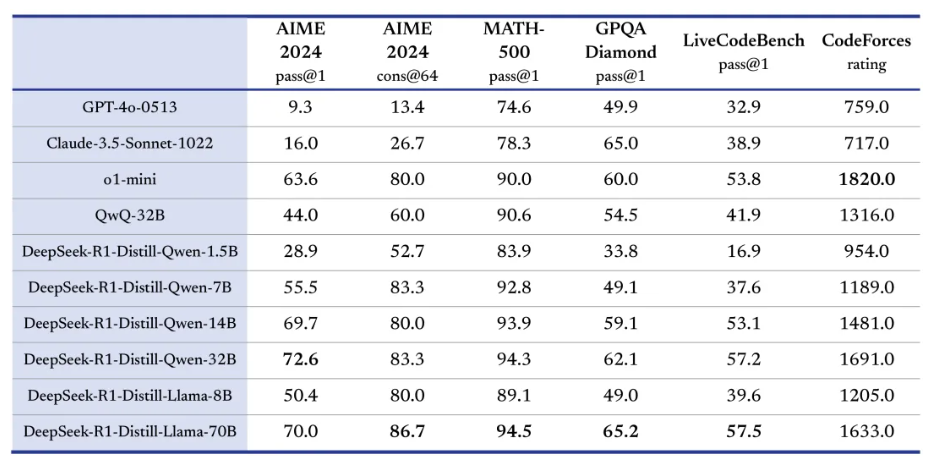

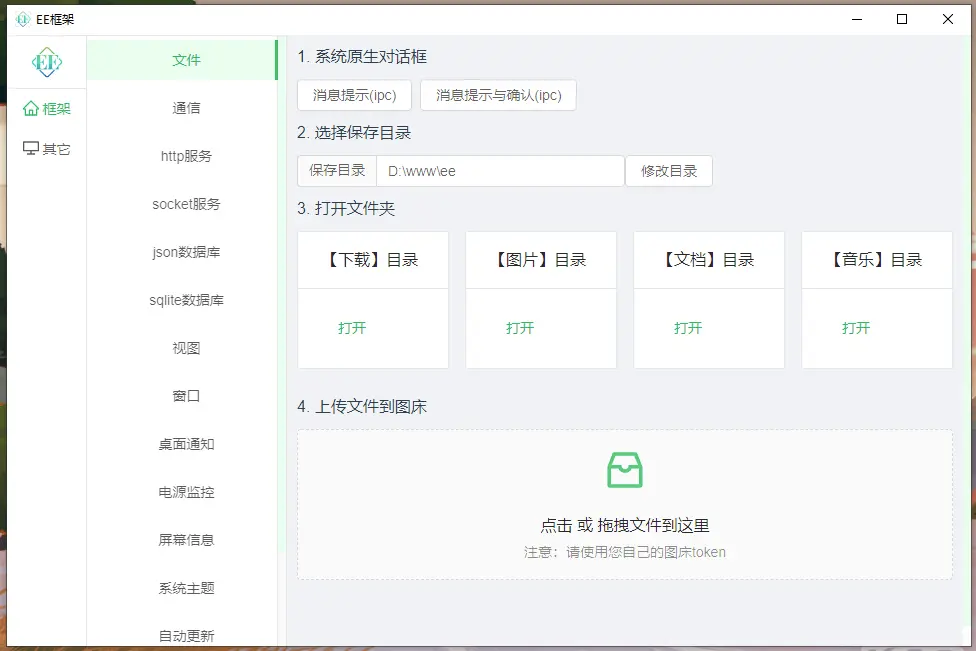
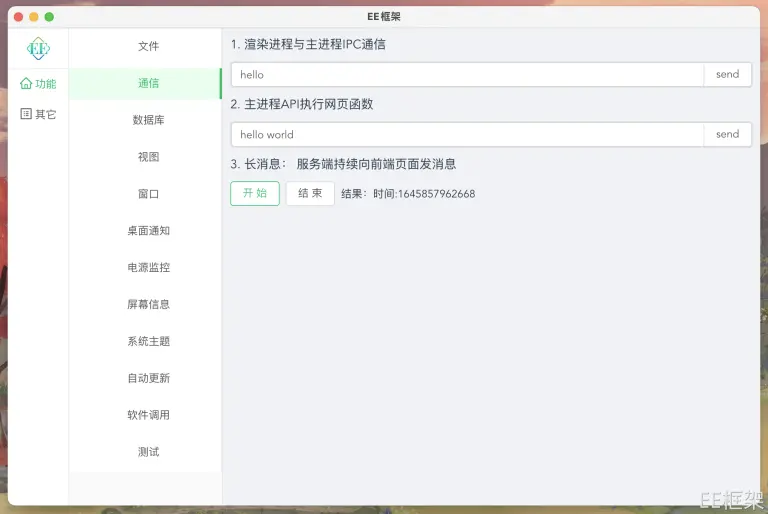
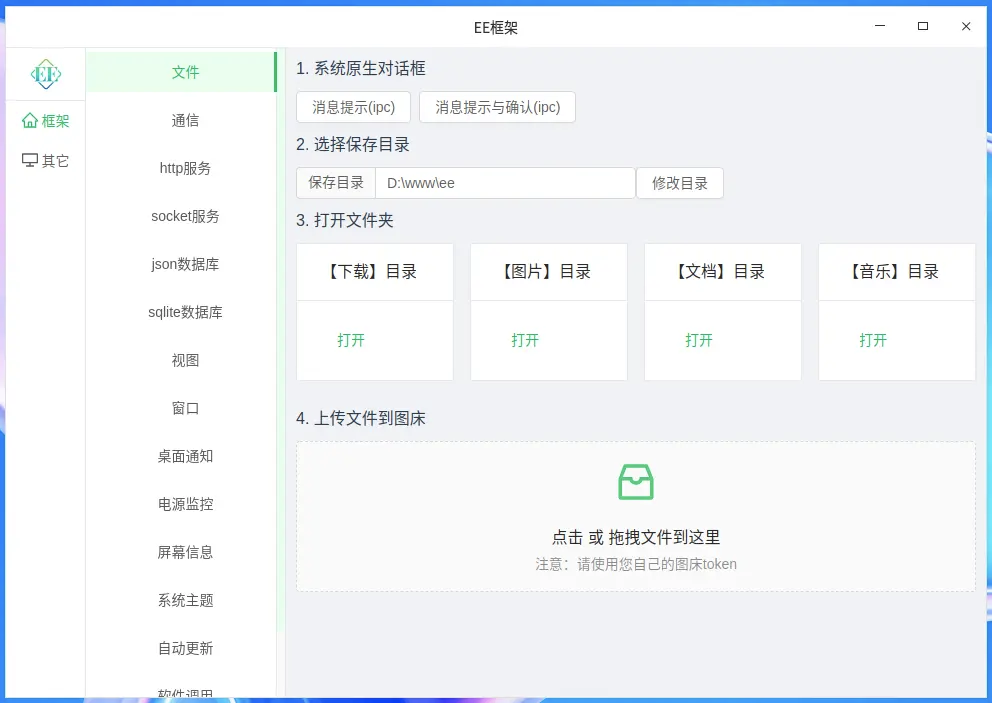
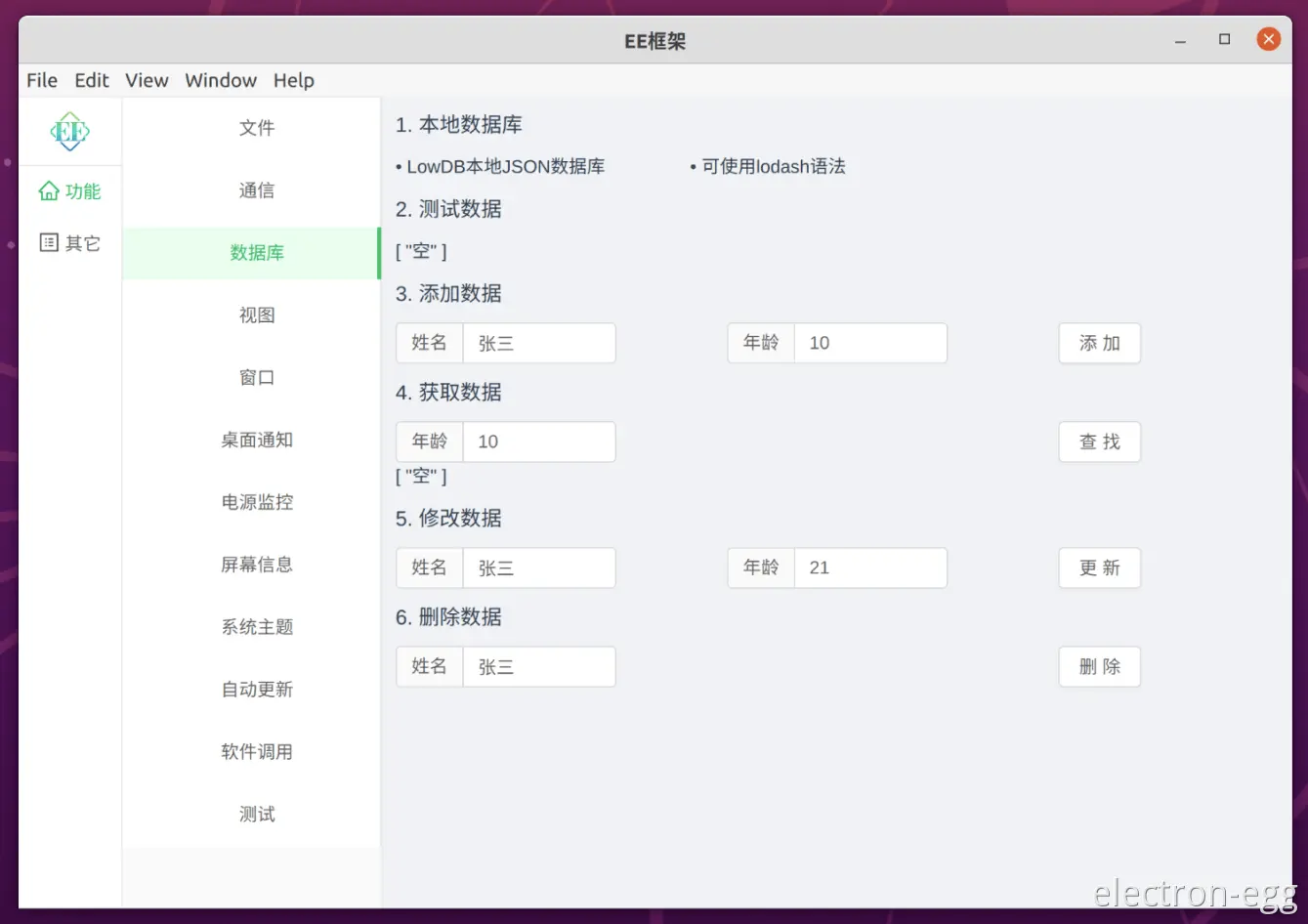
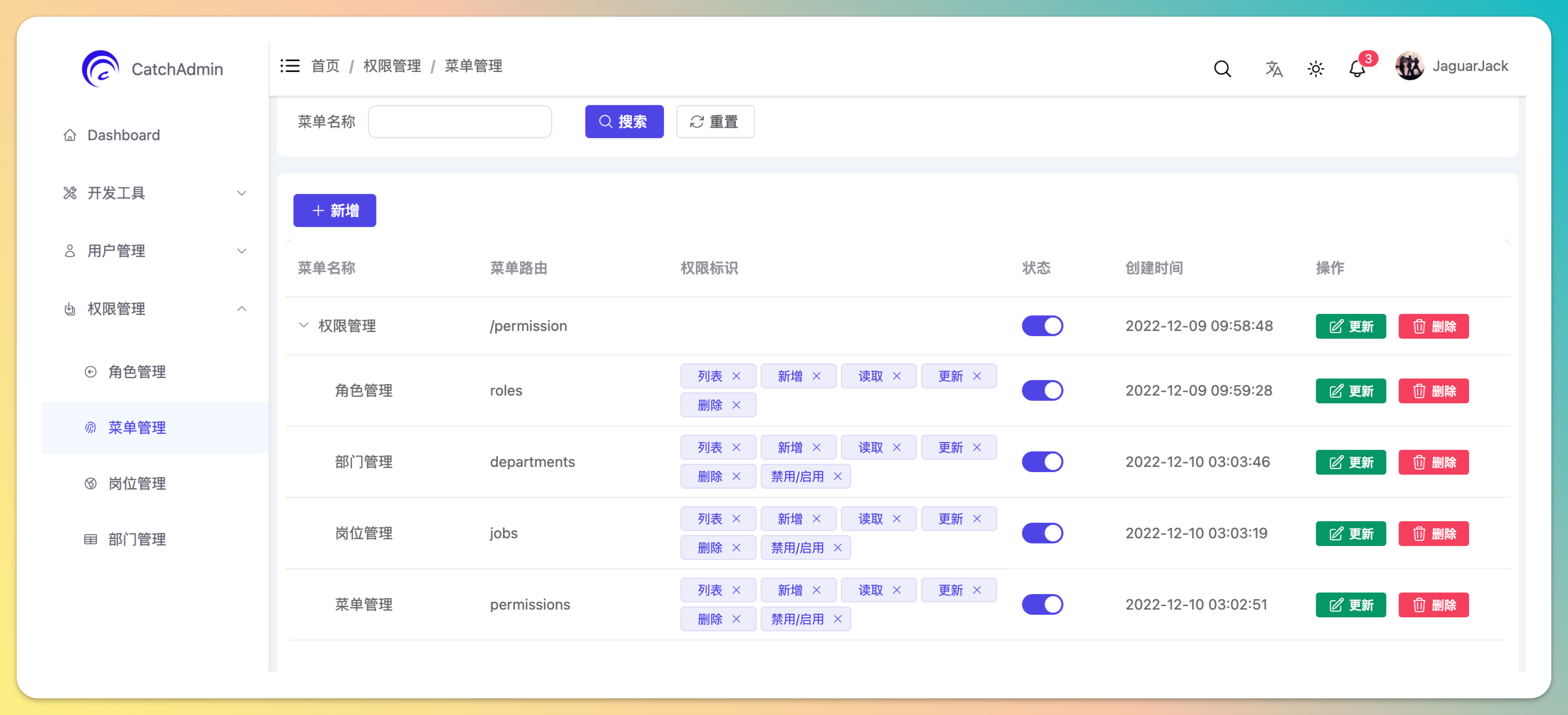


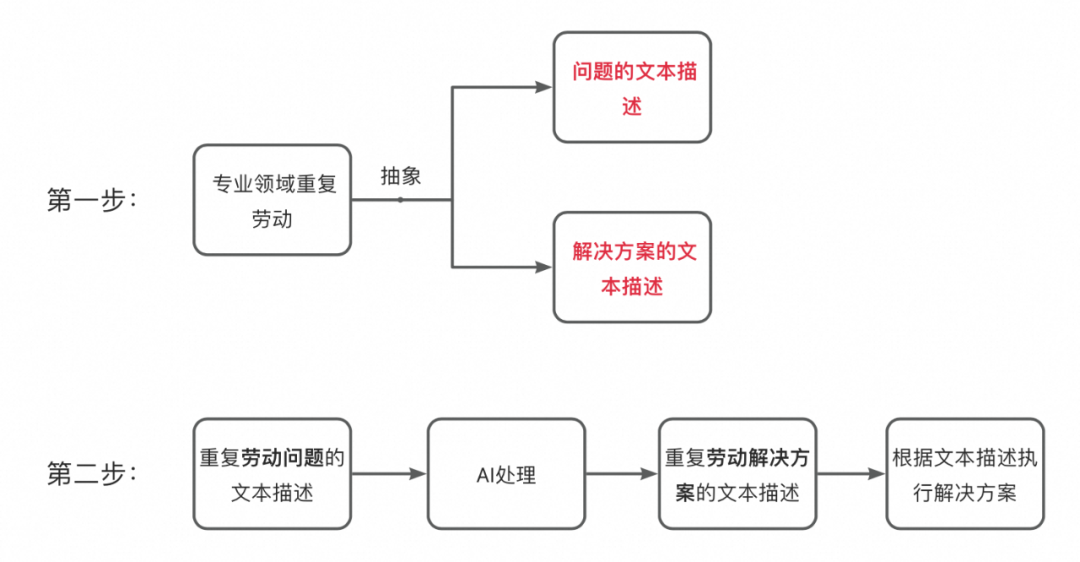
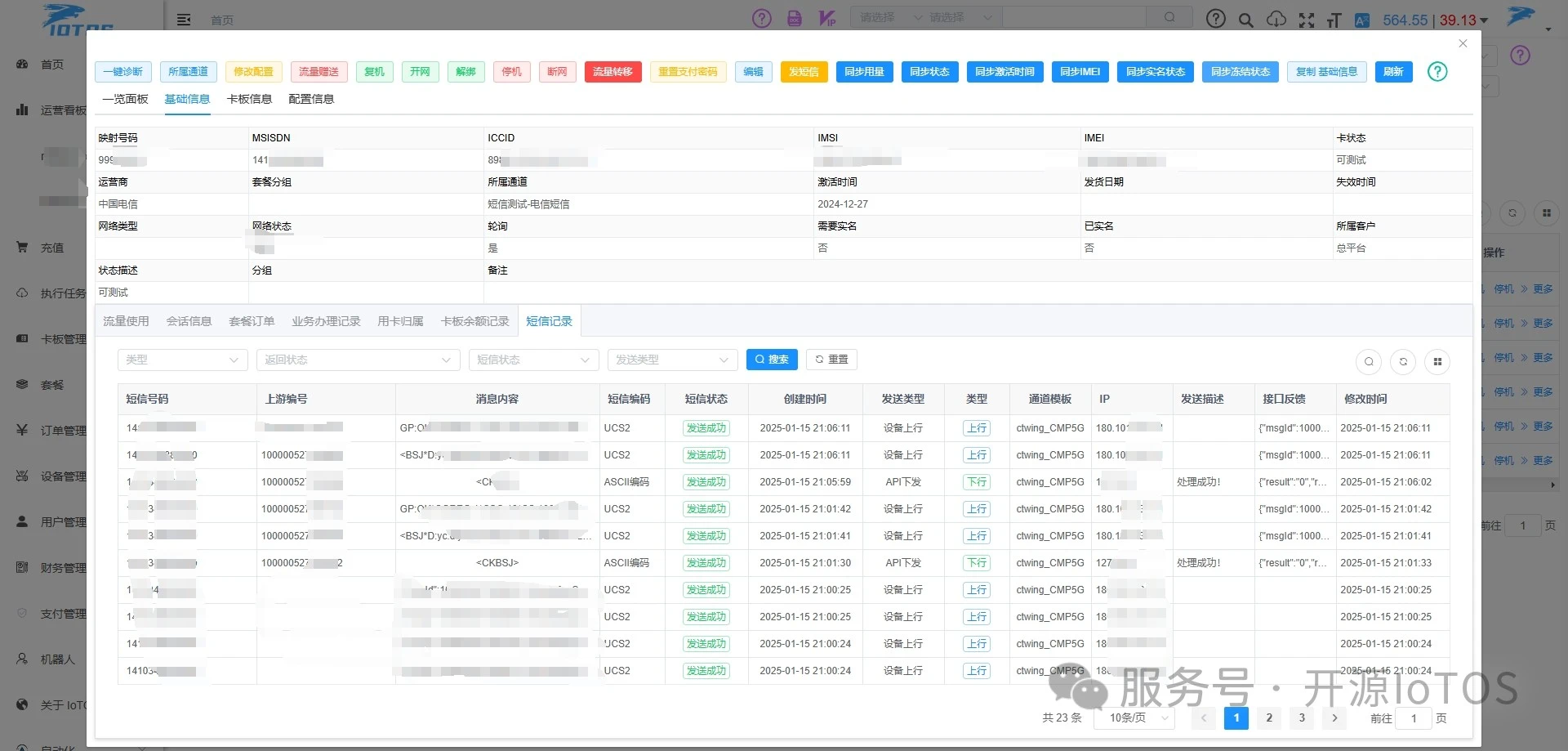
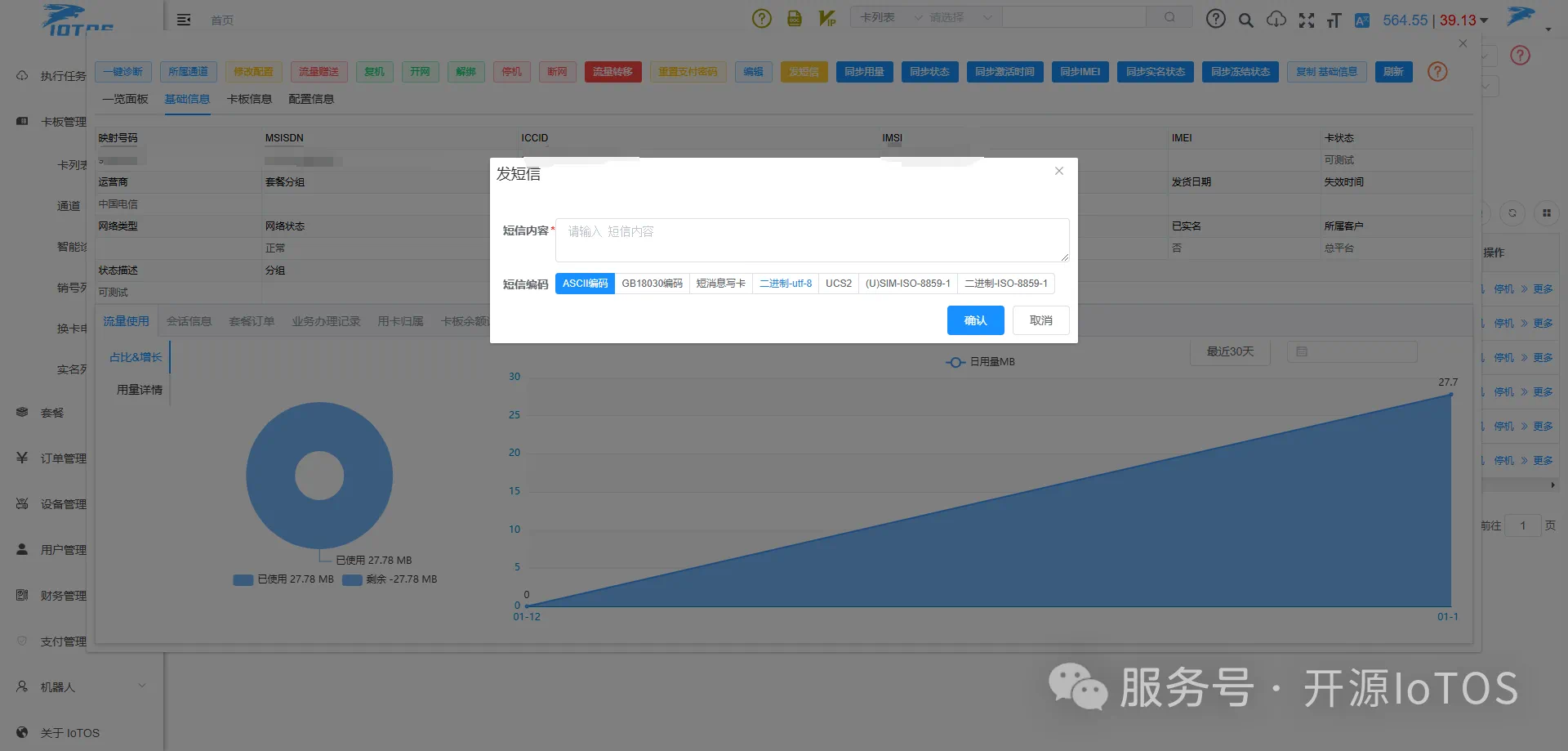
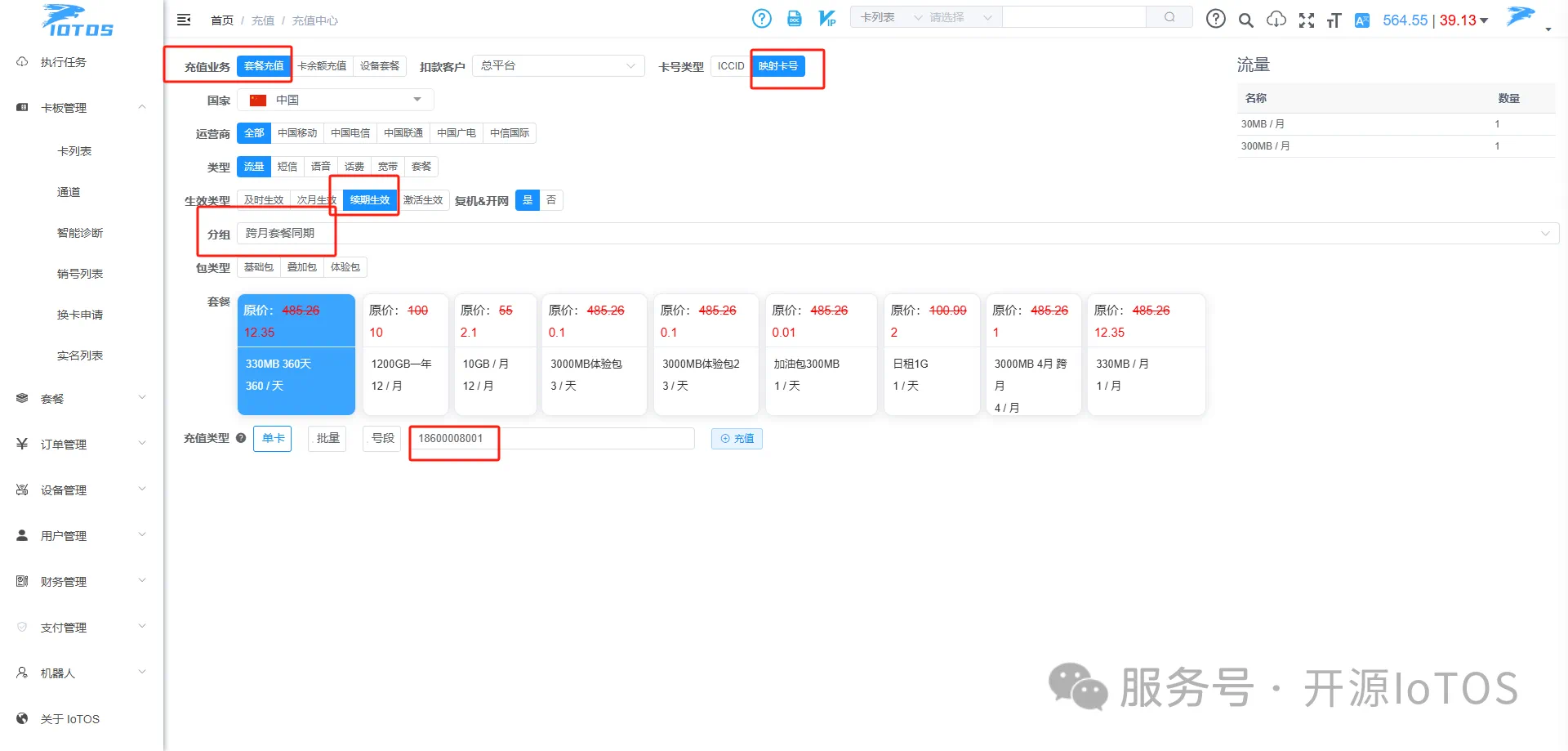
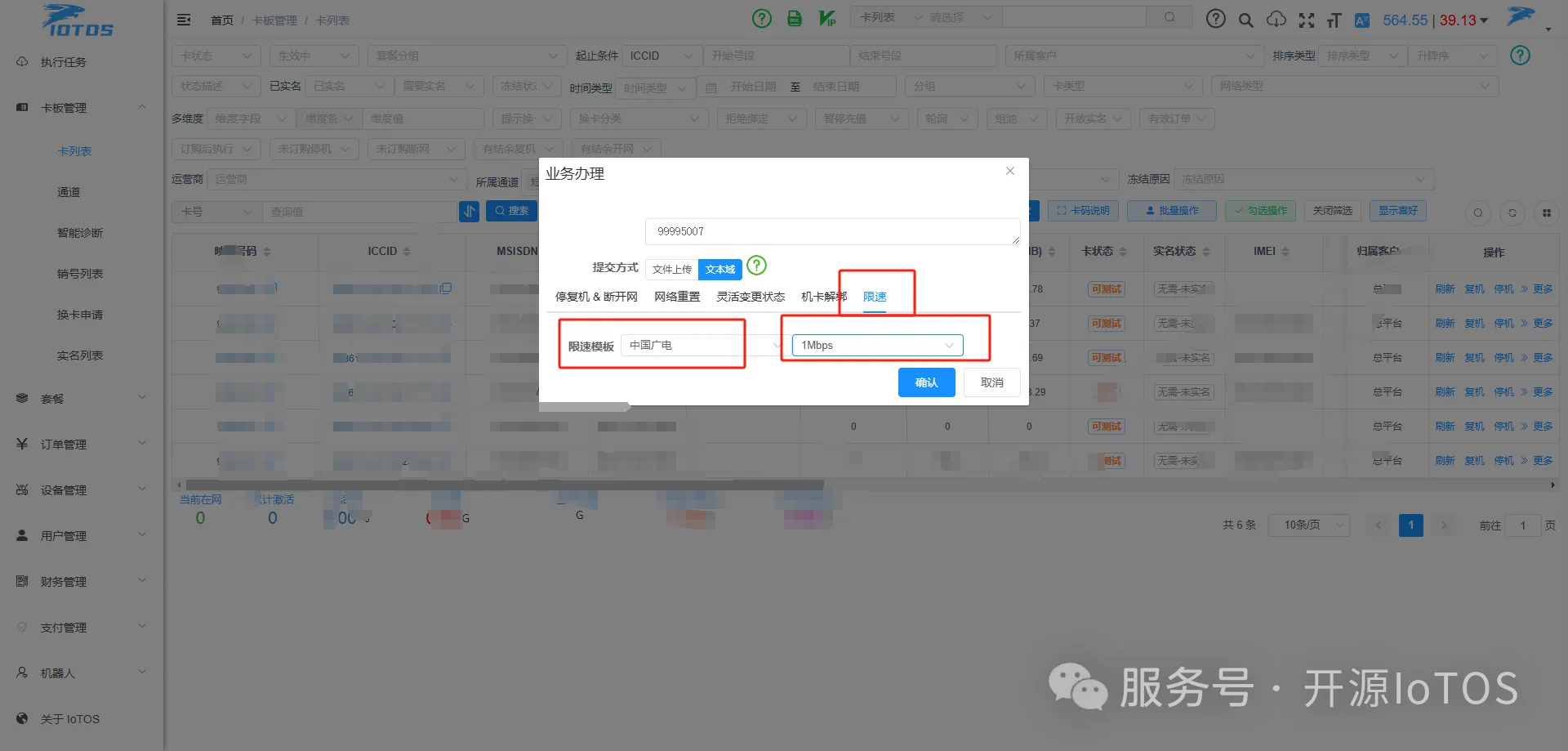
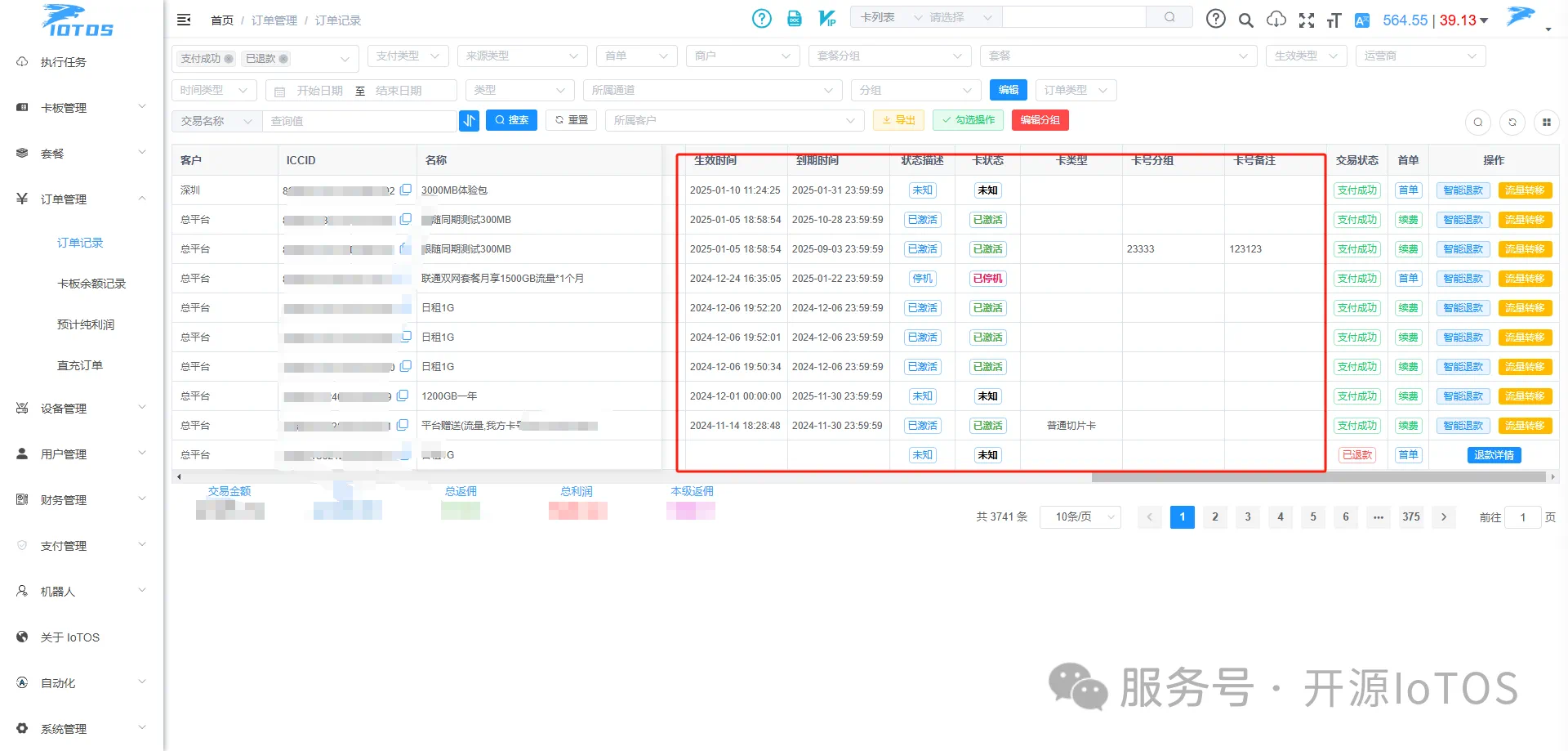









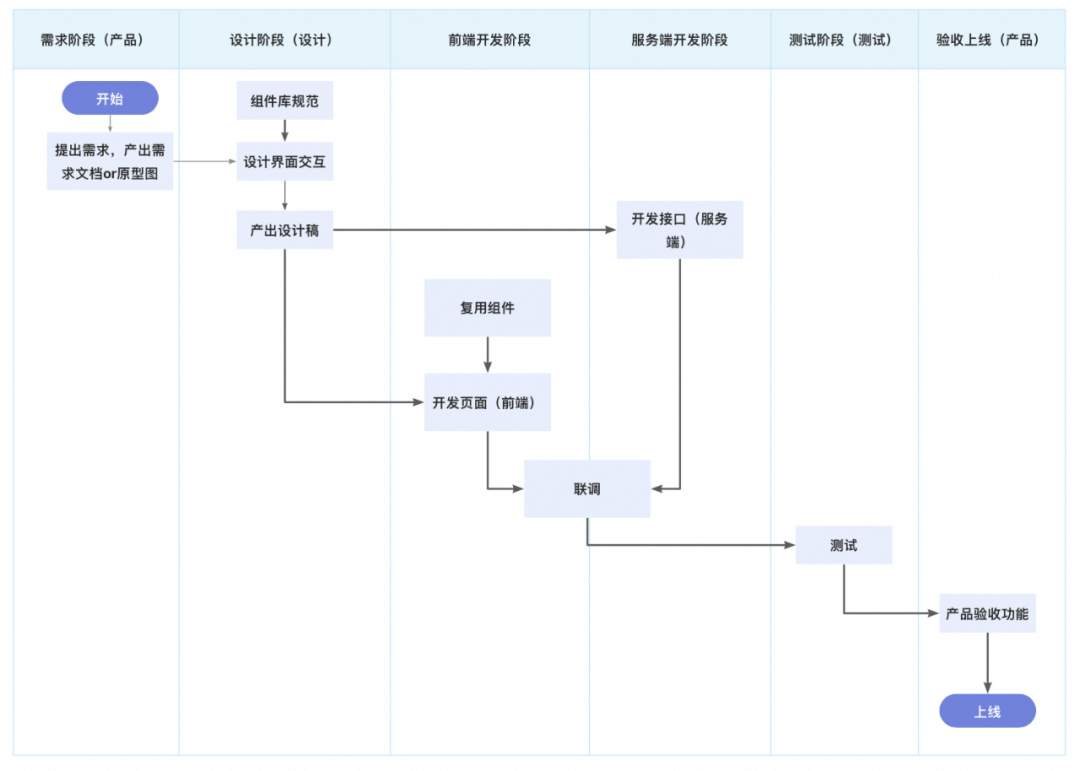




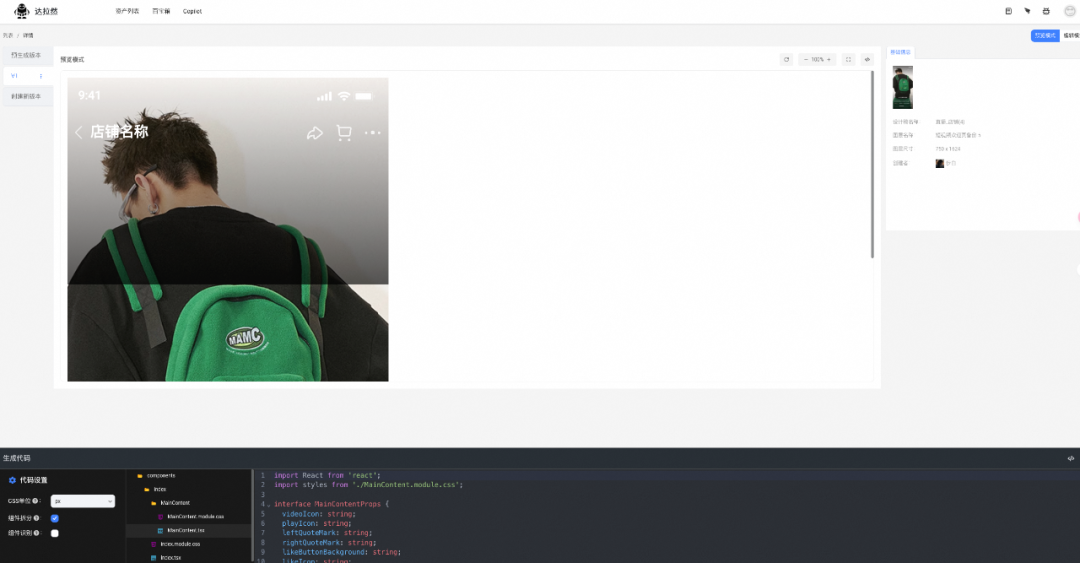
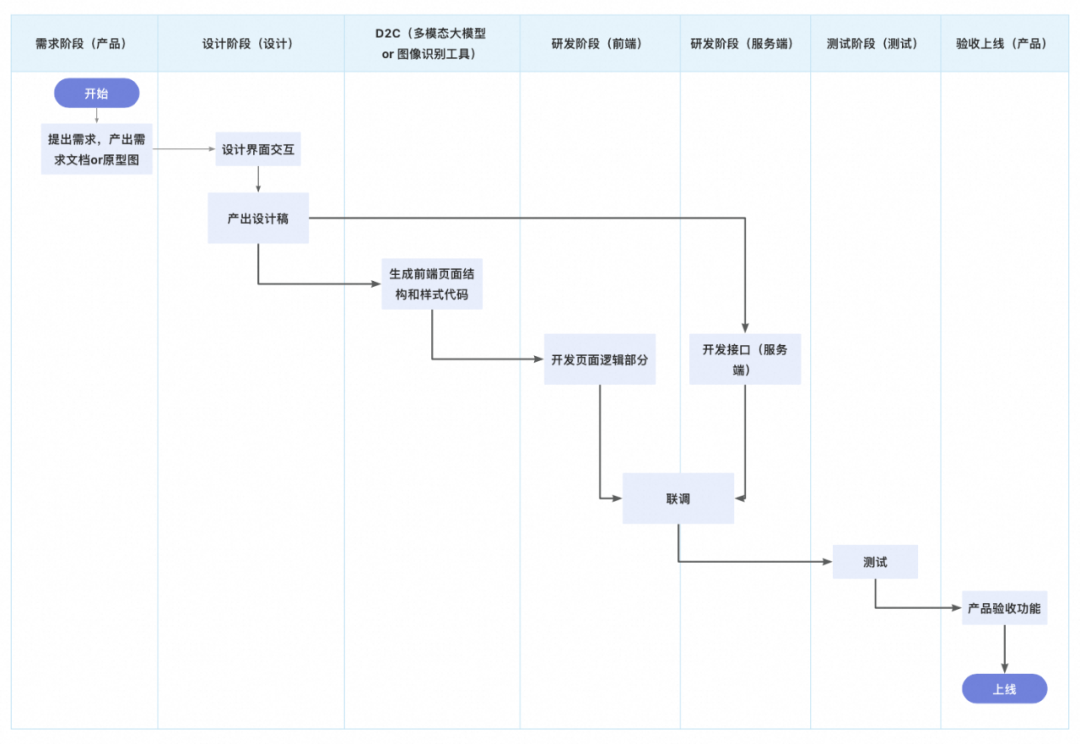
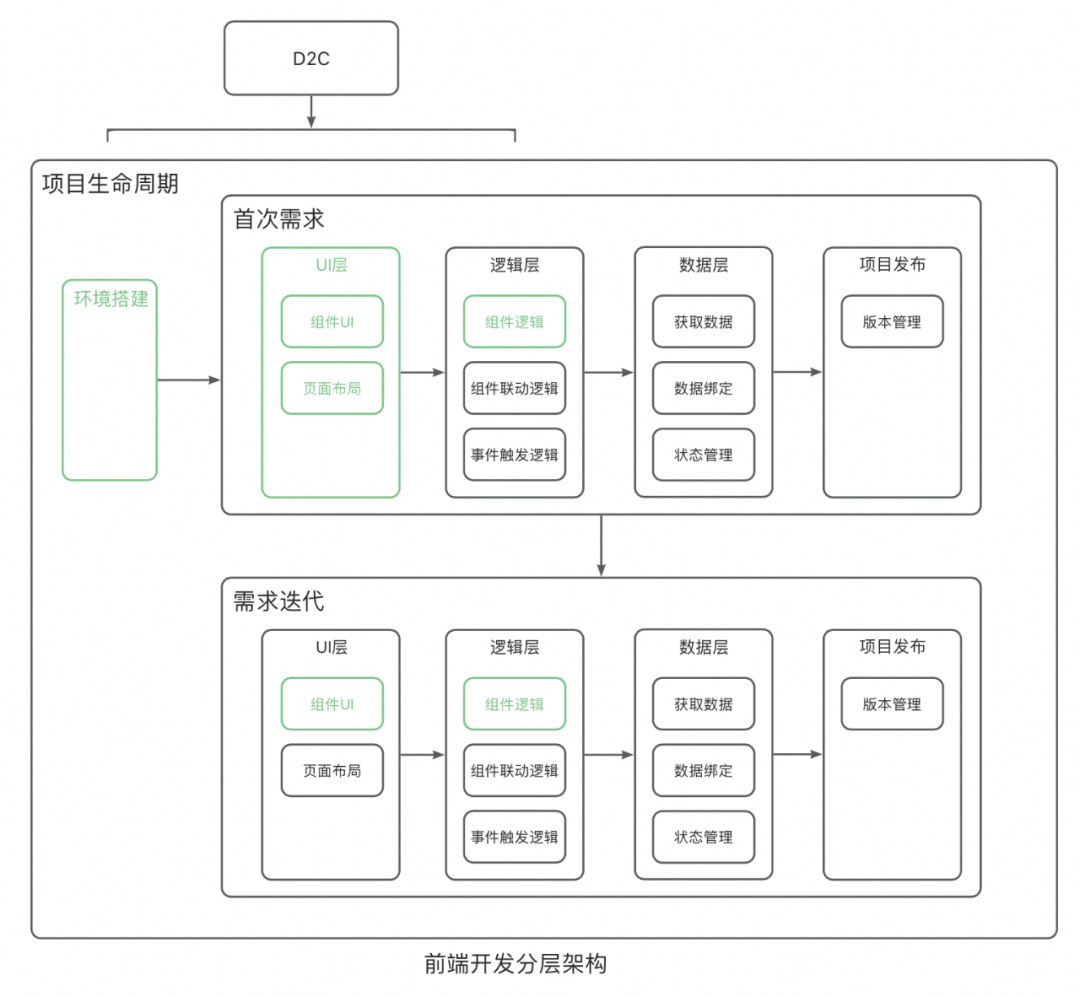


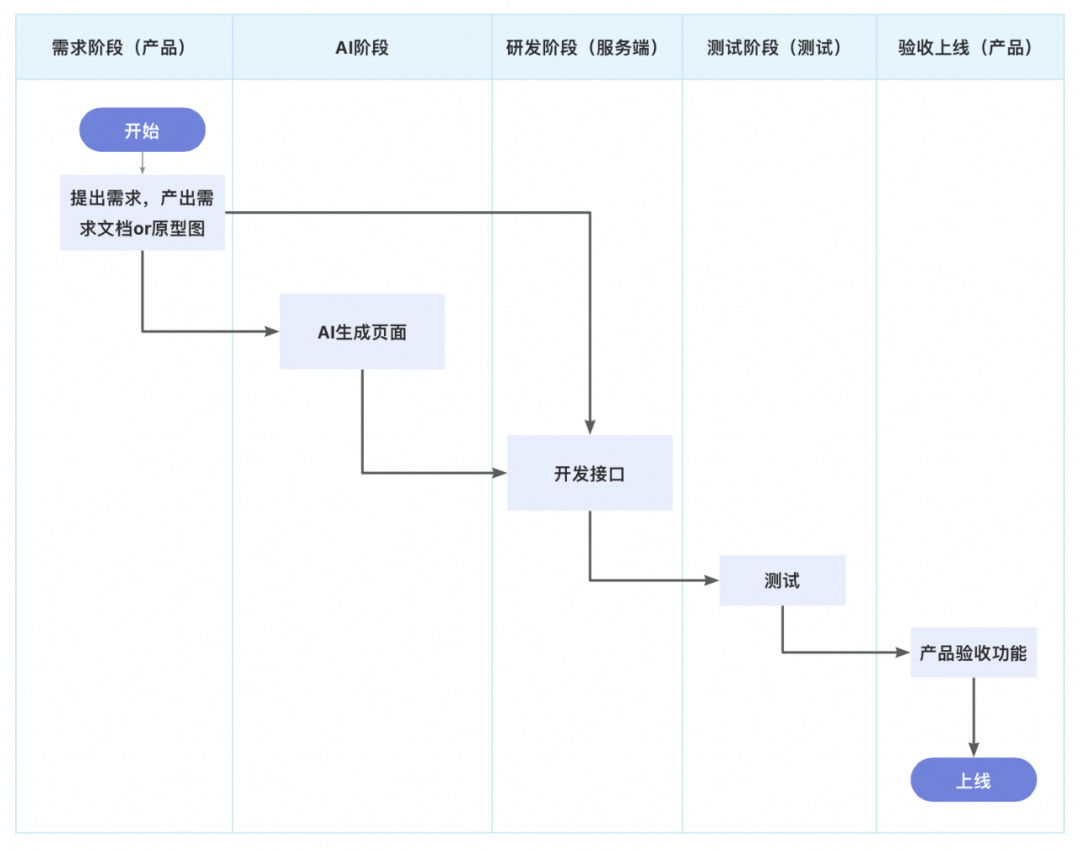
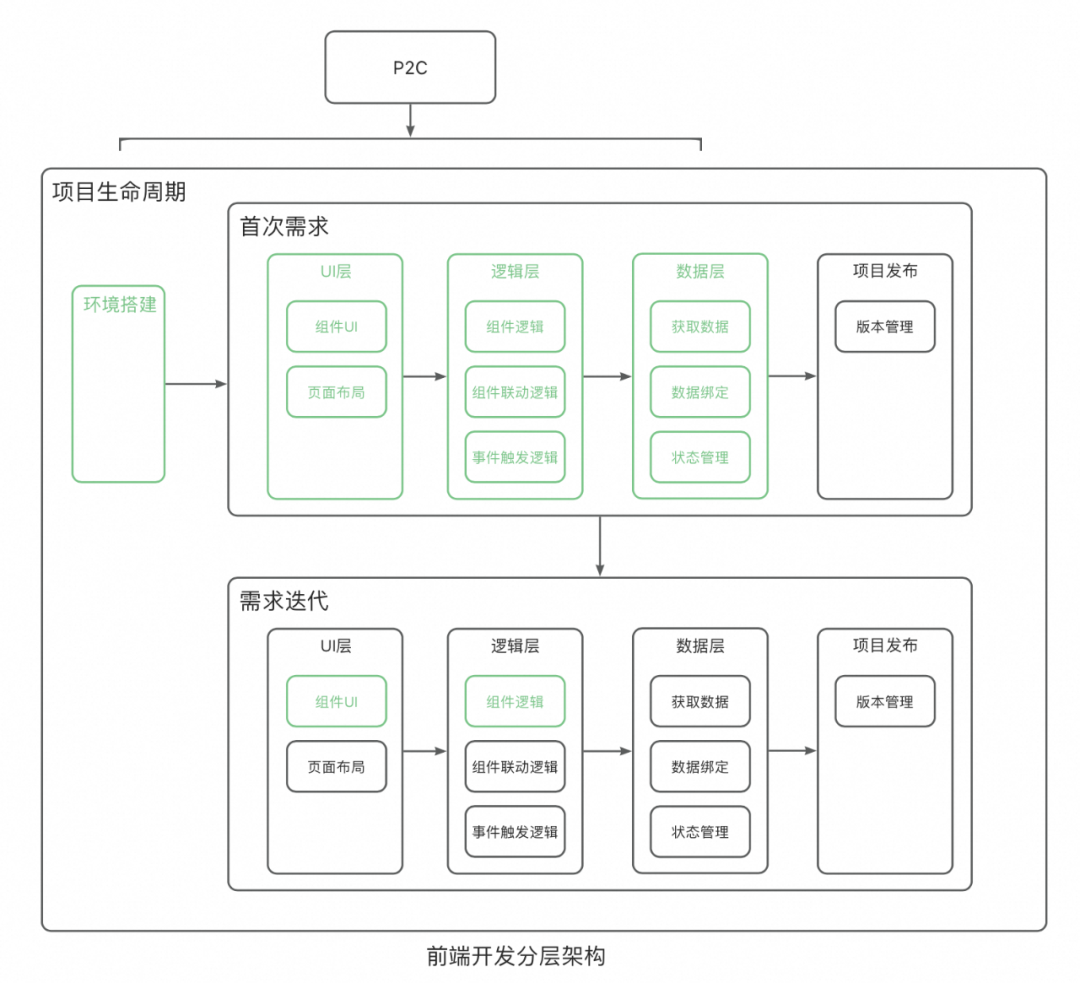



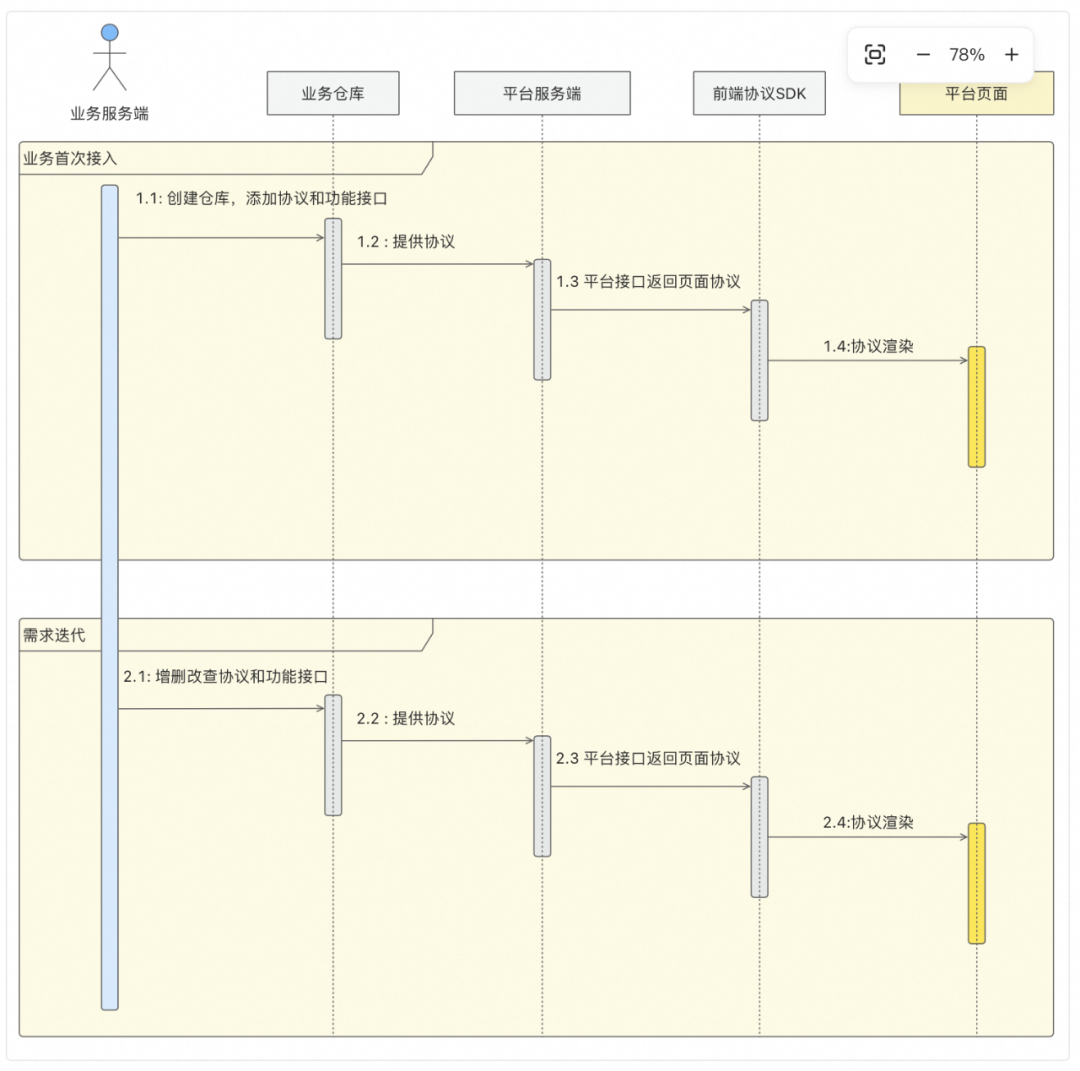



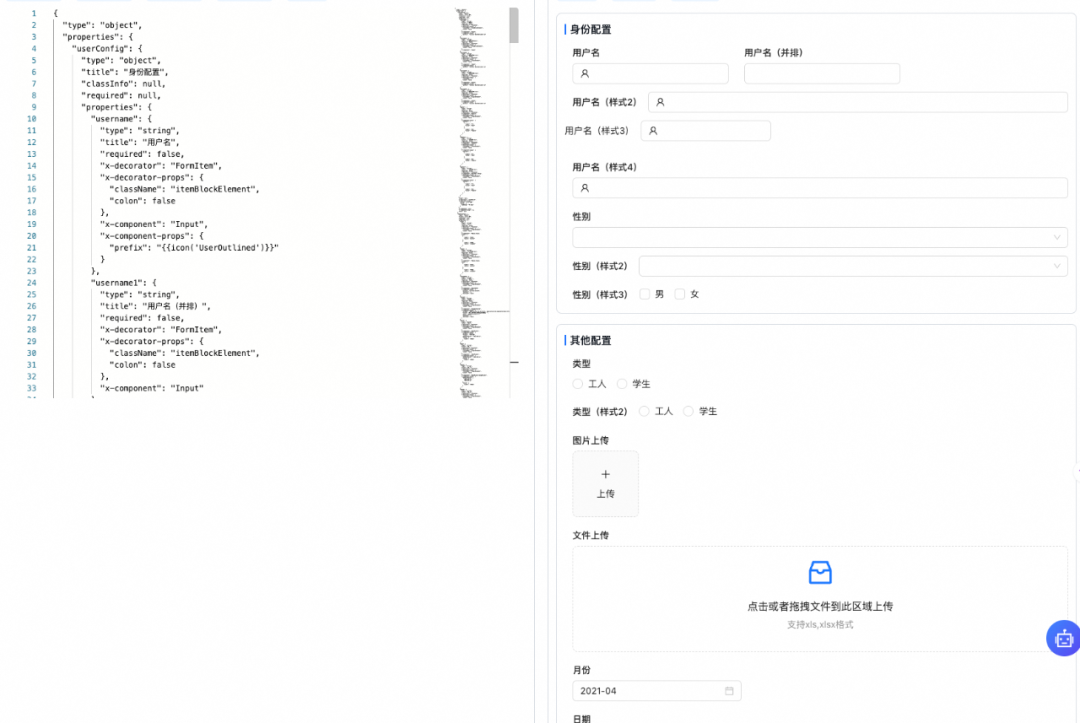
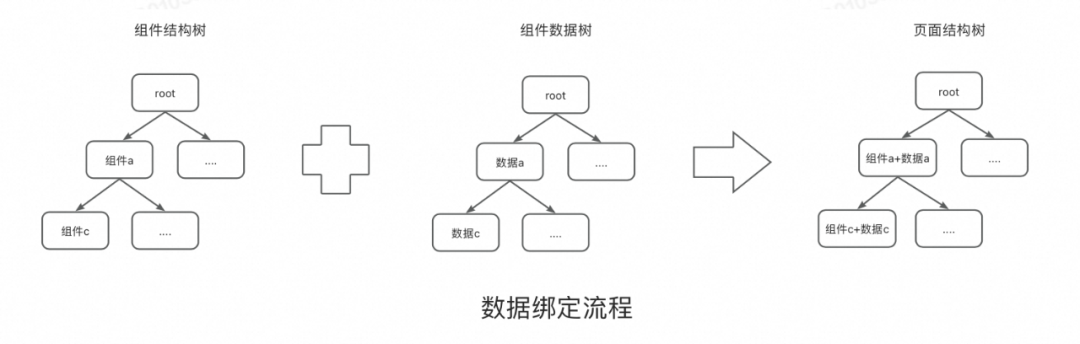
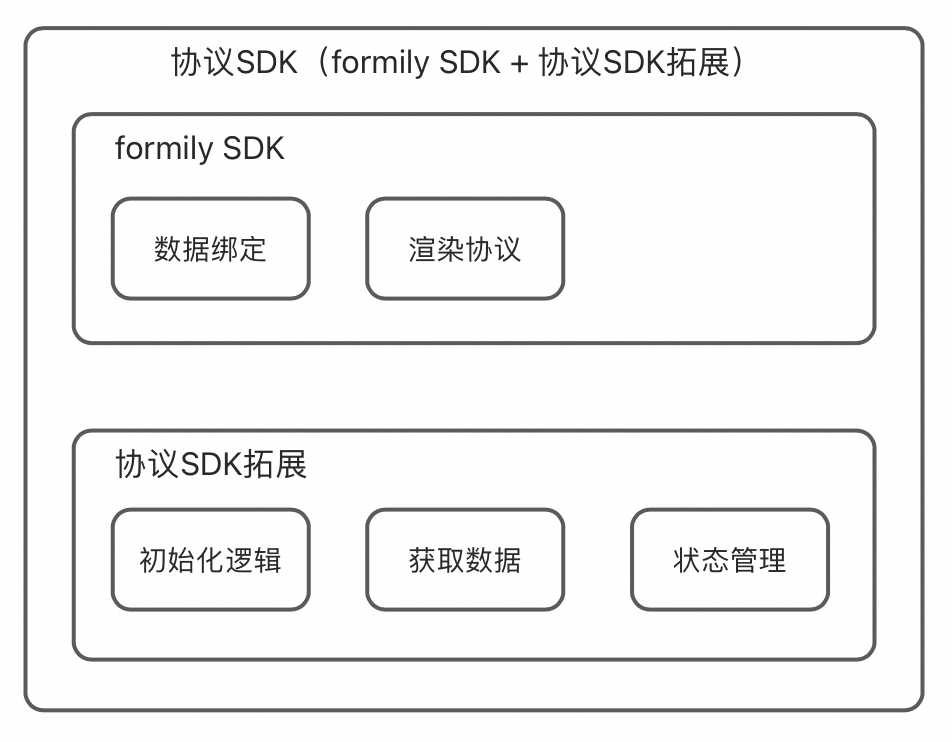
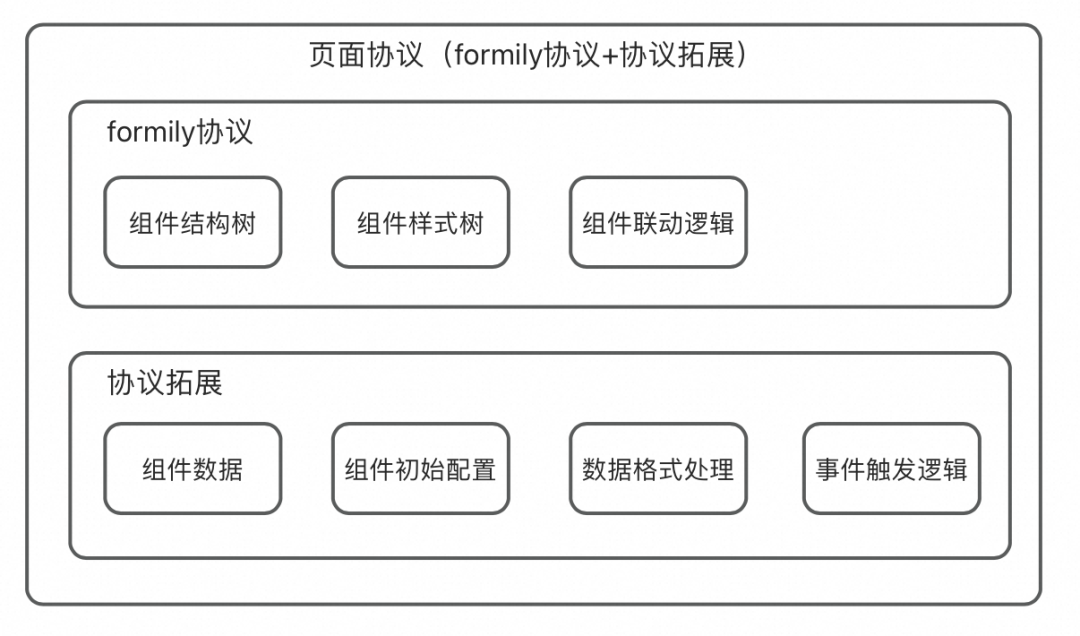



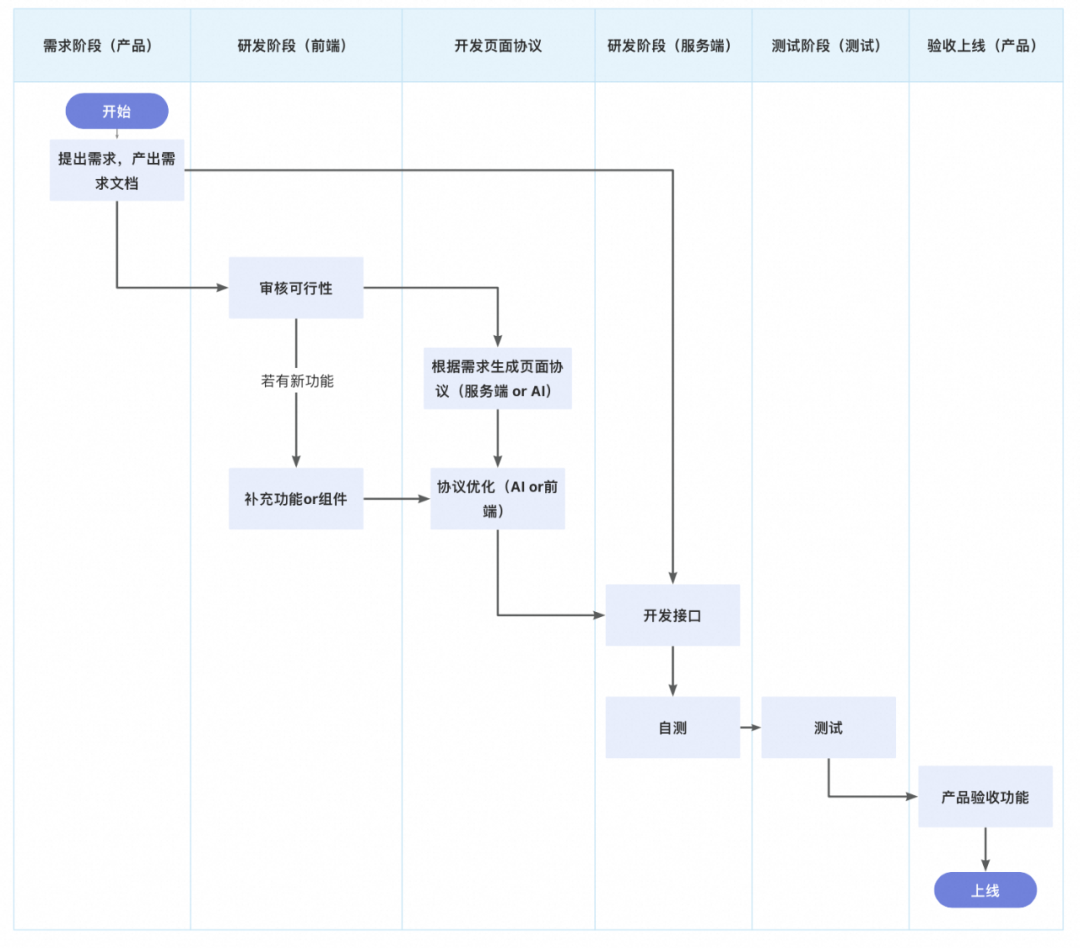


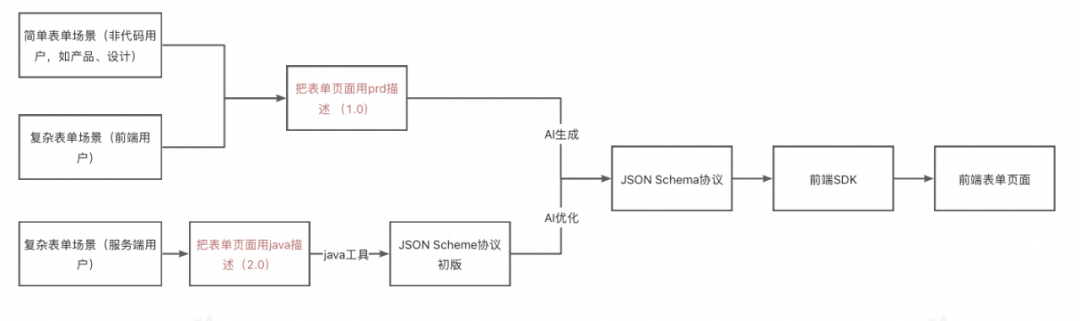

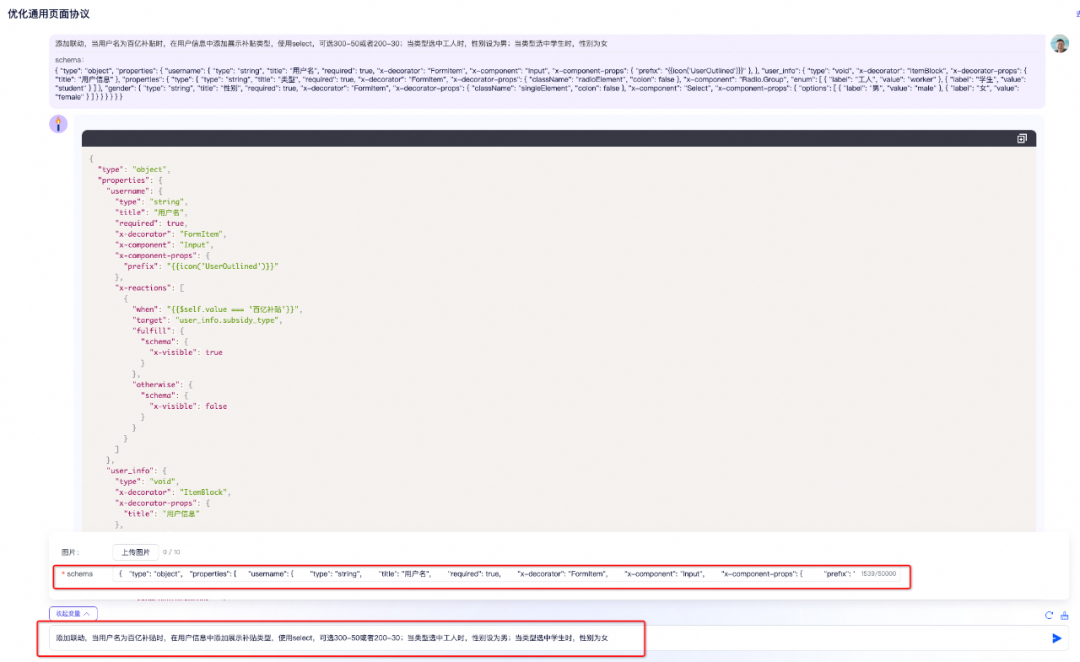













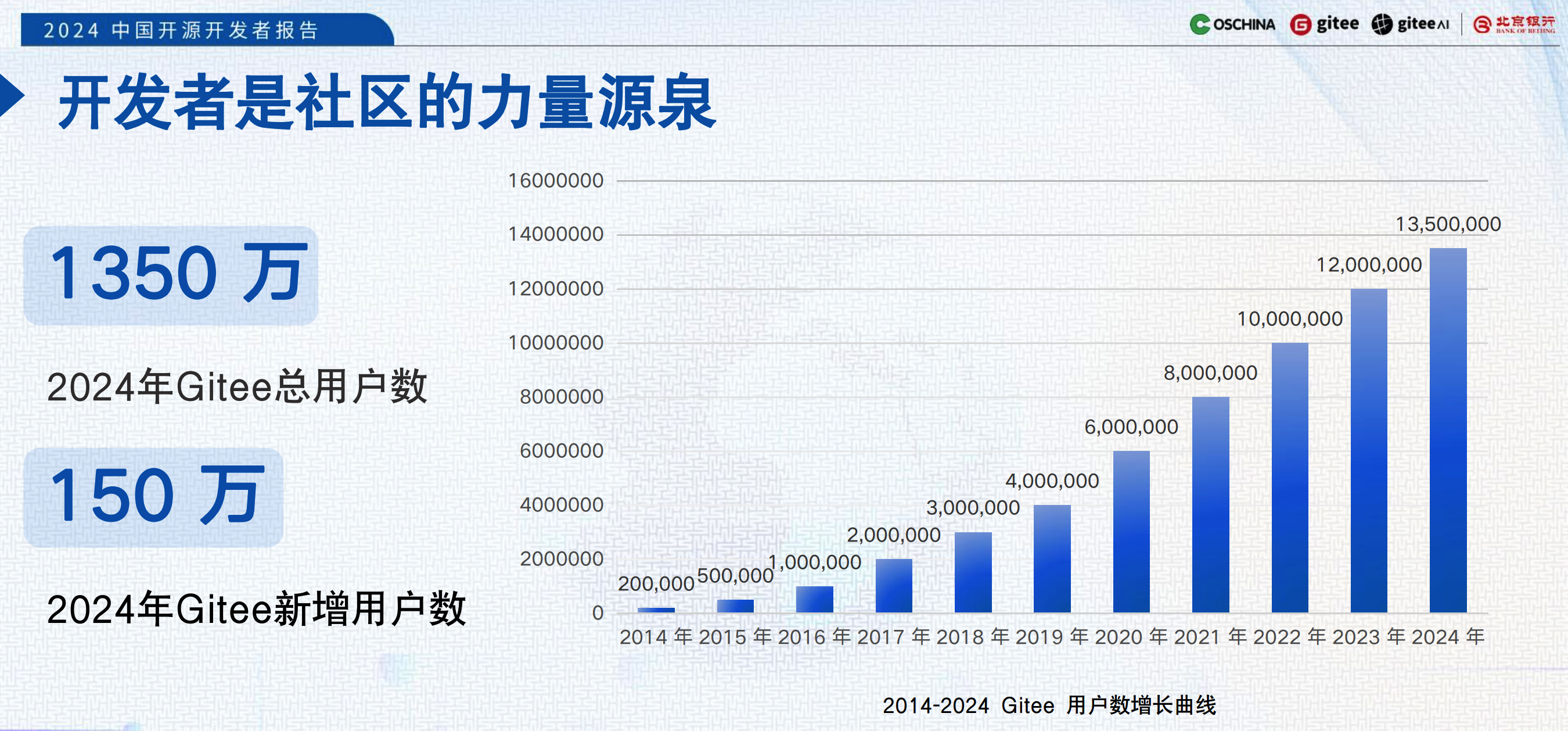
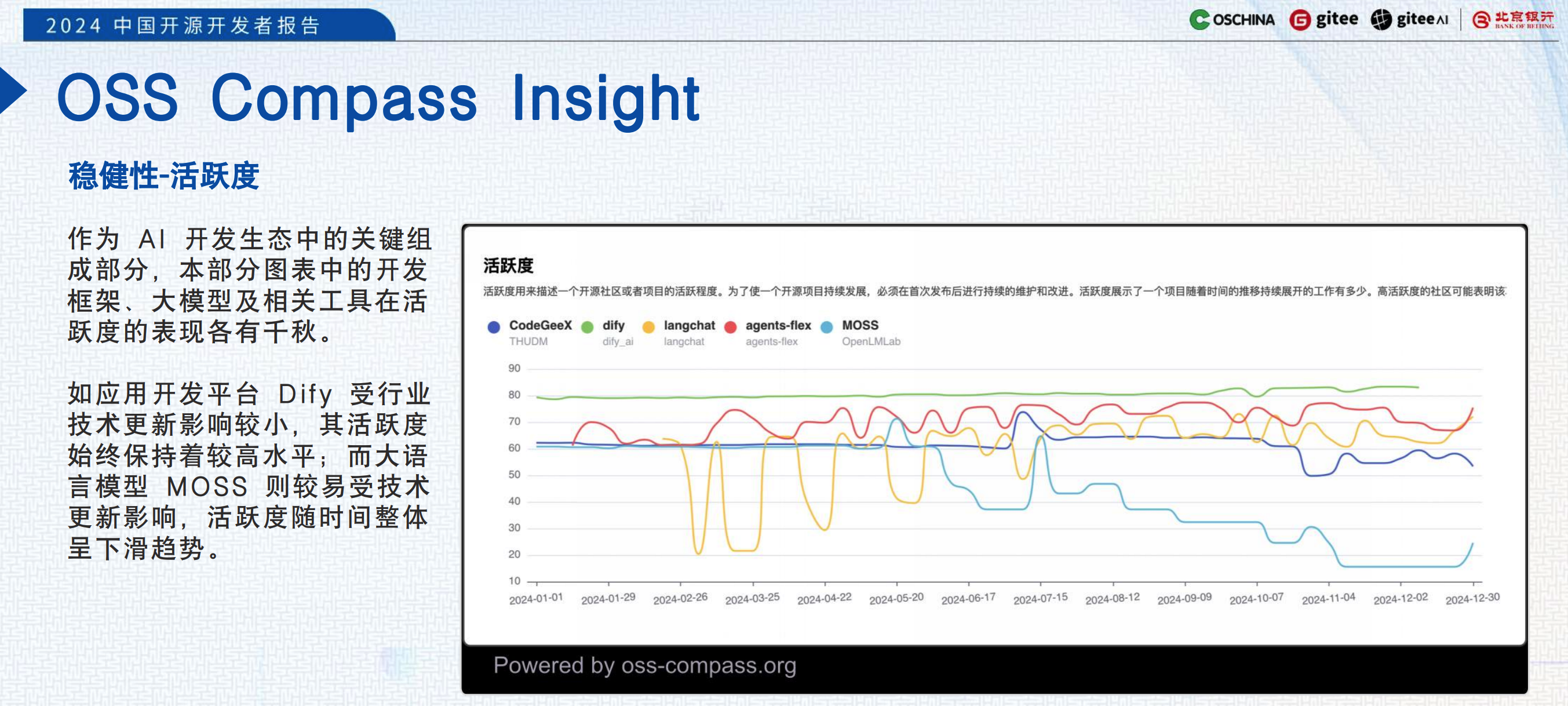







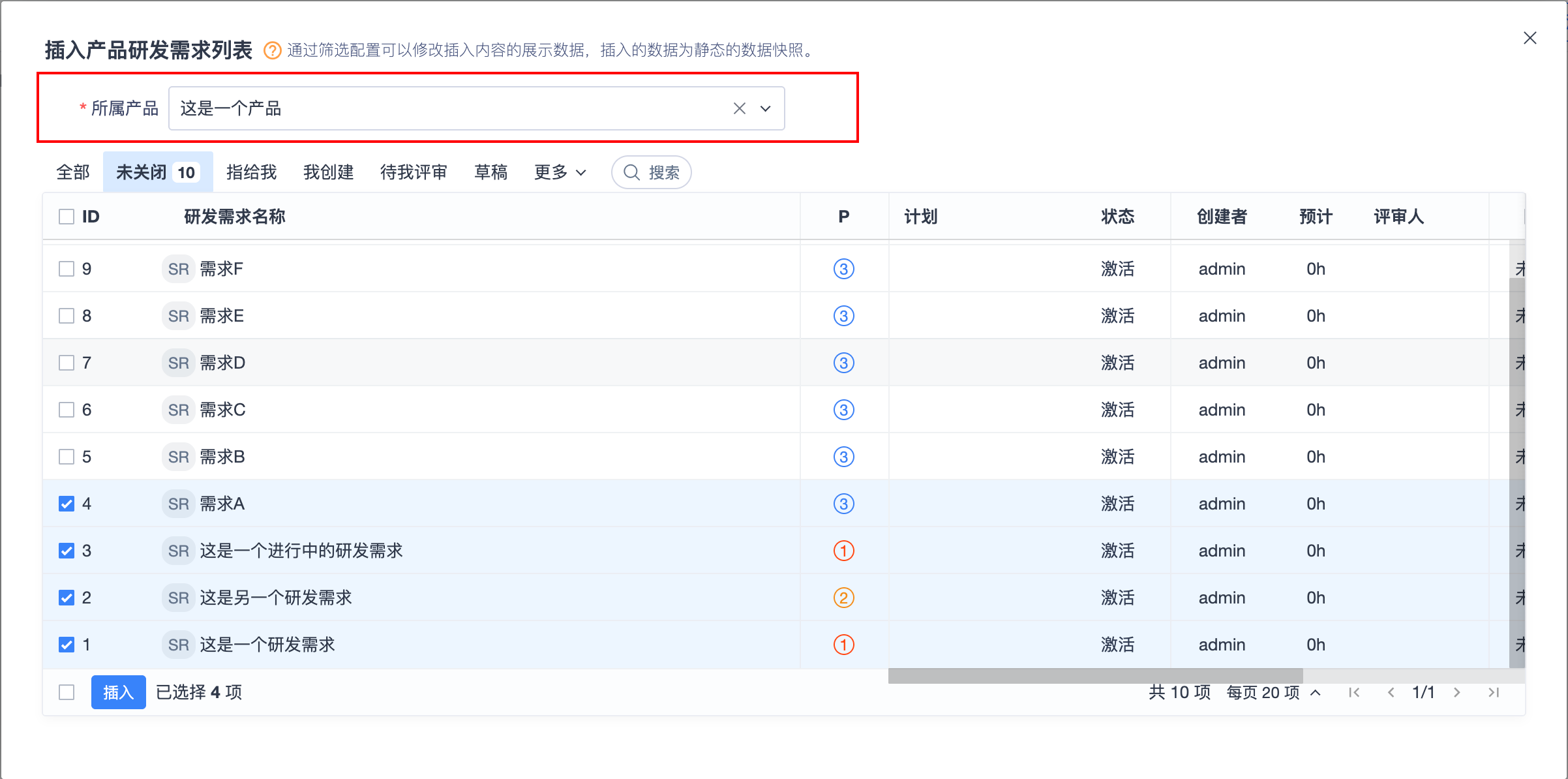
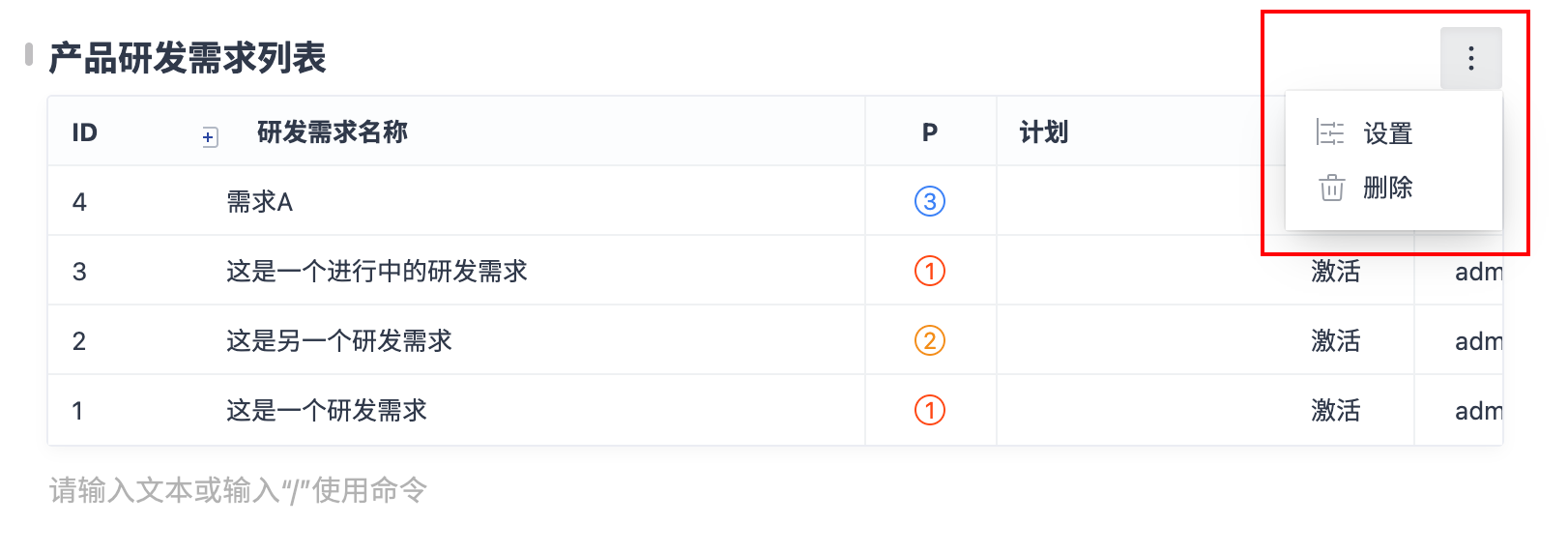
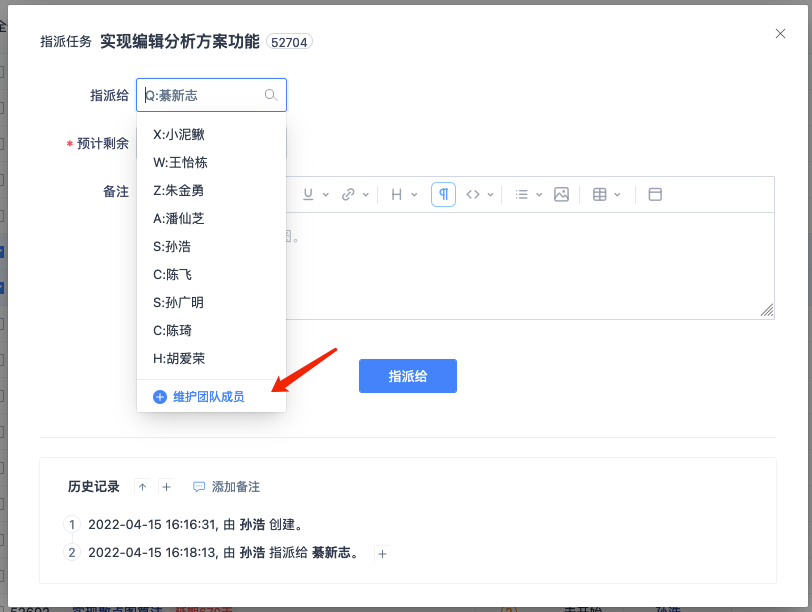



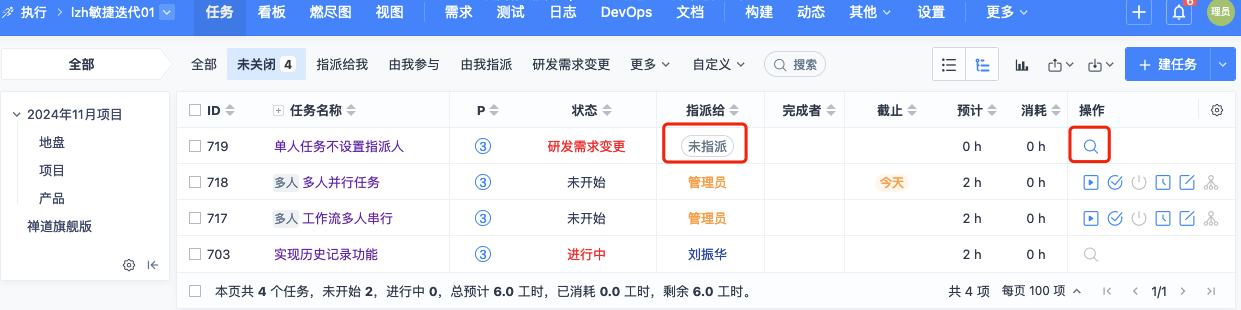
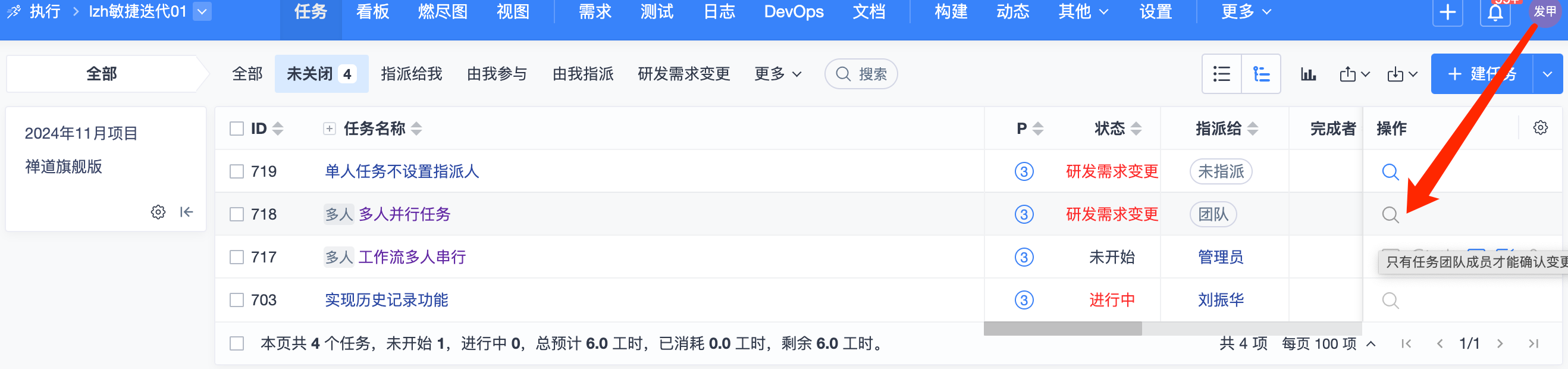
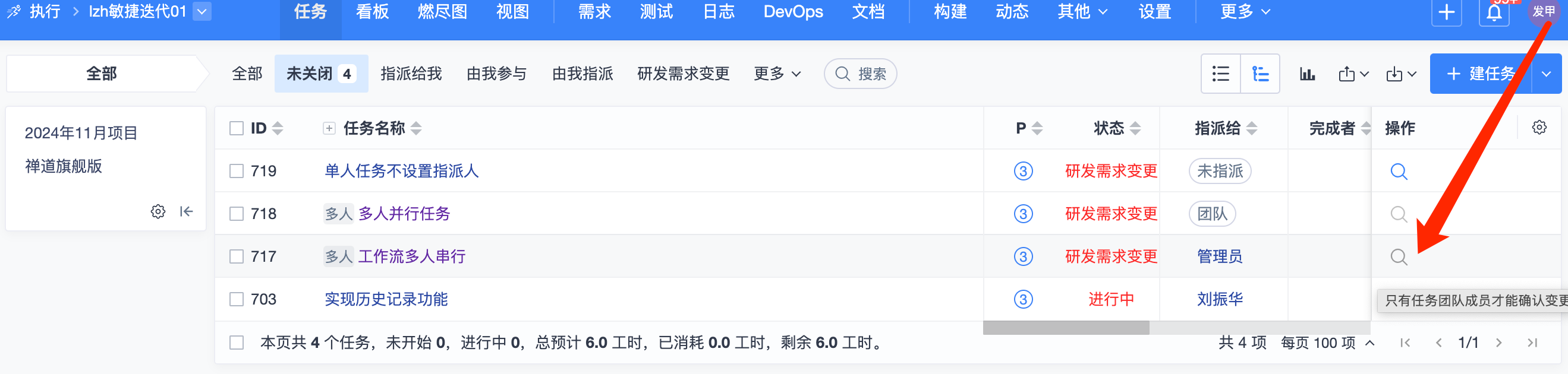
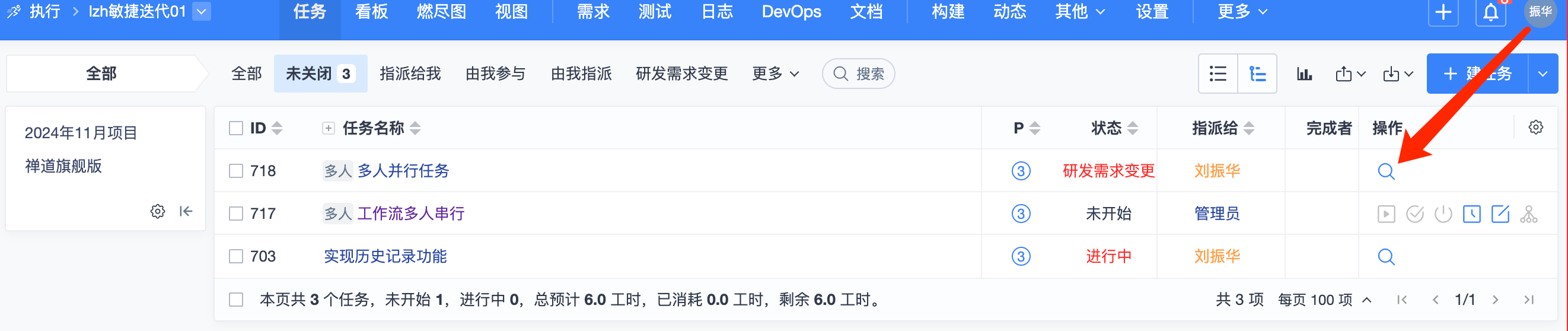
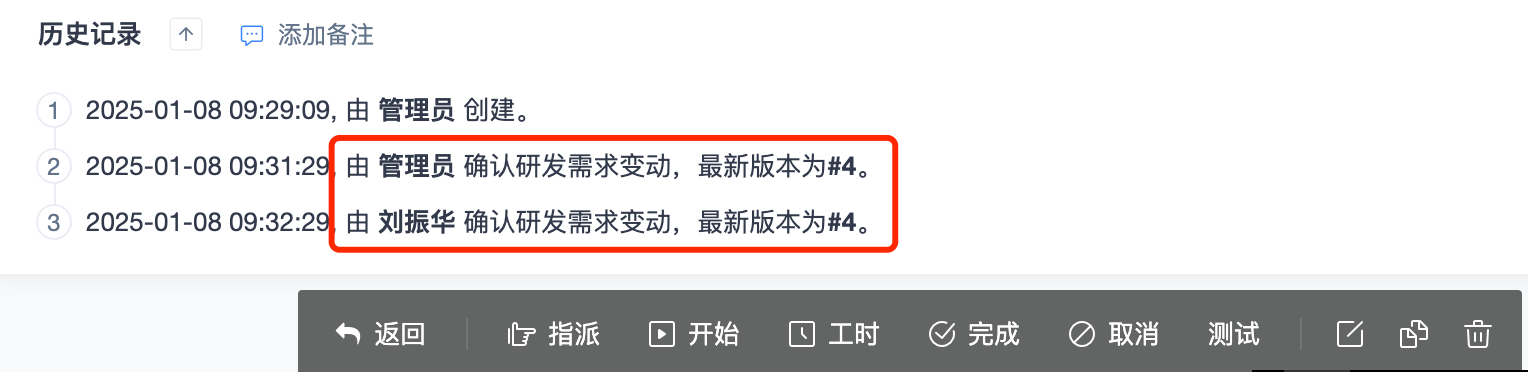
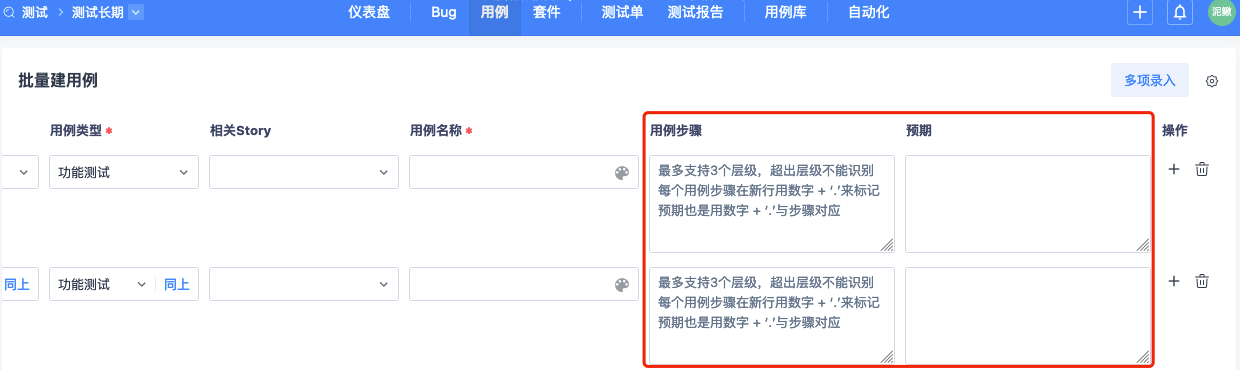
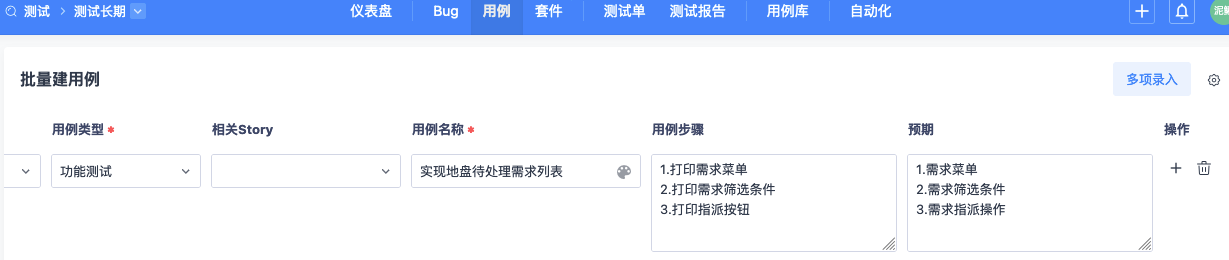
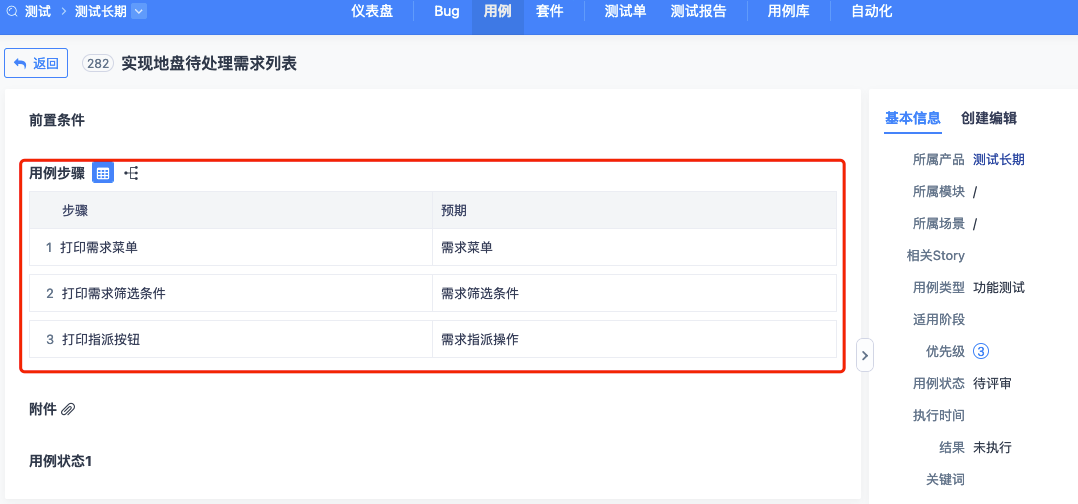
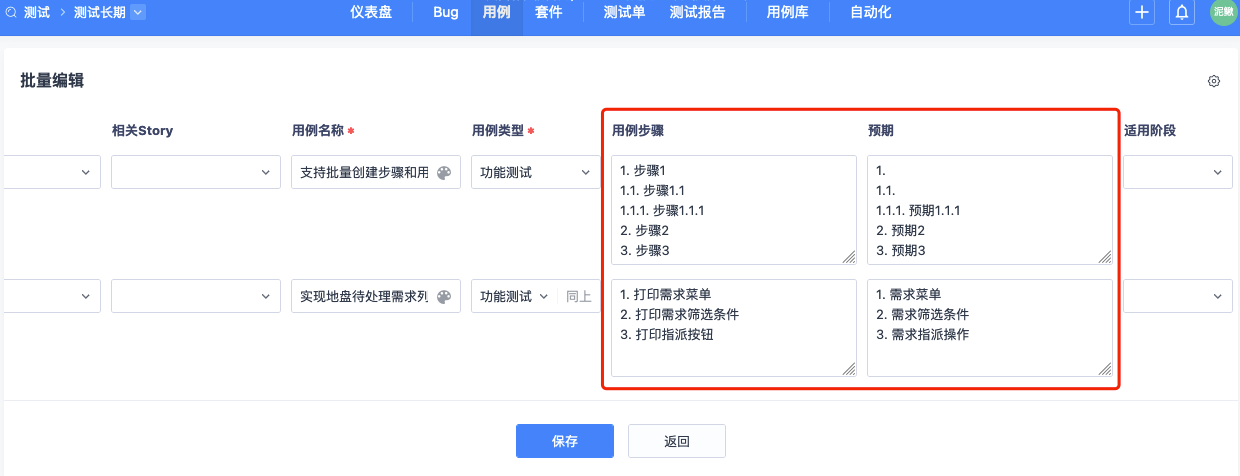
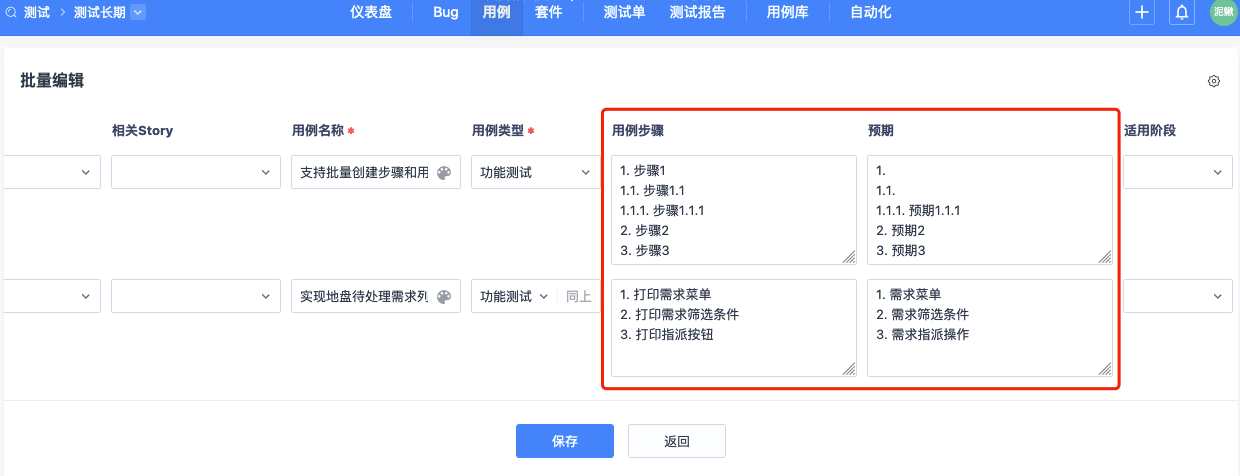
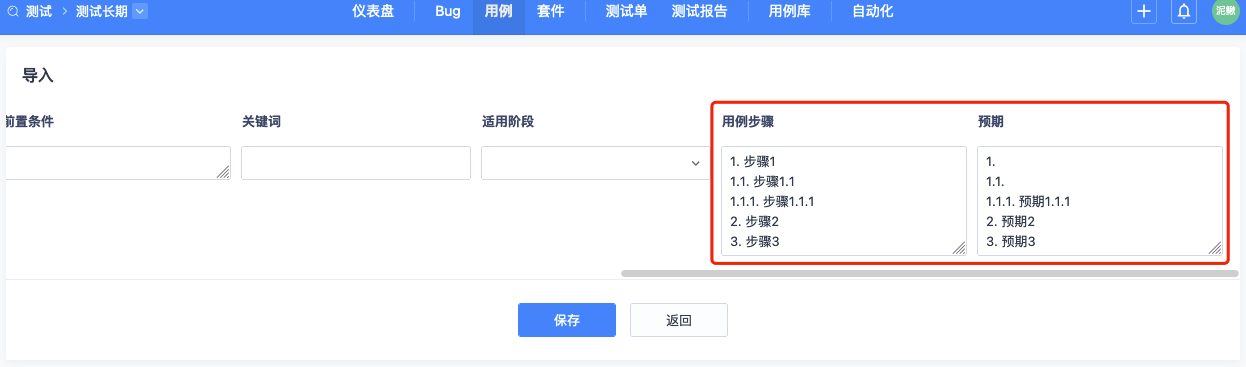
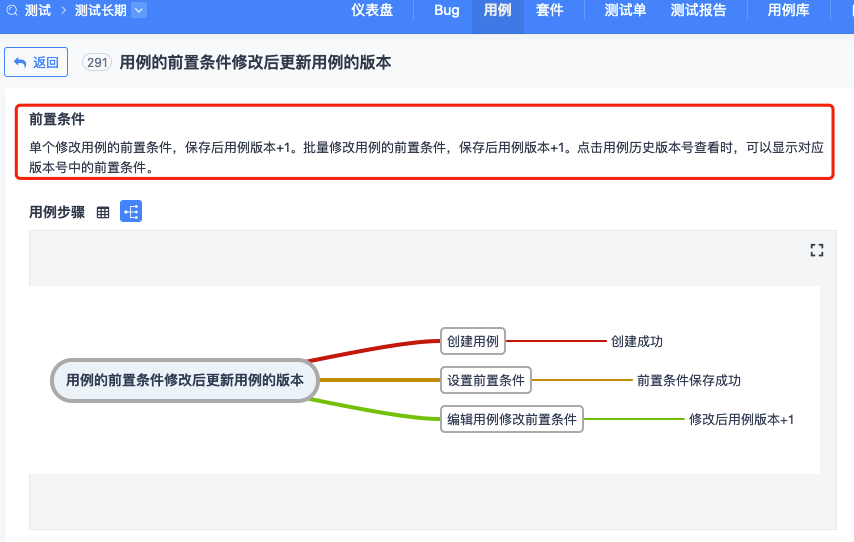
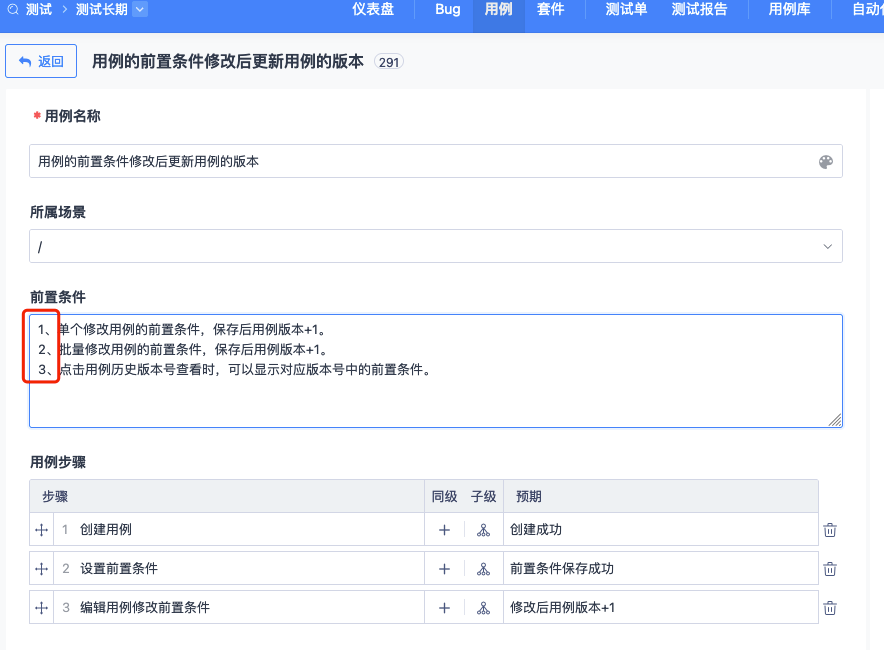



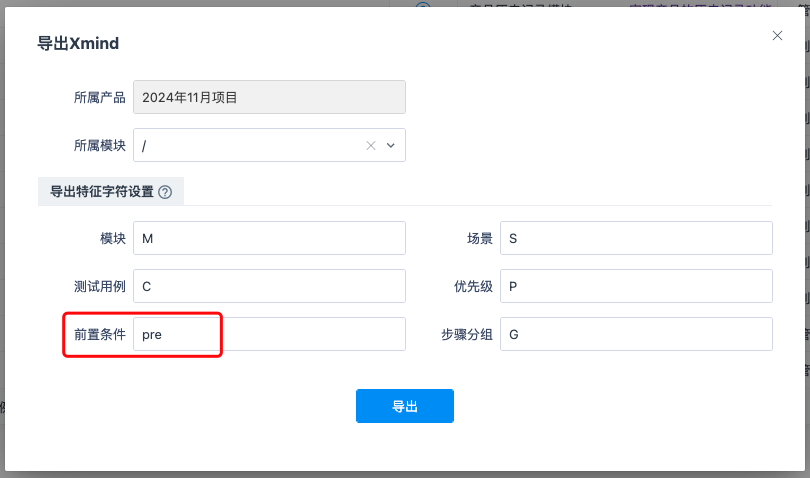
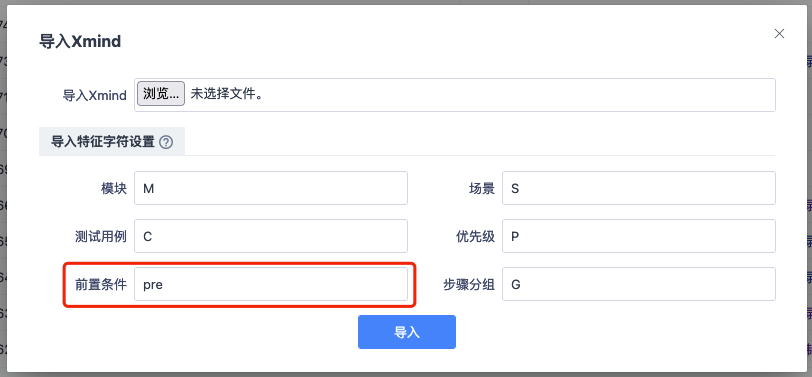

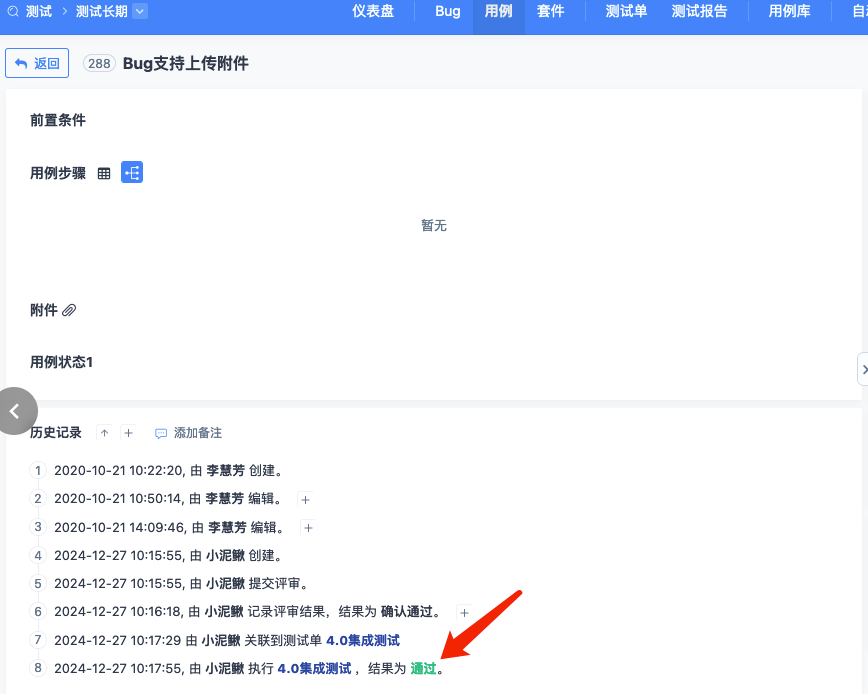
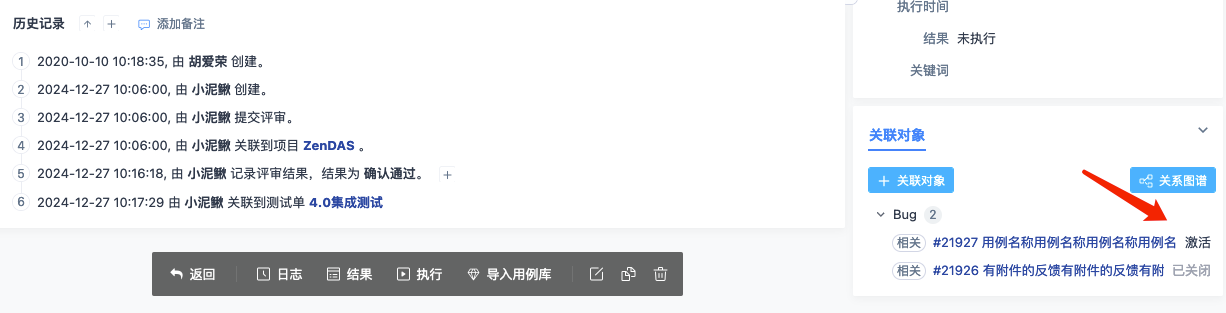
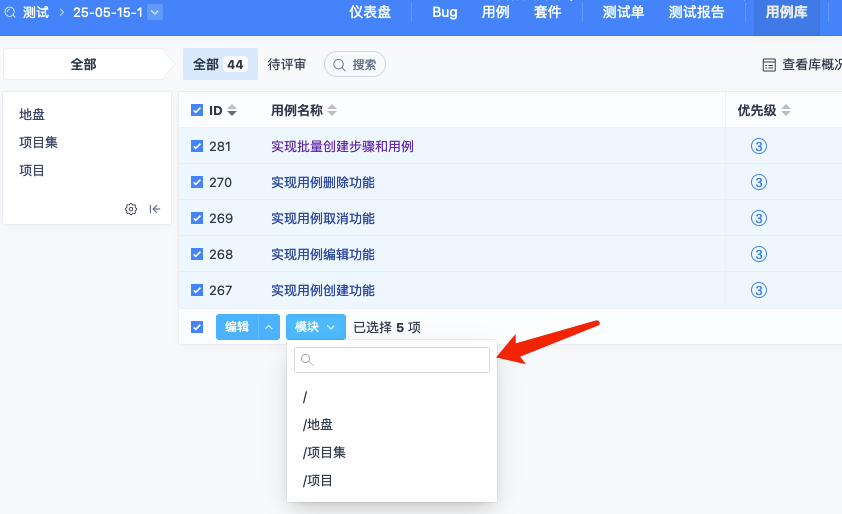
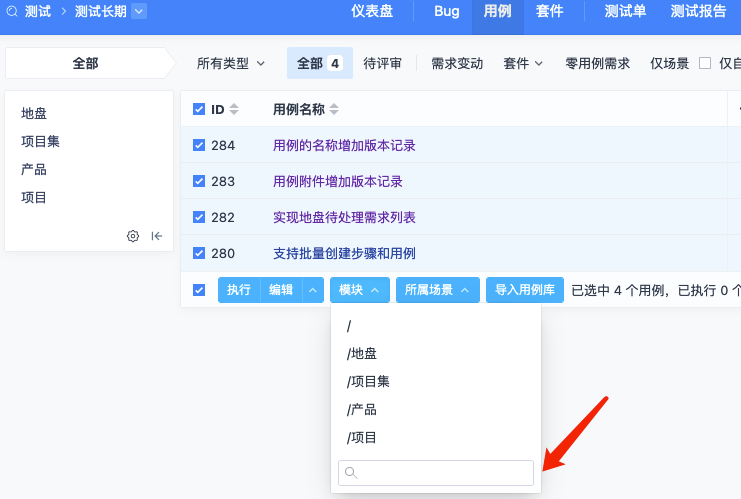
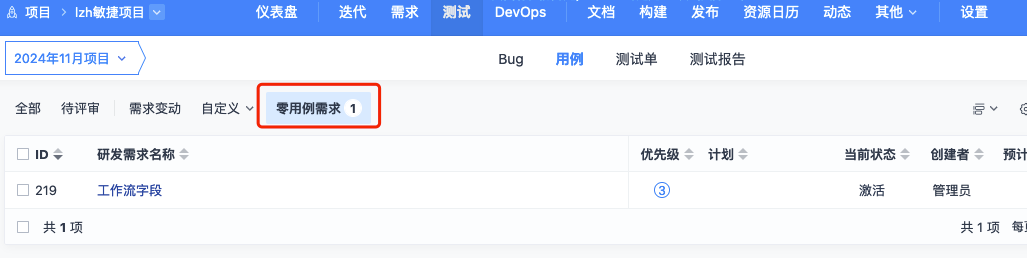
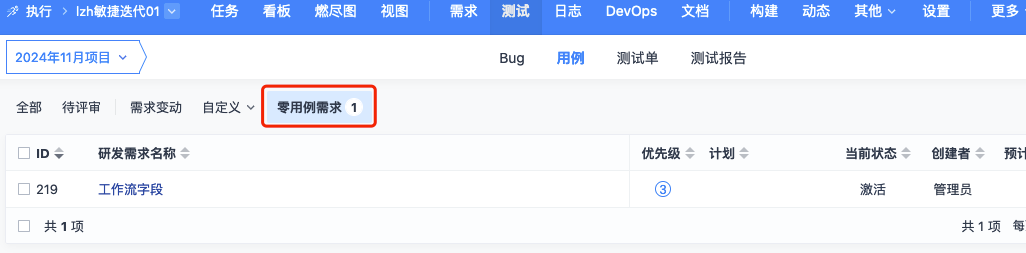
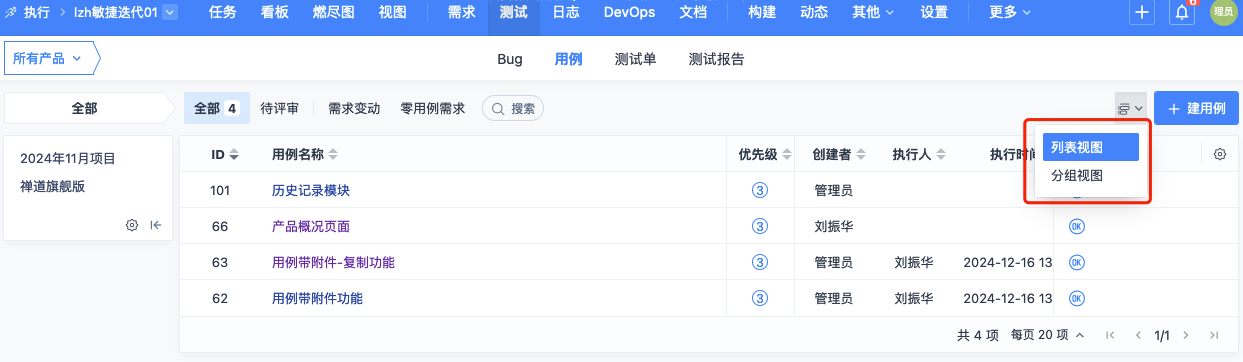
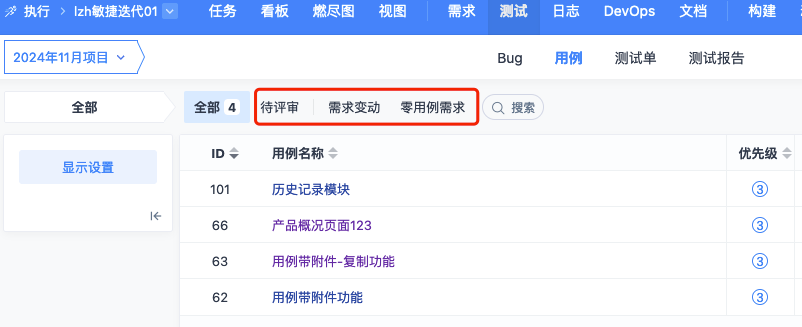
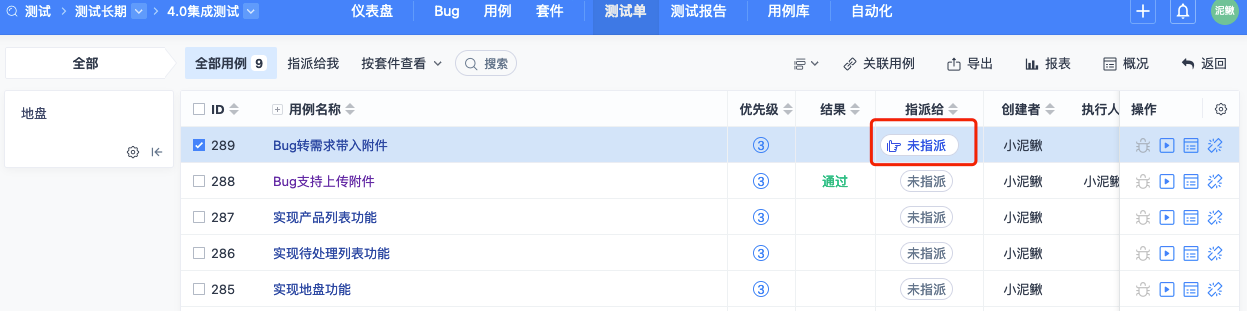

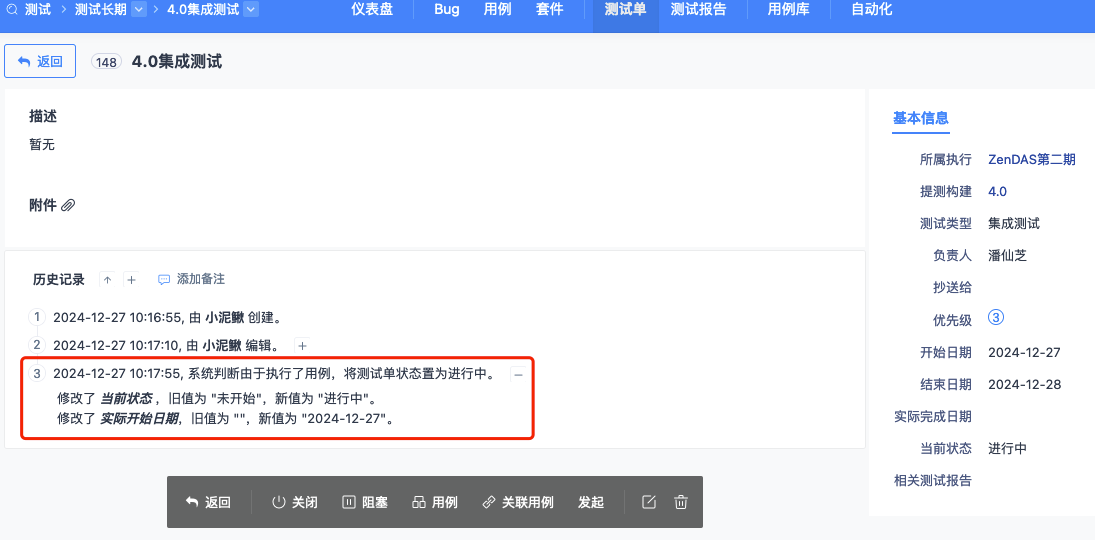
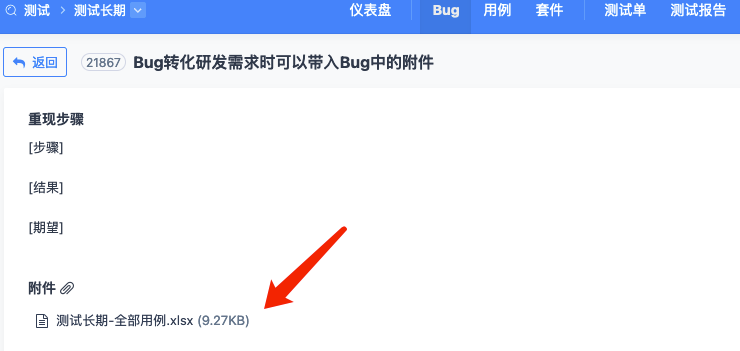
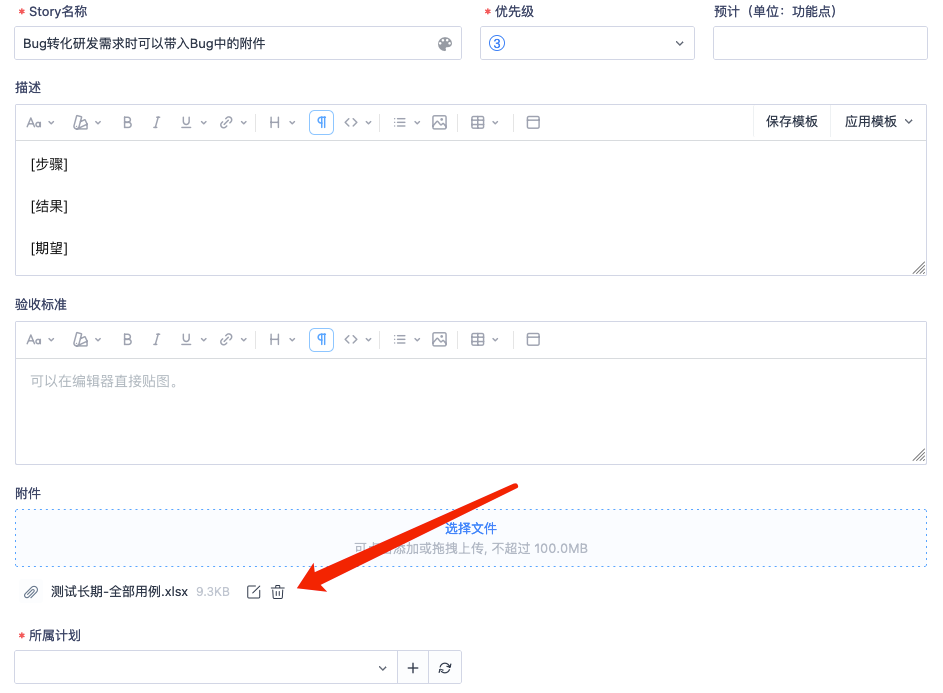
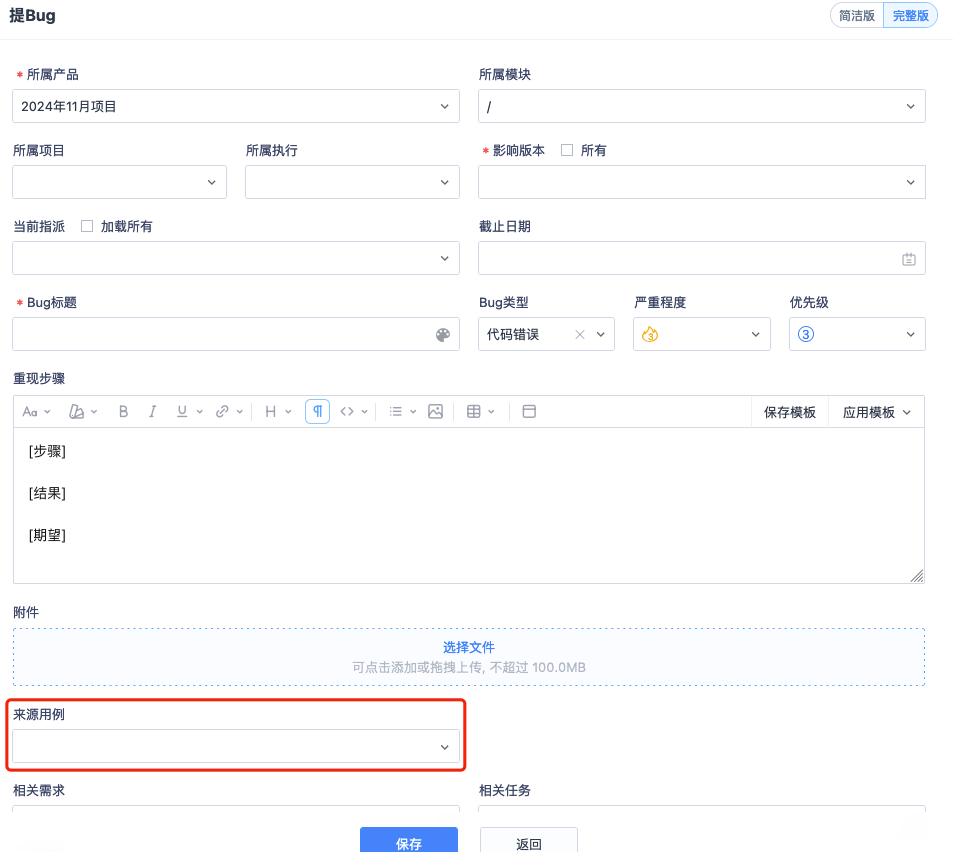

















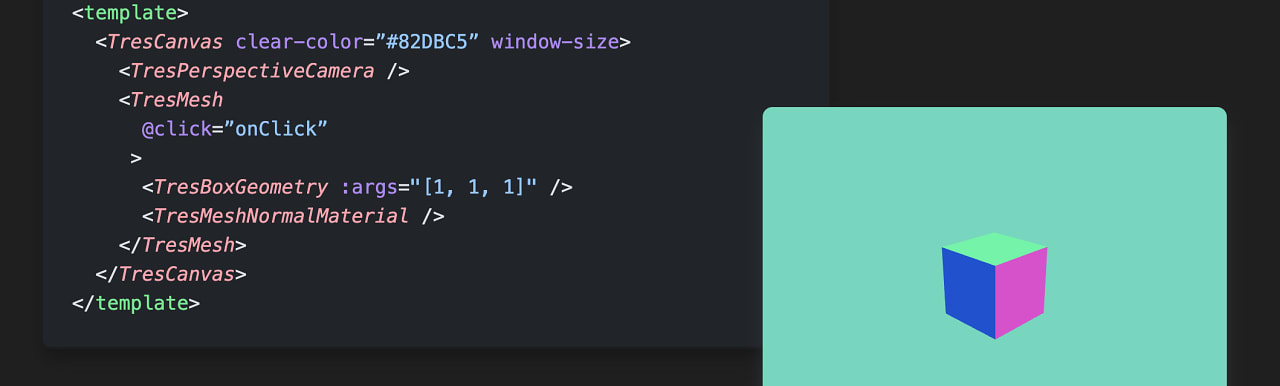











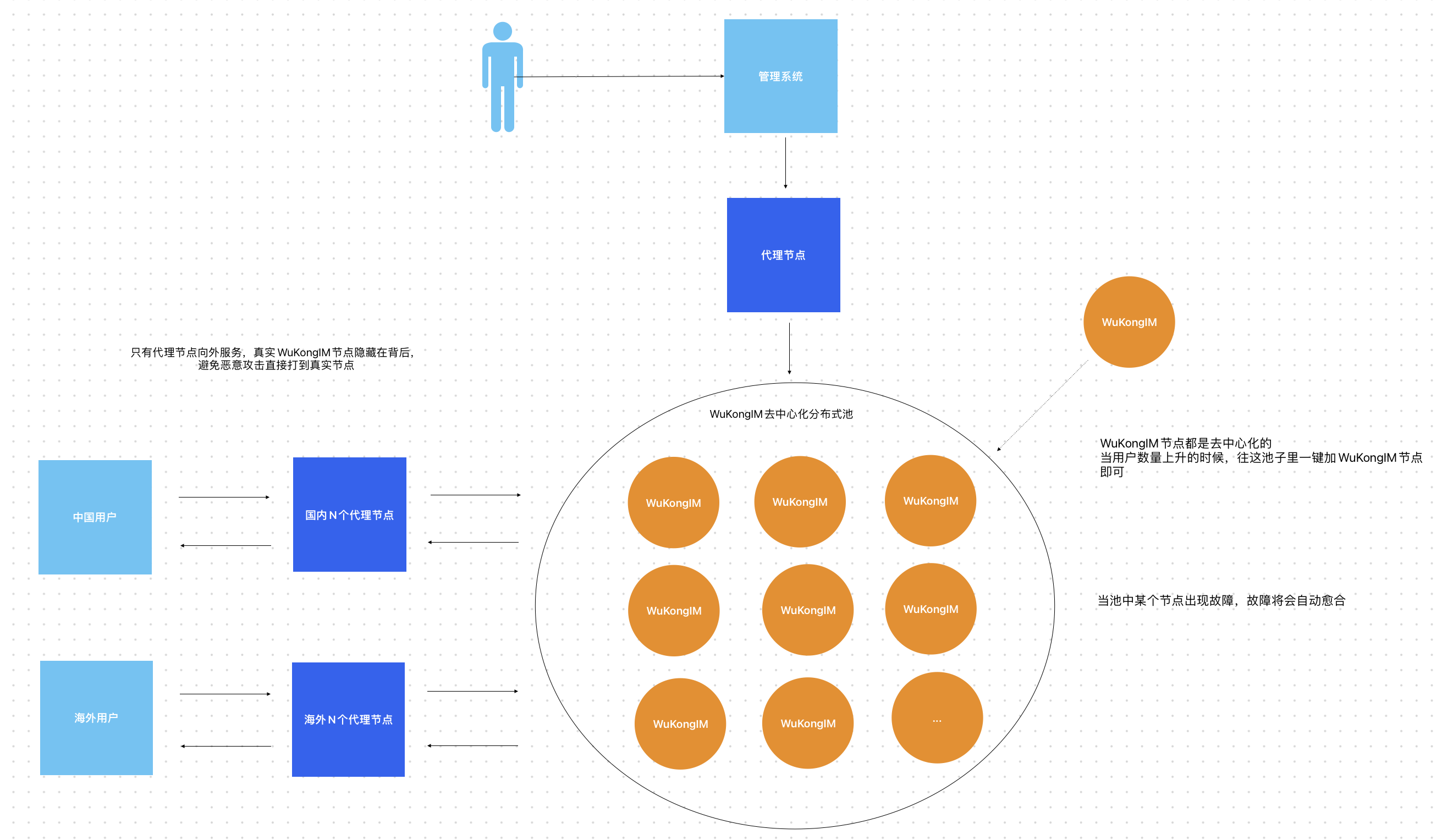
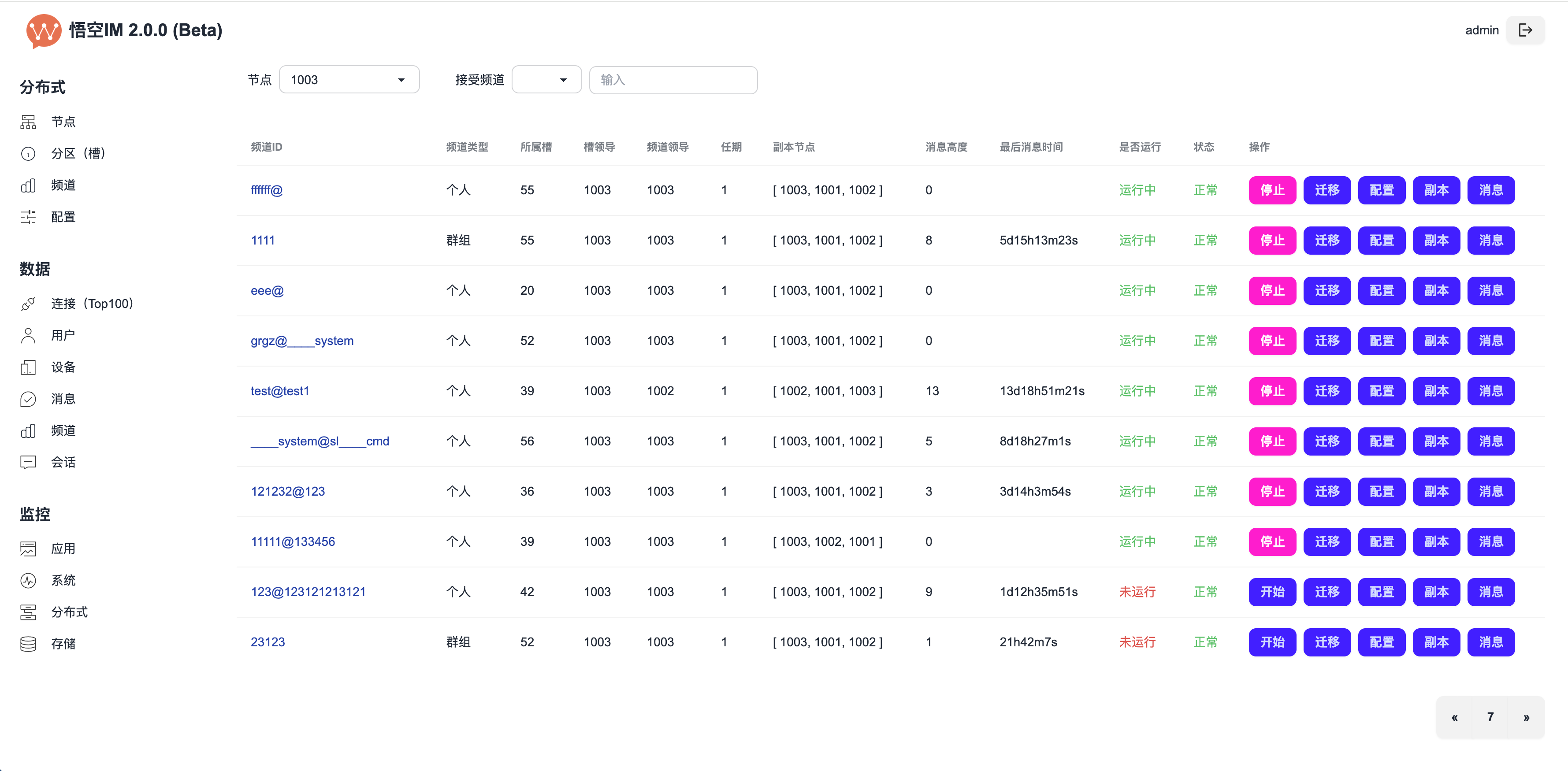










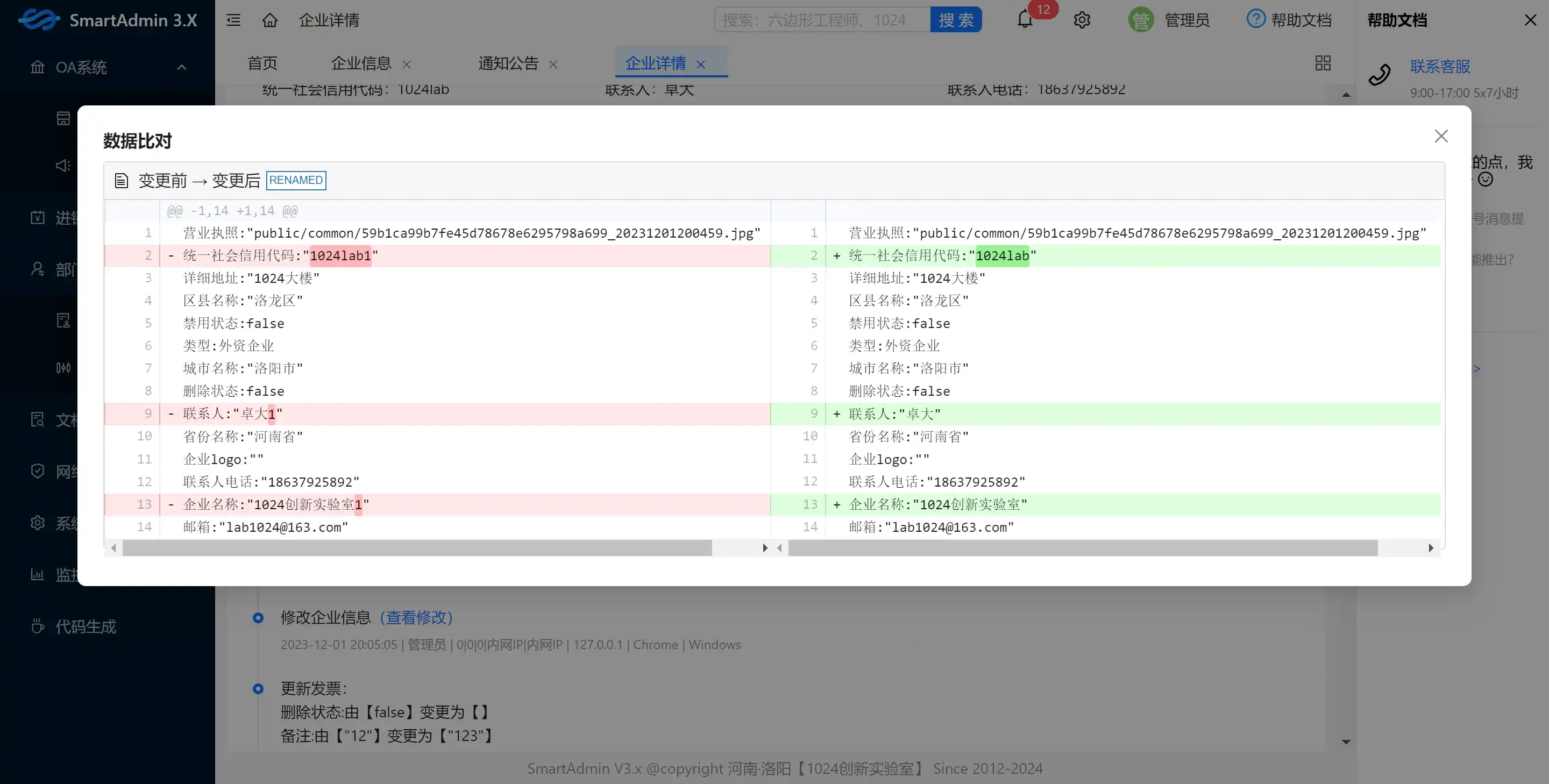







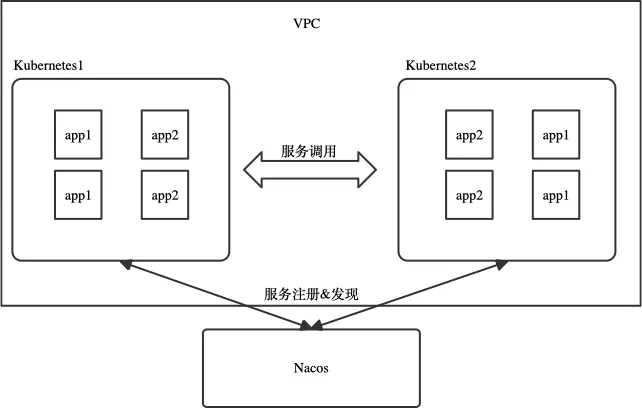




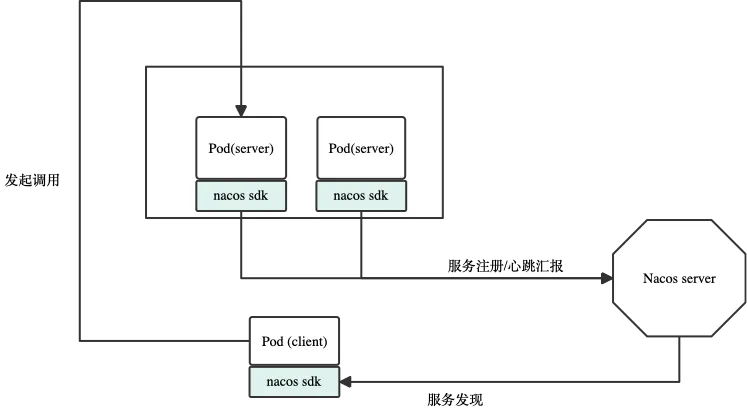
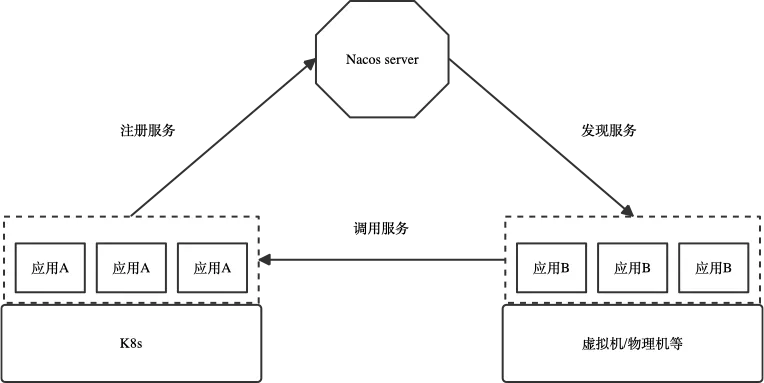






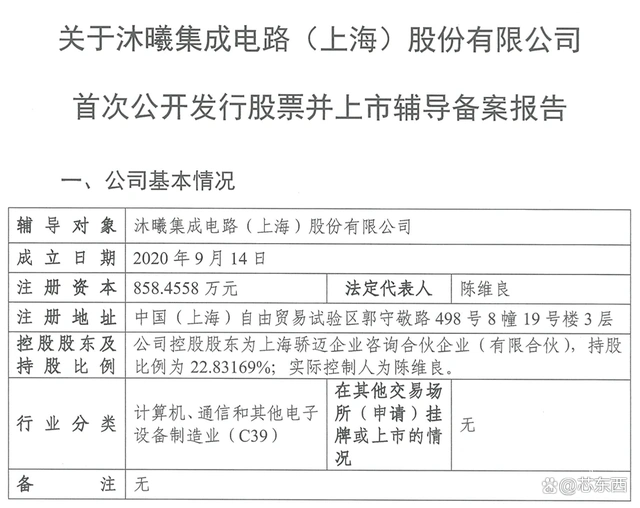
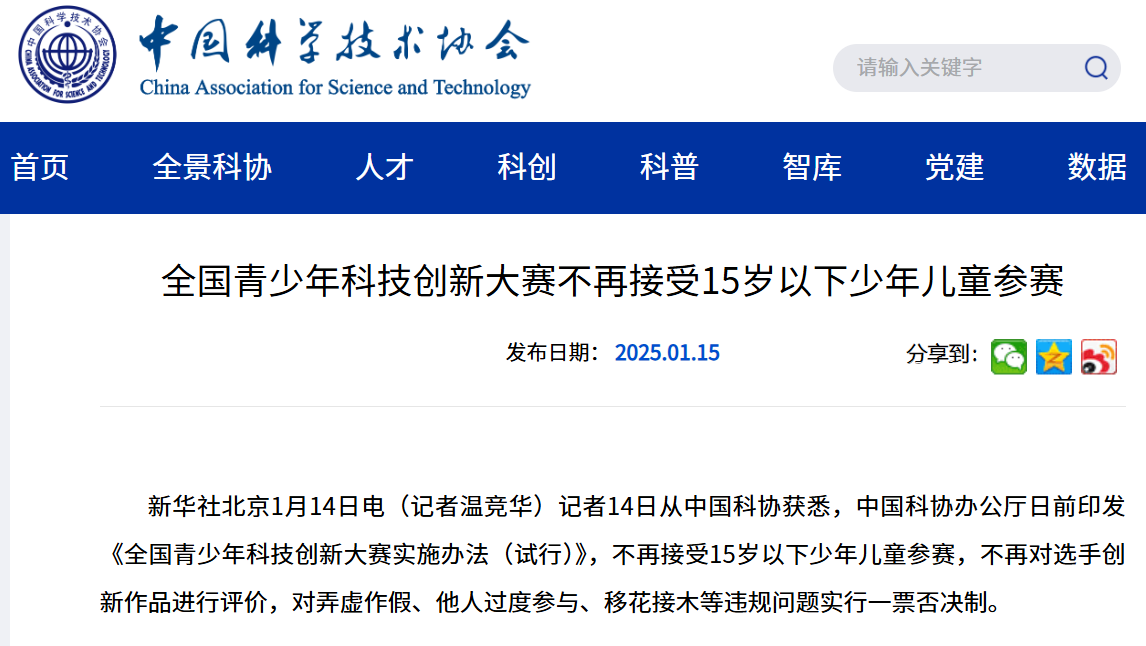






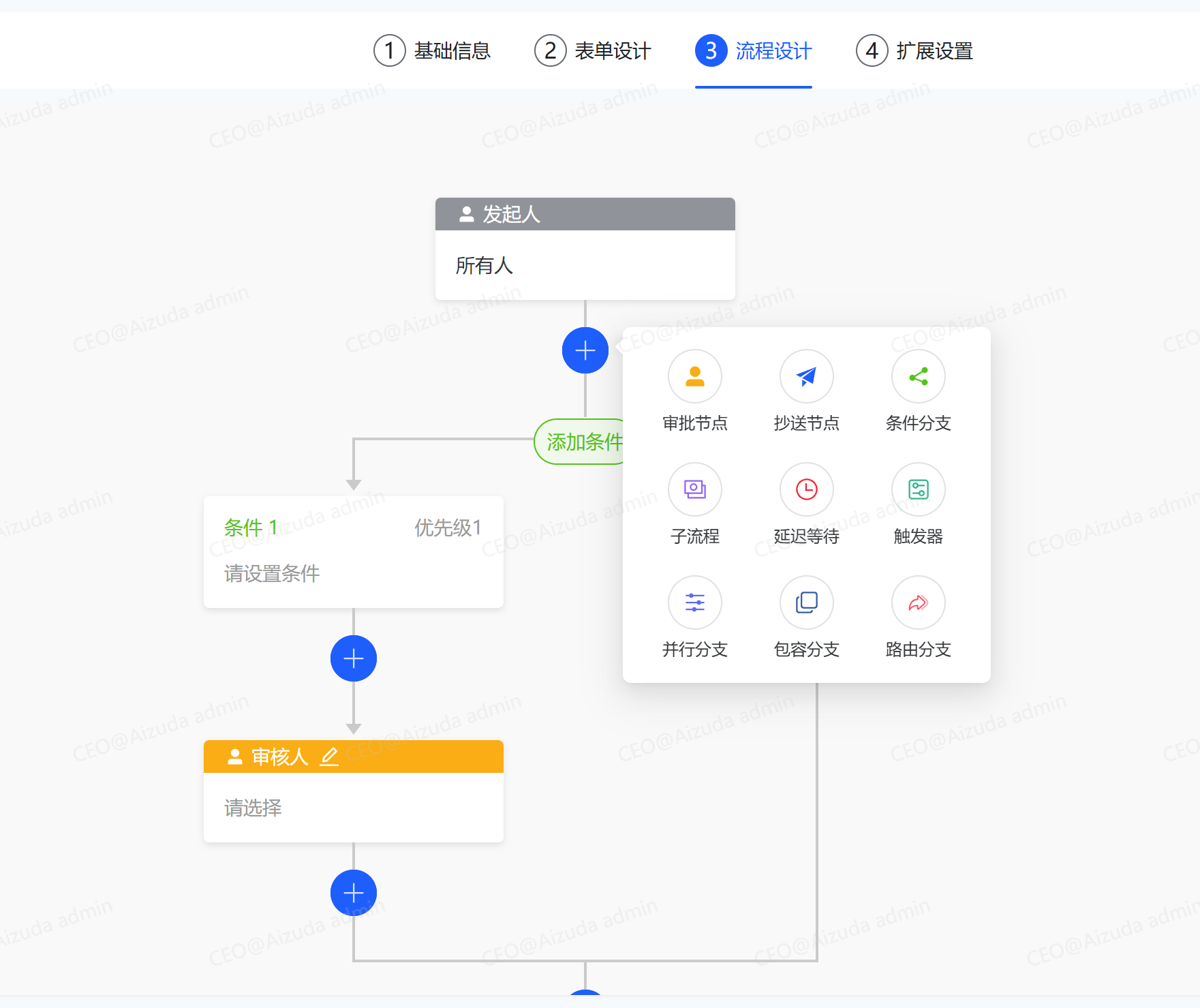
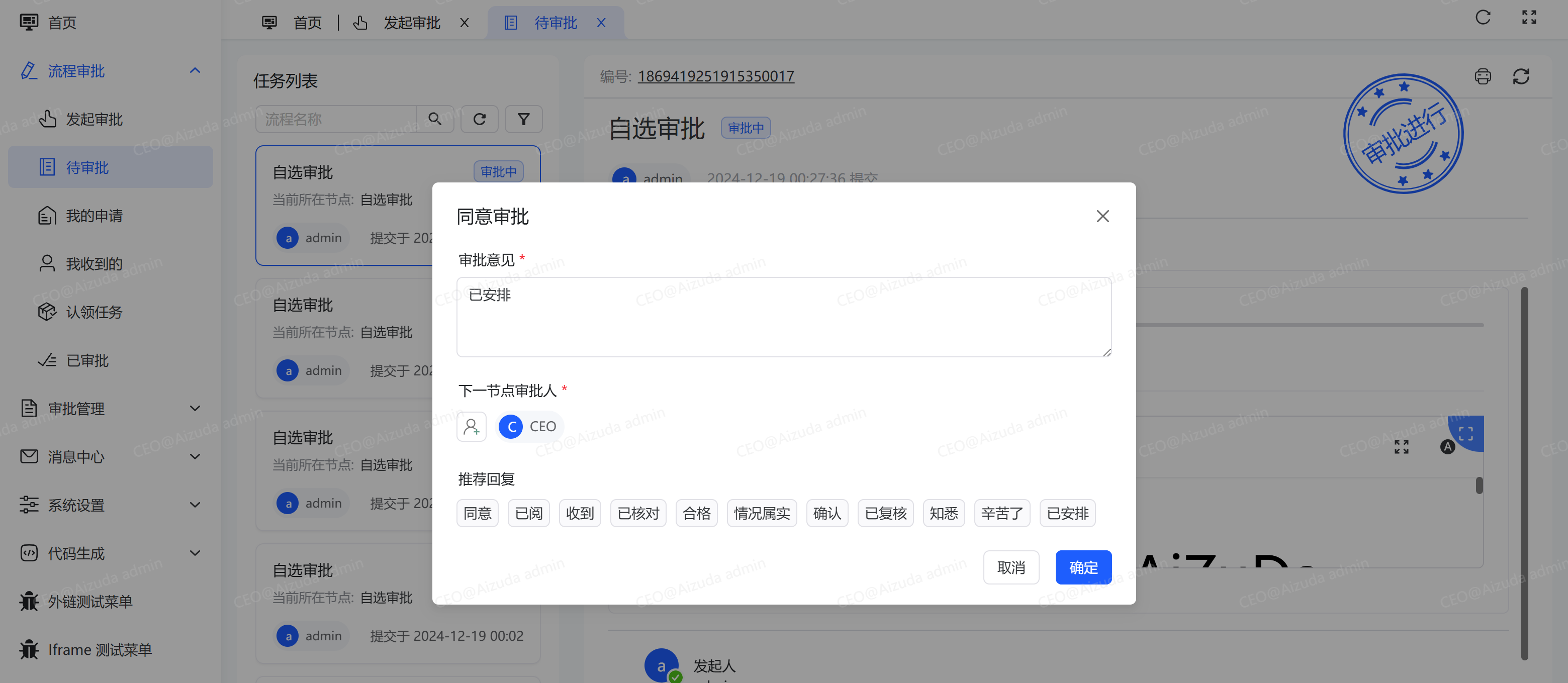
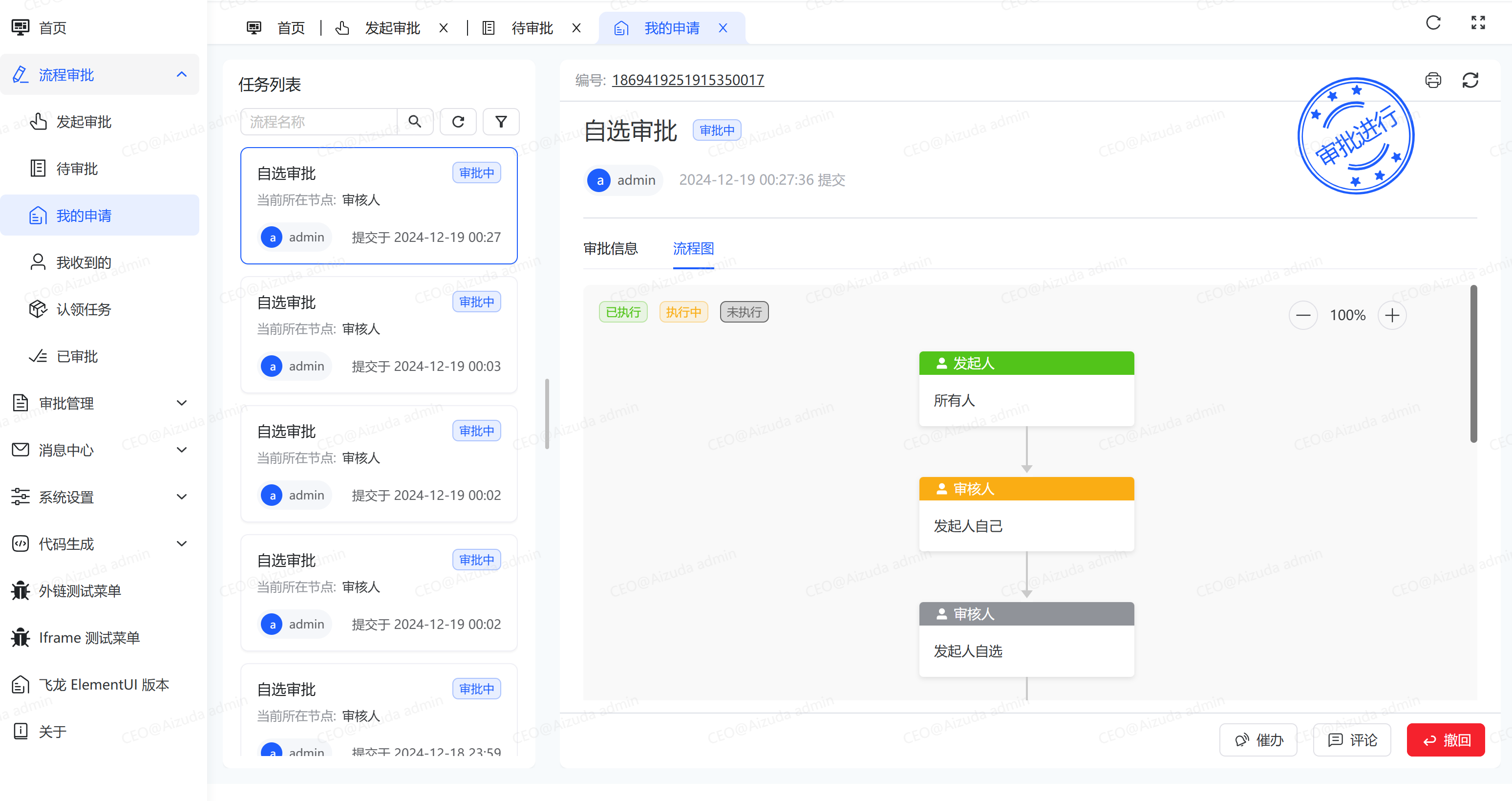


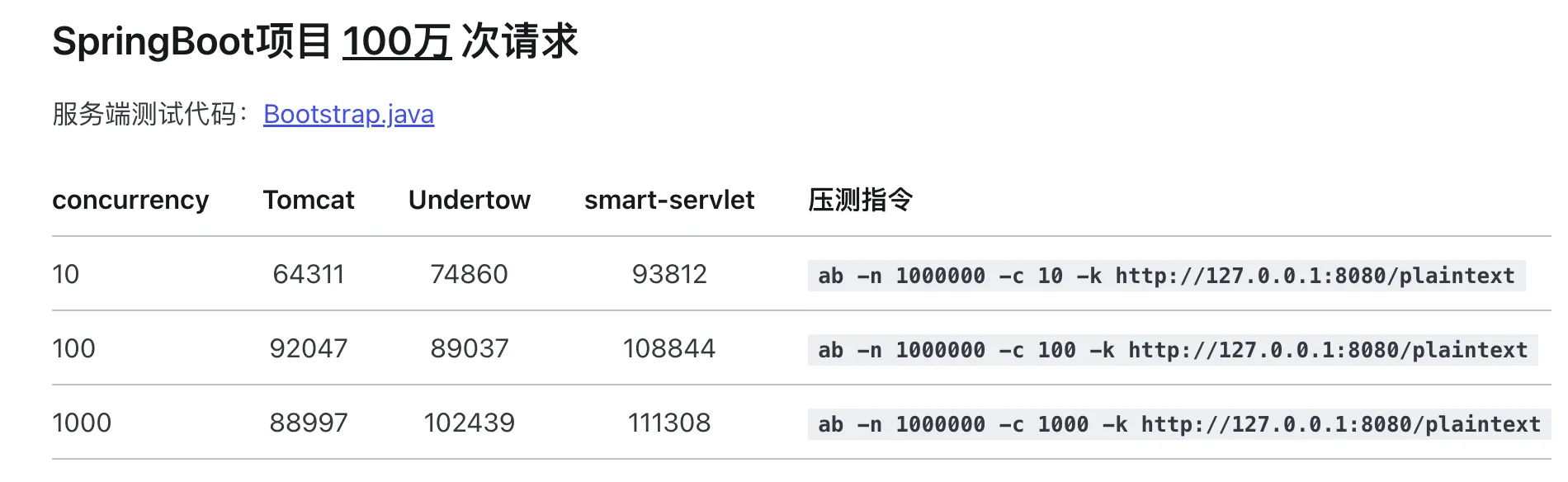
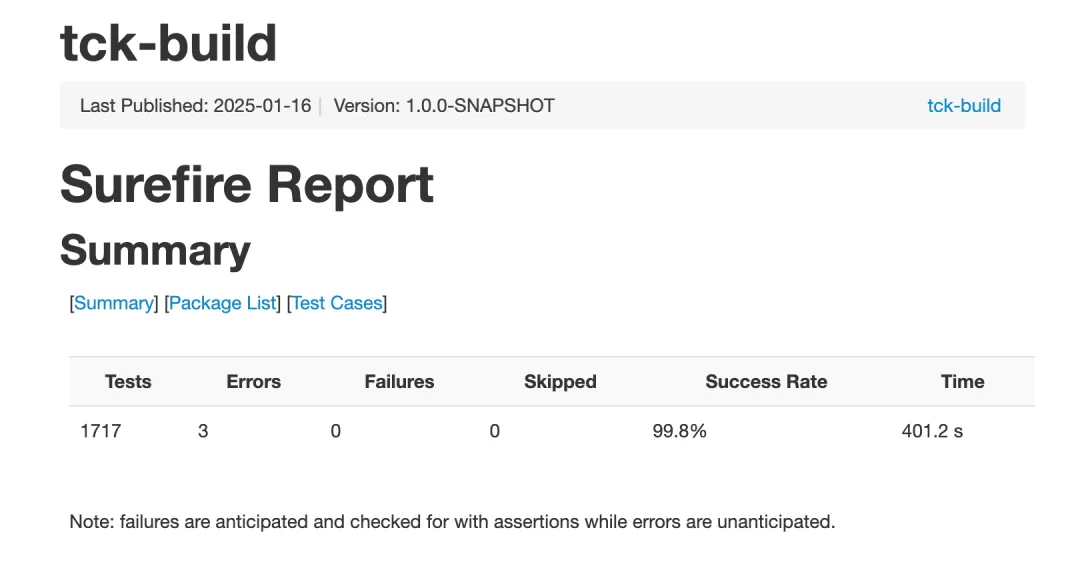





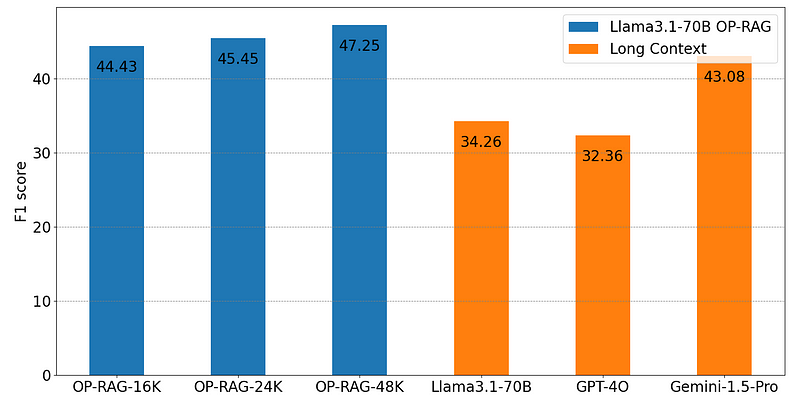








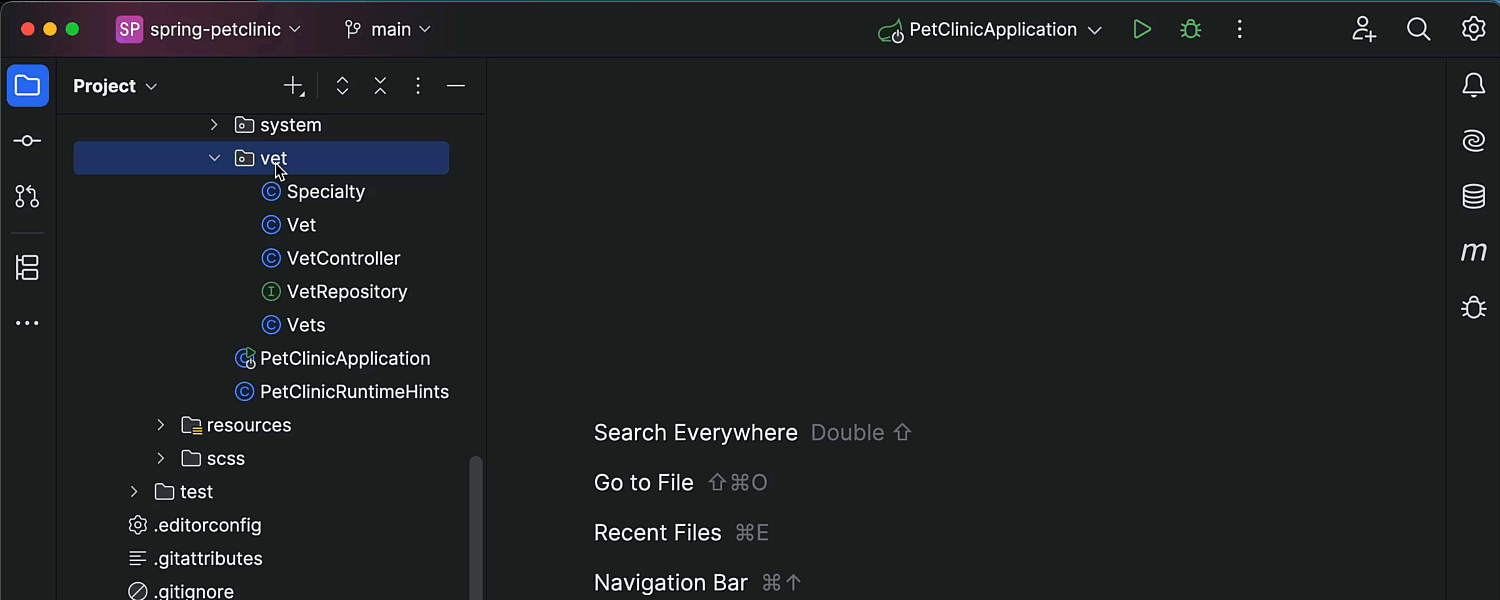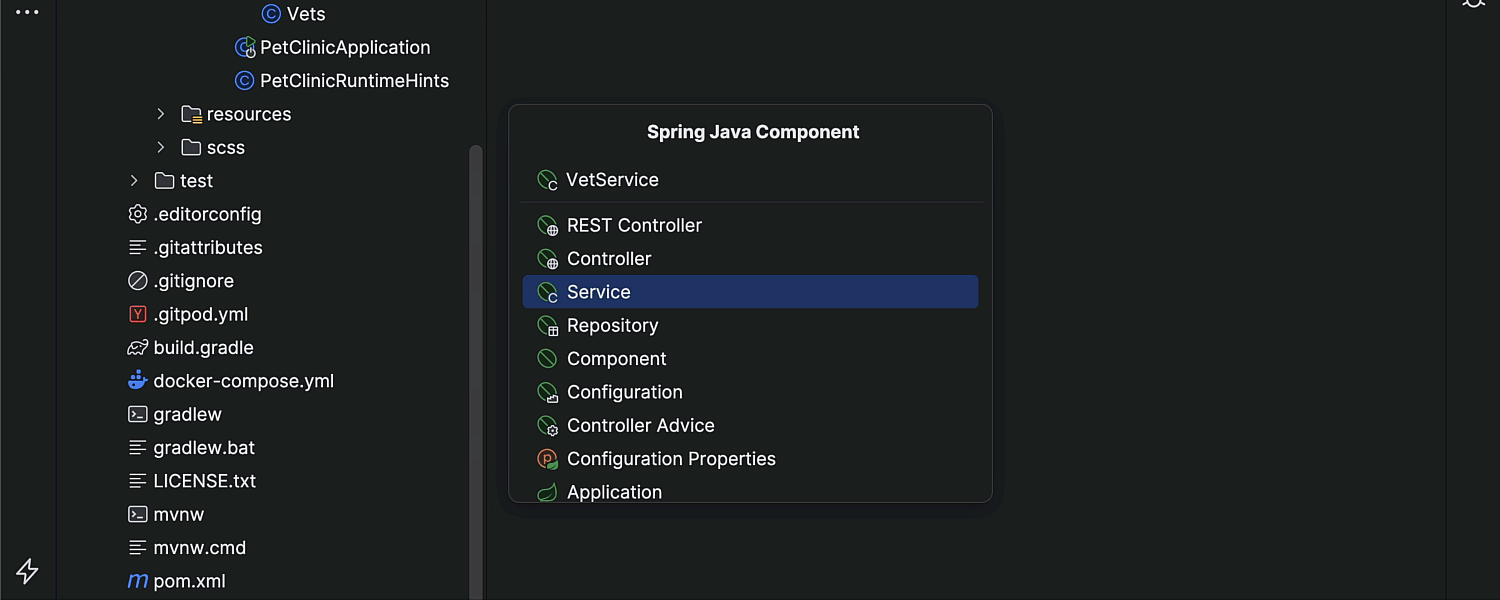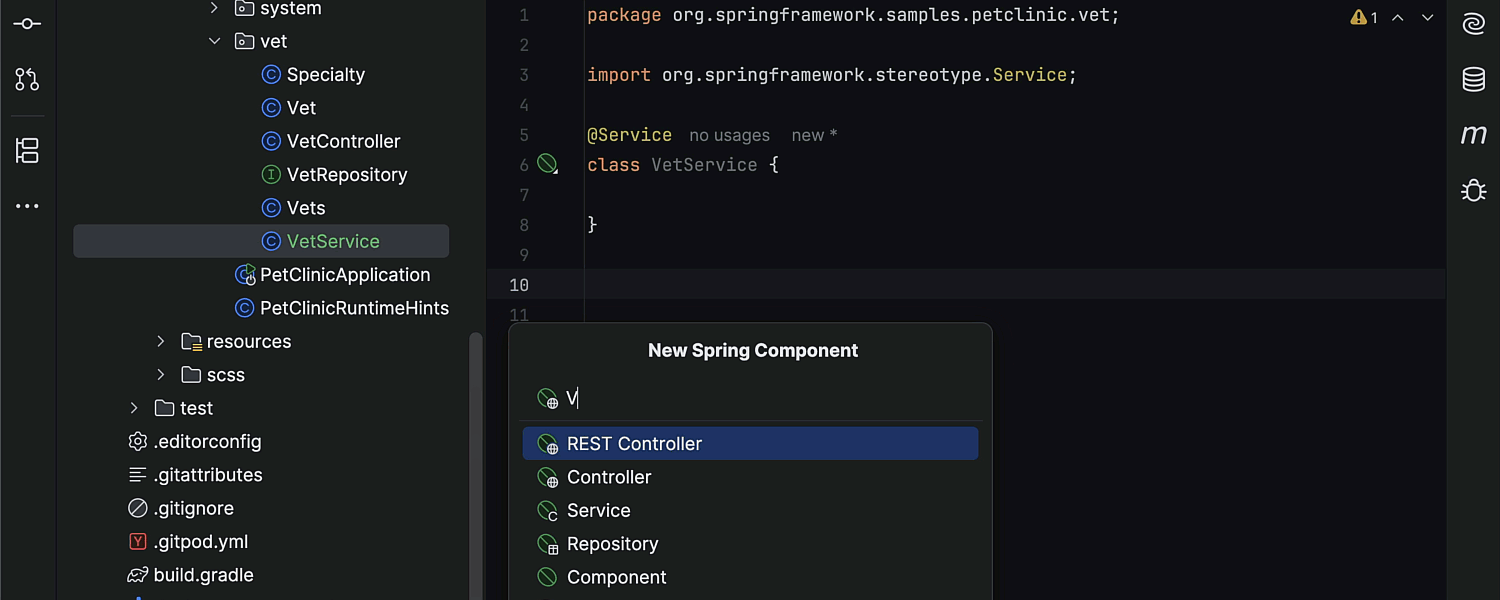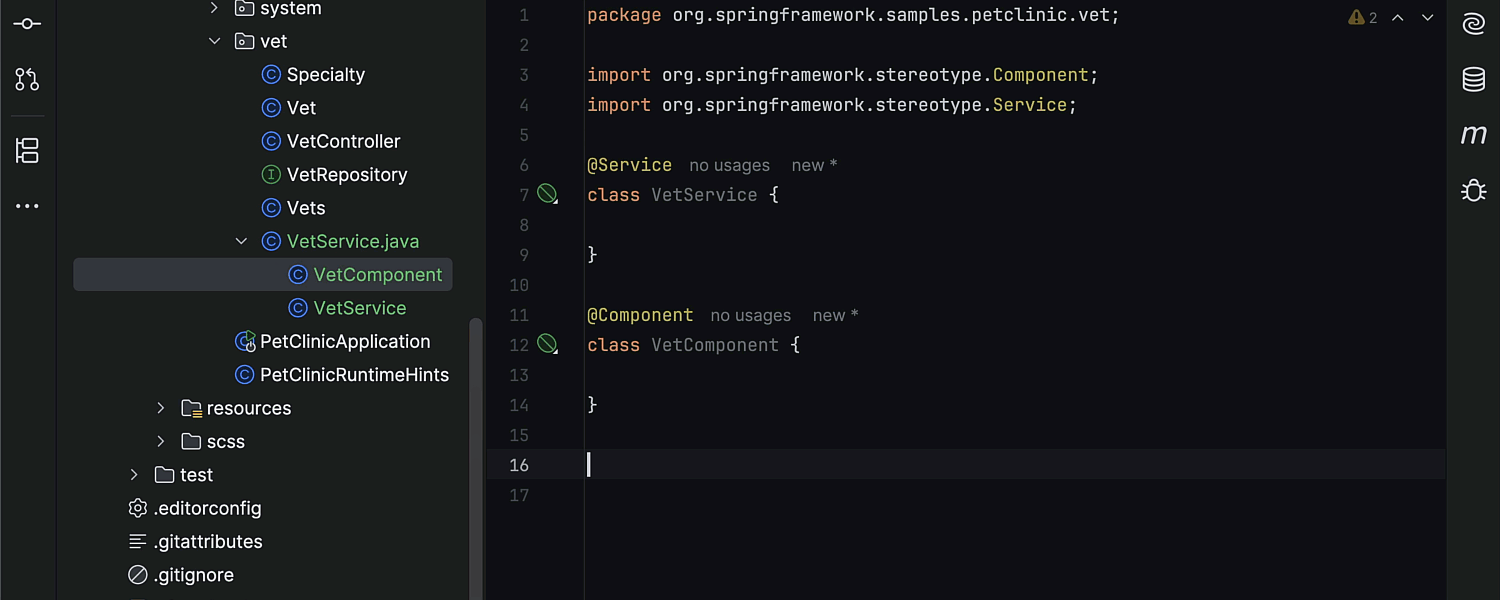



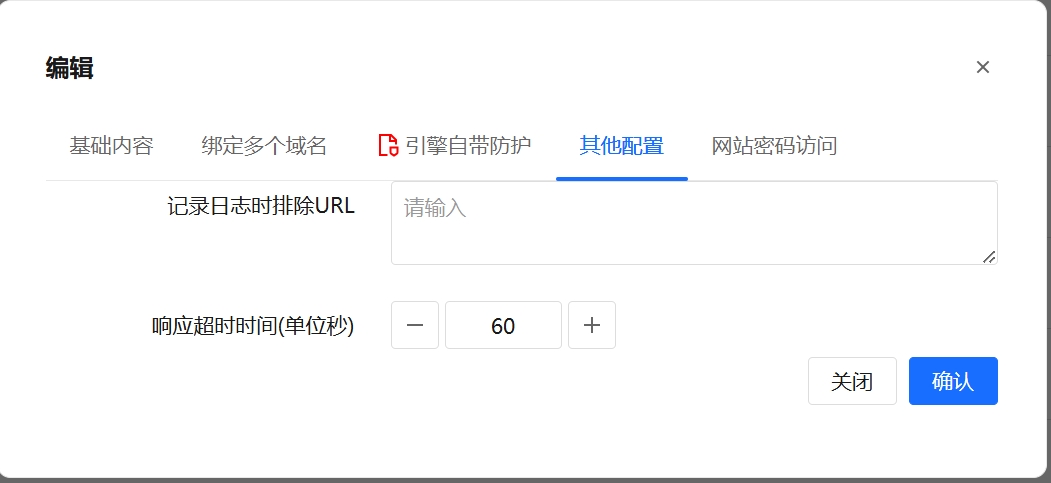
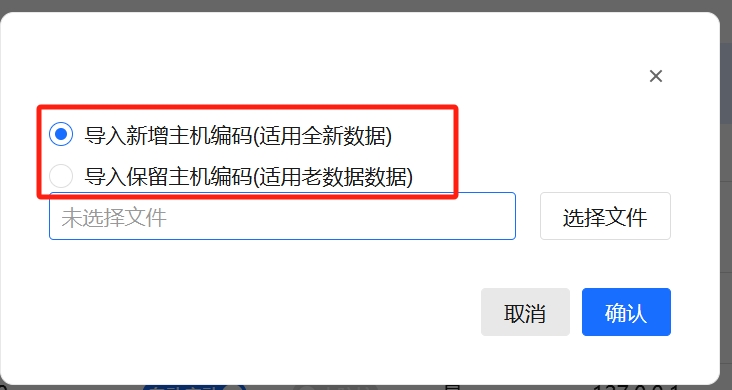


 各种模型格式转为 ONNX,跑在各式各样的设备上
各种模型格式转为 ONNX,跑在各式各样的设备上 IOPaint 本地运行各类图片编辑模型
IOPaint 本地运行各类图片编辑模型





























































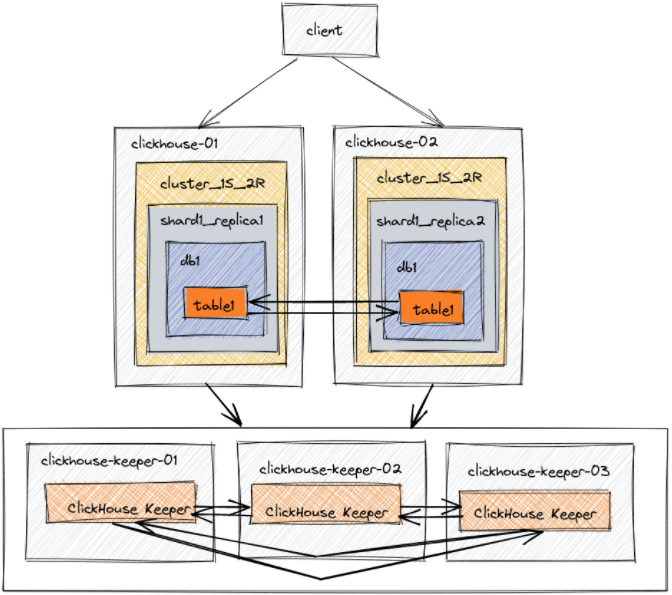
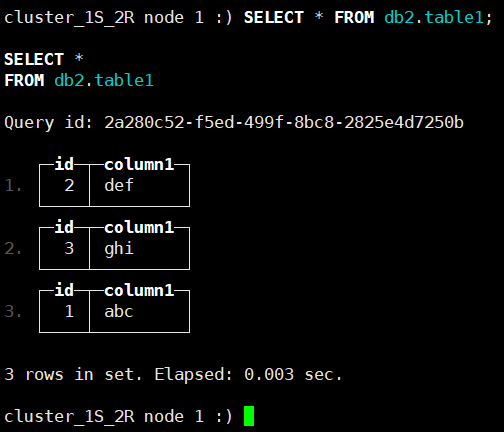










 能,但还比较勉强。
能,但还比较勉强。